Данные экосенсоров
Sensor.Community — это глобальная сеть датчиков, управляемая участниками, которая создает открытые экологические данные. Данные собираются с помощью датчиков по всему миру. Любой желающий может приобрести датчик и установить его в любом месте. API для загрузки данных находятся на GitHub, а данные доступны бесплатно в соответствии с Лицензией на Содержимое Базы Данных (DbCL).
Набор данных содержит более 20 миллиардов записей, поэтому будьте осторожны с копированием и вставкой команд ниже, если ваши ресурсы не способны справиться с таким объемом. Команды ниже были выполнены на Production экземпляре ClickHouse Cloud.
- Данные находятся в S3, поэтому мы можем использовать табличную функцию
s3, чтобы создать таблицу из файлов. Мы также можем выполнять запросы к данным на месте. Давайте посмотрим на несколько строк перед тем, как пытаться вставить их в ClickHouse:
Данные находятся в CSV файлах, но в качестве разделителя используется точка с запятой. Строки выглядят следующим образом:
- Мы будем использовать следующую таблицу
MergeTree, чтобы хранить данные в ClickHouse:
- У ClickHouse Cloud есть кластер с именем
default. Мы будем использовать табличную функциюs3Cluster, которая считывает файлы S3 параллельно с узлов вашей кластера. (Если у вас нет кластера, просто используйте функциюs3и уберите имя кластера.)
Этот запрос займет некоторое время — это примерно 1.67 ТБ данных в не сжатом виде:
Вот ответ — показывающий количество строк и скорость обработки. Данных вводится более 6 миллионов строк в секунду!
- Давайте посмотрим, сколько место на диске потребуется для таблицы
sensors:
1.67 ТБ сжимаются до 310 GiB, и там 20.69 миллиардов строк:
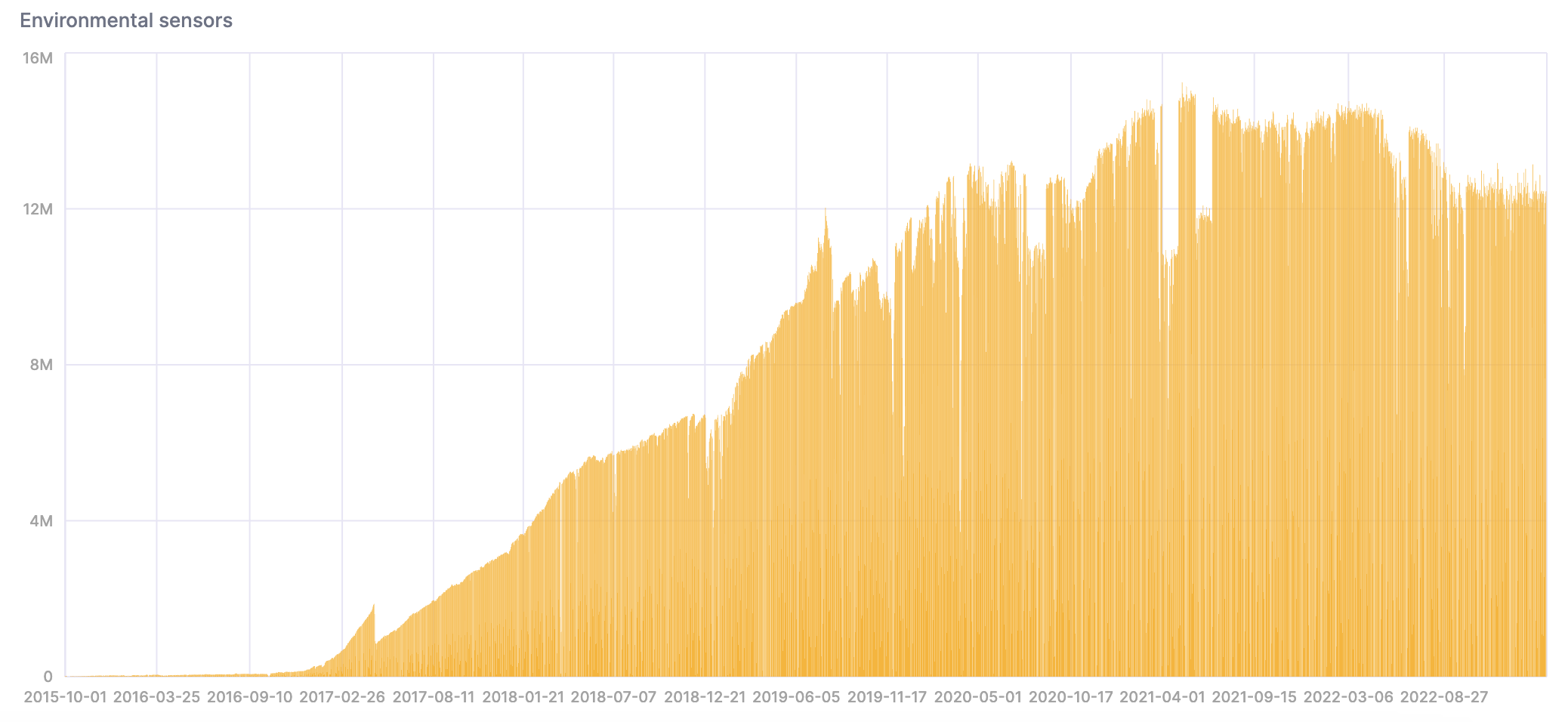
- Давайте проанализируем данные сейчас, когда они находятся в ClickHouse. Обратите внимание, что количество данных увеличивается со временем по мере развертывания новых датчиков:
Мы можем создать график в SQL Консоли, чтобы визуализировать результаты:
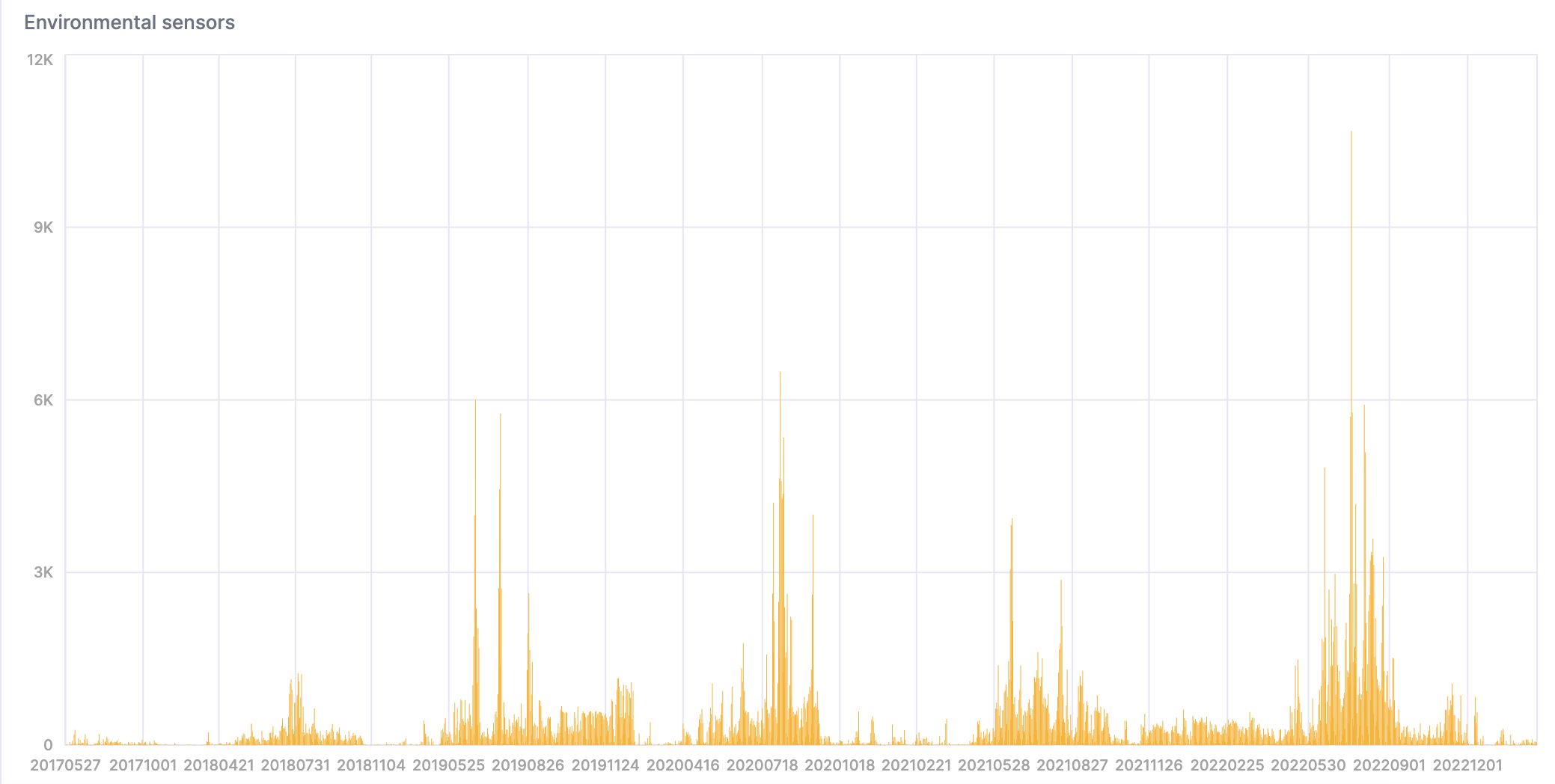
- Этот запрос считает количество слишком горячих и влажных дней:
Вот визуализация результата: