Практическое введение в первичные индексы в ClickHouse
Введение
В этом руководстве мы подробно рассмотрим индексацию в ClickHouse. Мы проиллюстрируем и обсудим в деталях:
- как индексация в ClickHouse отличается от традиционных систем управления реляционными базами данных
- как ClickHouse строит и использует разреженный первичный индекс таблицы
- какие лучшие практики существуют для индексации в ClickHouse
Вы можете по желанию выполнить все SQL-запросы и команды ClickHouse, приведенные в этом руководстве, на своем собственном компьютере. Для установки ClickHouse и инструкций по началу работы, смотрите Быстрый старт.
Это руководство сосредоточено на разреженных первичных индексах ClickHouse.
Для вторичных индексов пропуска данных ClickHouse, смотрите Учебное пособие.
Набор данных
На протяжении этого руководства мы будем использовать набор данных анонимизированного веб-трафика.
- Мы будем использовать подмножество из 8,87 миллиона строк (событий) из образца данных.
- Не сжатый размер данных составляет 8,87 миллиона событий и около 700 MB. При хранении в ClickHouse он сжимается до 200 MB.
- В нашем подмножестве каждая строка содержит три колонки, которые указывают на интернет-пользователя (колонка
UserID), который кликнул по URL (колонкаURL) в определенное время (колонкаEventTime).
С этими тремя колонками мы уже можем сформулировать некоторые типичные запросы веб-аналитики, такие как:
- "Какие 10 URL были наиболее часто кликаемы для конкретного пользователя?"
- "Какие 10 пользователей чаще всего кликали по конкретному URL?"
- "В какое время (например, дни недели) пользователь чаще всего кликает по конкретному URL?"
Тестовая машина
Все временные величины, указанные в этом документе, основаны на работе ClickHouse 22.2.1 локально на MacBook Pro с процессором Apple M1 Pro и 16 ГБ ОЗУ.
Полное сканирование таблицы
Чтобы увидеть, как выполняется запрос по нашему набору данных без первичного ключа, мы создаем таблицу (с движком таблицы MergeTree), выполняя следующее DDL-утверждение:
Следующим шагом вставляем подмножество данных о кликах в таблицу с помощью следующего SQL-утверждения insert. Это использует табличную функцию URL, чтобы загрузить подмножество полного набора данных, размещенного удаленно на clickhouse.com:
Ответ выглядит следующим образом:
Результат, выведенный клиентом ClickHouse, показывает, что данное утверждение вставило в таблицу 8,87 миллиона строк.
Наконец, чтобы упростить обсуждение в дальнейшем в данном руководстве и сделать диаграммы и результаты воспроизводимыми, мы оптимизируем таблицу, используя ключевое слово FINAL:
В общем, не требуется и не рекомендуется немедленно оптимизировать таблицу после загрузки в нее данных. Почему это необходимо для этого примера станет очевидным.
Теперь мы выполняем наш первый запрос веб-аналитики. Следующий запрос вычисляет 10 наиболее кликаемых URL для интернет-пользователя с UserID 749927693:
Ответ выглядит следующим образом:
Вывод результата клиента ClickHouse указывает на то, что ClickHouse выполнил полное сканирование таблицы! Каждая отдельная строка из 8,87 миллиона строк нашей таблицы была загружена в ClickHouse. Это масштабируемо не работает.
Чтобы сделать это (значительно) более эффективным и (значительно) быстрее, нам нужно использовать таблицу с соответствующим первичным ключом. Это позволит ClickHouse автоматически (на основе колонок первичного ключа) создать разреженный первичный индекс, который затем можно использовать для значительного ускорения выполнения нашего примера запроса.
Проектирование индексов в ClickHouse
Проектирование индекса для больших объемов данных
В традиционных системах управления реляционными базами данных первичный индекс будет содержать одну запись на каждую строку таблицы. В результате первичный индекс будет содержать 8,87 миллиона записей для нашего набора данных. Такой индекс позволяет быстро находить конкретные строки, что обеспечивает высокую эффективность для запросов поиска и точечных обновлений. Поиск записи в структуре данных B(+)-Tree имеет среднюю временную сложность O(log n); точнее, log_b n = log_2 n / log_2 b, где b — это коэффициент разветвления B(+)-Tree, а n — количество индексированных строк. Поскольку b обычно составляет от нескольких сотен до нескольких тысяч, B(+)-Trees очень мелкие структуры, и для нахождения записей требуется немного обращений к диску. При 8,87 миллиона строк и коэффициенте разветвления 1000 требуется в среднем 2,3 обращения к диску. Эта возможность имеет свою цену: дополнительные накладные расходы на диск и память, более высокие расходы на вставку при добавлении новых строк в таблицу и записей в индекс, а также иногда перераспределение B-Tree.
Учитывая проблемы, связанные с индексами B-Tree, движки таблиц в ClickHouse используют другой подход. Семейство движков MergeTree ClickHouse было разработано и оптимизировано для обработки огромных объемов данных. Эти таблицы предназначены для получения миллионов вставок строк в секунду и хранения очень больших объемов данных (сотни петабайт). Данные быстро записываются в таблицу по частям, с правилами, применяемыми для слияния частей в фоновом режиме. В ClickHouse каждая часть имеет свой собственный первичный индекс. Когда части сливаются, первичные индексы объединенных частей также сливаются. На очень больших масштабах, для которых предназначен ClickHouse, крайне важно быть эффективным в использовании диска и памяти. Поэтому, вместо индексации каждой строки, первичный индекс для части имеет одну запись индекса (известную как 'метка') на группу строк (называемую 'гранулой') — эта техника называется разреженным индексом.
Разреженная индексация возможна, поскольку ClickHouse хранит строки для части на диске в порядке, определенном колонками первичного ключа. Вместо того, чтобы напрямую находить отдельные строки (как в индексе на основе B-Tree), разреженный первичный индекс позволяет быстро (с помощью бинарного поиска по записям индекса) идентифицировать группы строк, которые могут соответствовать запросу. Найденные группы потенциально совпадающих строк (гранулы) затем параллельно передаются в движок ClickHouse для поиска соответствий. Этот дизайн индекса позволяет держать первичный индекс маленьким (он может и должен полностью помещаться в основной памяти), при этом значительно ускоряя время выполнения запросов: особенно для диапазонных запросов, которые характерны для аналитики данных.
Следующее подробно иллюстрирует, как ClickHouse строит и использует свой разреженный первичный индекс. Позже в статье мы обсудим некоторые лучшие практики для выбора, удаления и упорядочивания колонок таблицы, которые используются для построения индекса (колонок первичного ключа).
Таблица с первичным ключом
Создайте таблицу, которая имеет составной первичный ключ с ключевыми колонками UserID и URL:
Подробности DDL утверждения
Чтобы упростить обсуждения позже в этом руководстве, а также сделать диаграммы и результаты воспроизводимыми, DDL-утверждение:
Указывает составной ключ сортировки для таблицы через
ORDER BY.Явно контролирует, сколько записей индекса будет у первичного индекса через настройки:
index_granularity: явно установлено на значение по умолчанию 8192. Это означает, что для каждой группы из 8192 строк первичный индекс будет иметь одну запись индекса. Например, если в таблице 16384 строки, индекс будет иметь две записи индекса.index_granularity_bytes: установлено в 0, чтобы отключить адаптивную гранулярность индекса. Адаптивная гранулярность индекса означает, что ClickHouse автоматически создает одну запись индекса для группы из n строк, если выполняется одно из следующих условий:Если
nменьше 8192, и размер комбинированных данных строки для этихnстрок больше или равен 10 MB (значение по умолчанию дляindex_granularity_bytes).Если комбинированный размер данных строки для
nстрок меньше 10 MB, ноnравно 8192.
compress_primary_key: установлено в 0, чтобы отключить сжатие первичного индекса. Это позволит нам по желанию позже просмотреть его содержимое.
Первичный ключ в DDL-утверждении выше вызывает создание первичного индекса на основе двух указанных ключевых колонок.
Следующий шаг — вставить данные:
Ответ выглядит следующим образом:
И оптимизируем таблицу:
Мы можем использовать следующий запрос, чтобы получить метаданные о нашей таблице:
Ответ выглядит следующим образом:
Вывод клиента ClickHouse показывает:
- Данные таблицы хранятся в широком формате в конкретном каталоге на диске, что означает, что будет один файл данных (и один файл меток) на каждую колонку таблицы внутри этого каталога.
- В таблице 8,87 миллиона строк.
- Не сжатый размер данных всех строк вместе составляет 733,28 MB.
- Сжатый размер на диске всех строк вместе составляет 206,94 MB.
- В таблице есть первичный индекс с 1083 записями (называемыми 'метками'), и размер индекса составляет 96,93 KB.
- В общей сложности файлы данных таблицы и метки, а также файл первичного индекса занимают 207,07 MB на диске.
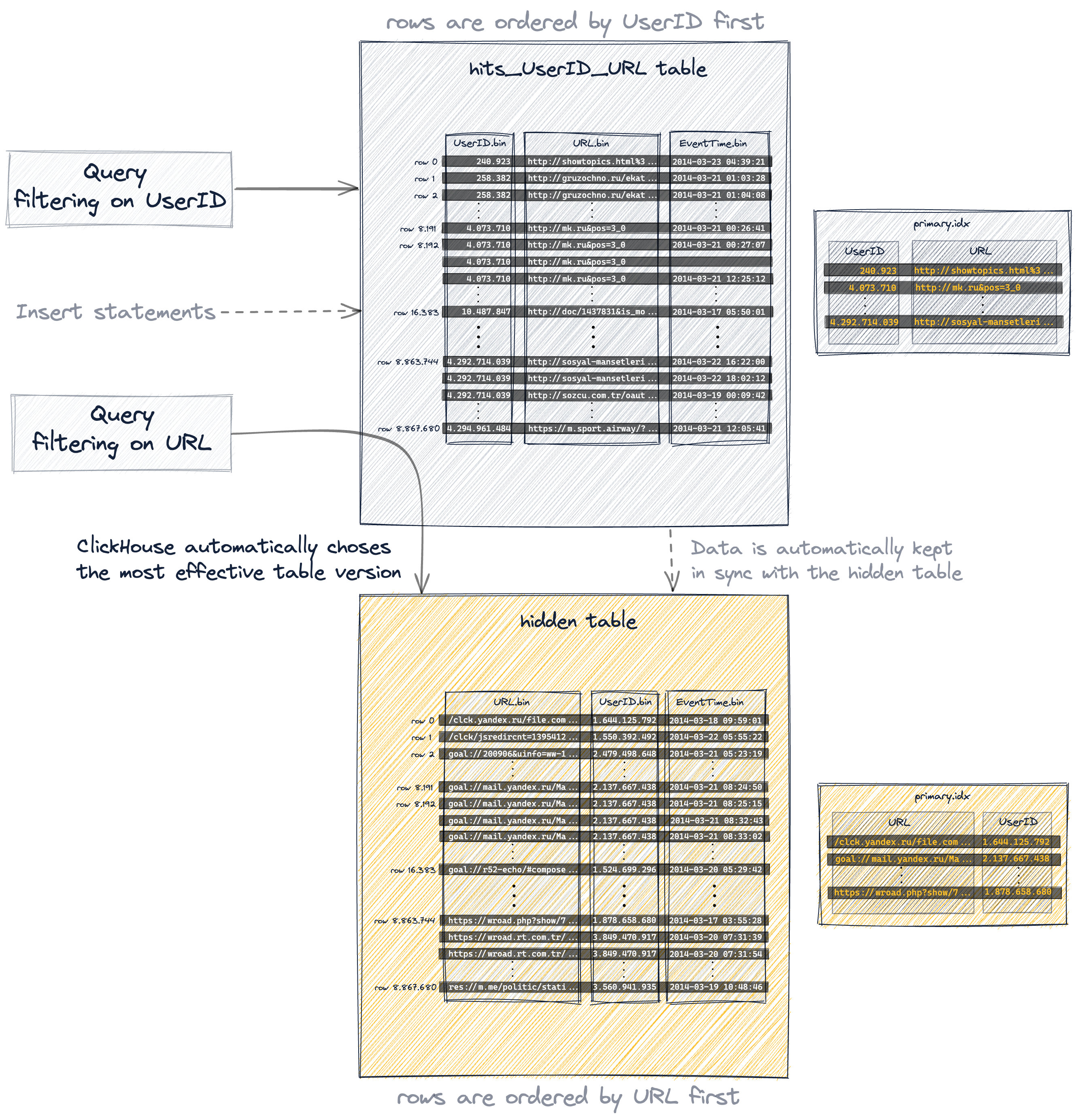
Данные хранятся на диске в порядке колонок первичного ключа
Наша таблица, которую мы создали выше, имеет
- составной первичный ключ
(UserID, URL)и - составной ключ сортировки
(UserID, URL, EventTime).
-
Если бы мы указали только ключ сортировки, тогда первичный ключ был бы неявно определен равным ключу сортировки.
-
Чтобы быть эффективным в использовании памяти, мы явно указали первичный ключ, который содержит только колонки, по которым наши запросы выполняют фильтрацию. Первичный индекс, основанный на первичном ключе, полностью загружен в основную память.
-
Чтобы иметь согласованность в диаграммах руководства и максимизировать коэффициент сжатия, мы определили отдельный сортировочный ключ, который включает все колонки нашей таблицы (если в колонке похожие данные располагаются близко друг к другу, например, путем сортировки, тогда эти данные будут лучше сжиматься).
-
Первичный ключ должен быть префиксом сортировочного ключа, если оба указаны.
Вставленные строки хранятся на диске в лексикографическом порядке (по возрастанию) по колонкам первичного ключа (и дополнительной колонке EventTime из сортировочного ключа).
ClickHouse позволяет вставлять несколько строк с одинаковыми значениями колонок первичного ключа. В этом случае (см. строка 1 и строка 2 на диаграмме ниже) окончательный порядок определяется заданным сортировочным ключом и, следовательно, значением колонки EventTime.
ClickHouse является столбцовой системой управления базами данных. Как показано на диаграмме ниже
- для представления на диске имеется единственный файл данных (*.bin) для каждой колонки таблицы, в котором хранятся все значения для этой колонки в сжатом формате, и
- 8,87 миллиона строк хранятся на диске в лексикографическом порядке по возрастанию значений колонок первичного ключа (и дополнительных колонок ключа сортировки), а именно в данном случае
- сначала по
UserID, - затем по
URL, - и наконец по
EventTime:
- сначала по
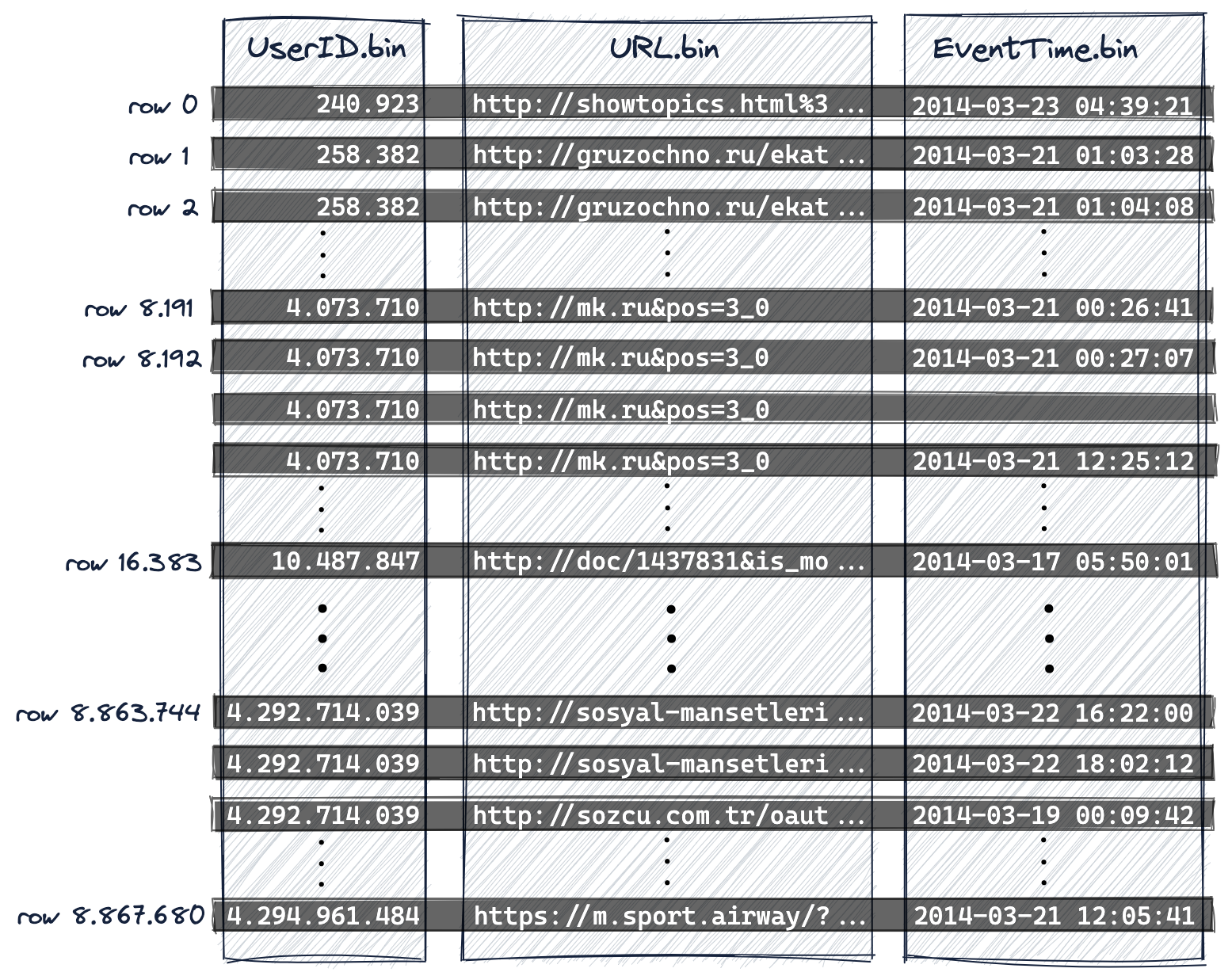
UserID.bin, URL.bin и EventTime.bin — это файлы данных на диске, где хранятся значения колонок UserID, URL и EventTime.
-
Поскольку первичный ключ определяет лексикографический порядок строк на диске, в таблице может быть только один первичный ключ.
-
Мы нумеруем строки, начиная с 0, чтобы соответствовать внутренней схеме нумерации строк ClickHouse, которая также используется для логирования сообщений.
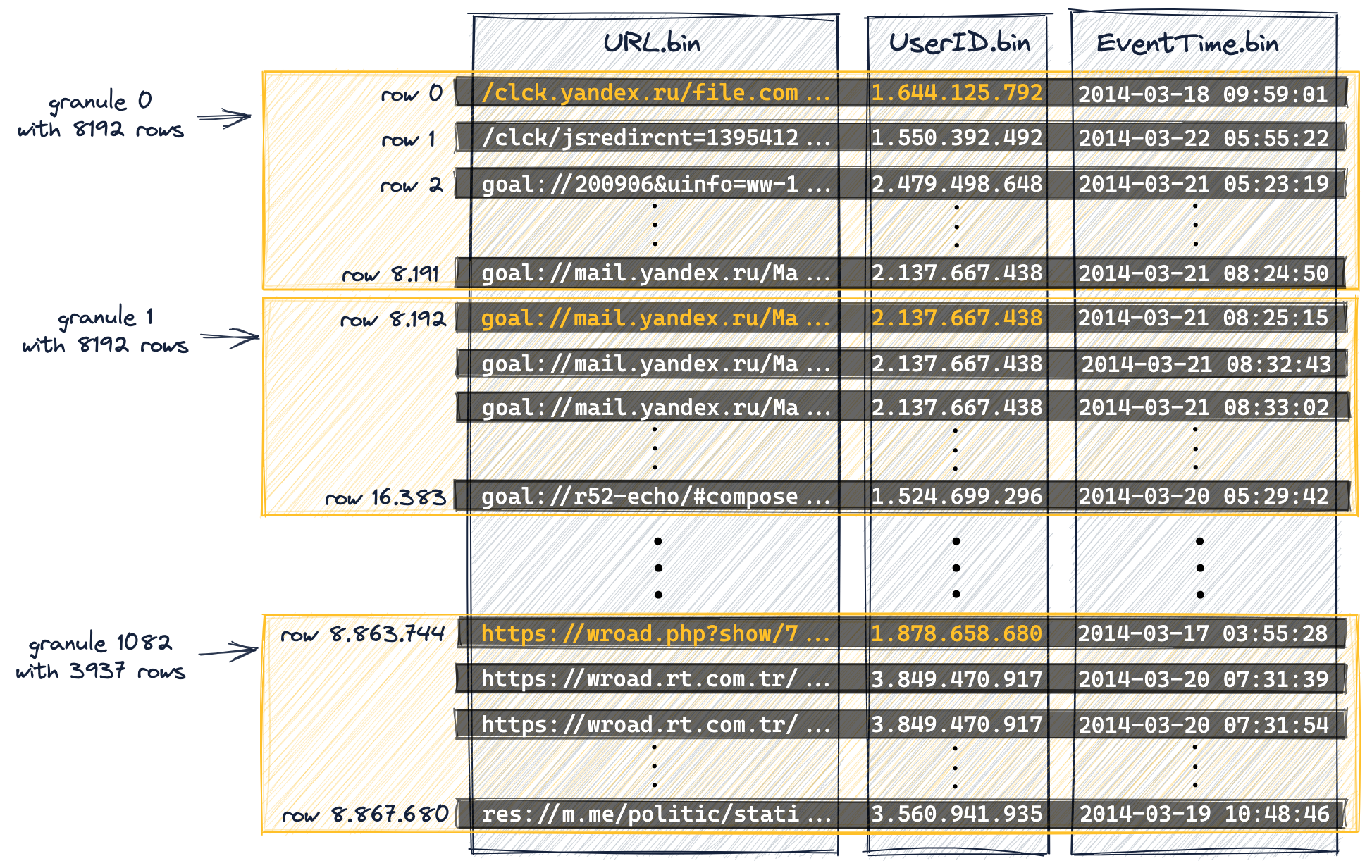
Данные организуются в гранулы для параллельной обработки данных
Для целей обработки данных значения колонок таблицы логически делятся на гранулы. Гранула — это самый маленький неделимый набор данных, который передается в ClickHouse для обработки данных. Это означает, что вместо чтения отдельных строк ClickHouse всегда читает (в потоковом режиме и параллельно) целую группу (гранулу) строк.
Значения колонок физически не хранятся внутри гранул: гранулы — это просто логическая организация значений колонок для обработки запросов.
Следующая диаграмма показывает, как (значения колонок) 8,87 миллиона строк нашей таблицы
организованы в 1083 гранулы, в результате содержащейся в DDL-утверждении таблицы настройки index_granularity (установленной на значение по умолчанию 8192).
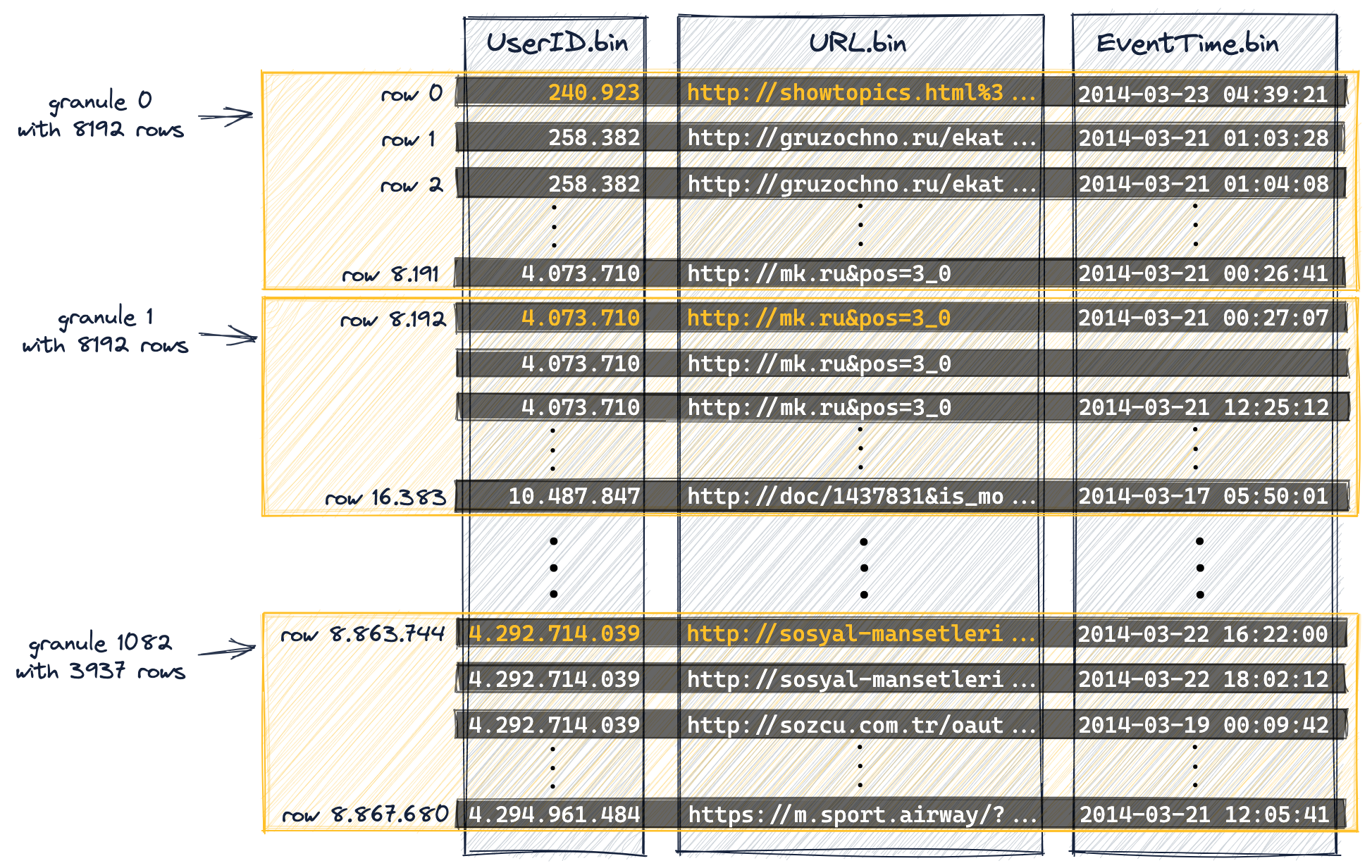
Первые (на основе физического порядка на диске) 8192 строки (их значения колонок) логически принадлежат грануле 0, затем следующие 8192 строки (их значения колонок) принадлежат грануле 1 и так далее.
-
Последняя гранула (гранула 1082) "содержит" менее 8192 строк.
-
Мы упомянули в начале этого руководства в разделе "Подробности DDL утверждения", что мы отключили адаптивную гранулярность индекса (чтобы упростить обсуждение в этом руководстве и сделать диаграммы и результаты воспроизводимыми).
Поэтому все гранулы (за исключением последней) нашей примерной таблицы имеют одинаковый размер.
-
Для таблиц с адаптивной гранулярностью индекса (гранулярность индекса по умолчанию является адаптивной, размер некоторых гранул может быть меньше 8192 строк в зависимости от размеров данных строк.
-
Мы выделили некоторые значения колонок из колонок нашего первичного ключа (
UserID,URL) оранжевым цветом. Эти выделенные оранжевым цветом значения колонок являются значениями колонок первичного ключа каждой первой строки каждой гранулы. Как мы увидим ниже, эти выделенные значения колонок будут записями в первичном индексе таблицы. -
Мы нумеруем гранулы, начиная с 0, чтобы соответствовать внутренней схеме нумерации ClickHouse, которая также используется для логирования сообщений.
Первичный индекс имеет одну запись на гранулу
Первичный индекс создается на основе гранул, показанных на диаграмме выше. Этот индекс представляет собой несжатый плоский массивный файл (primary.idx), содержащий так называемые числовые метки индекса, начиная с 0.
На диаграмме ниже показано, что индекс хранит значения колонок первичного ключа (значения, отмеченные оранжевым цветом на диаграмме выше) для каждой первой строки каждой гранулы. Или другими словами: первичный индекс хранит значения колонок первичного ключа из каждой 8192-й строки таблицы (на основе физического порядка строк, определяемого колонками первичного ключа). Например
- первая запись индекса ('метка 0' на диаграмме ниже) хранит значения ключевых колонок первой строки гранулы 0 из диаграммы выше,
- вторая запись индекса ('метка 1' на диаграмме ниже) хранит значения ключевых колонок первой строки гранулы 1 из диаграммы выше и так далее.
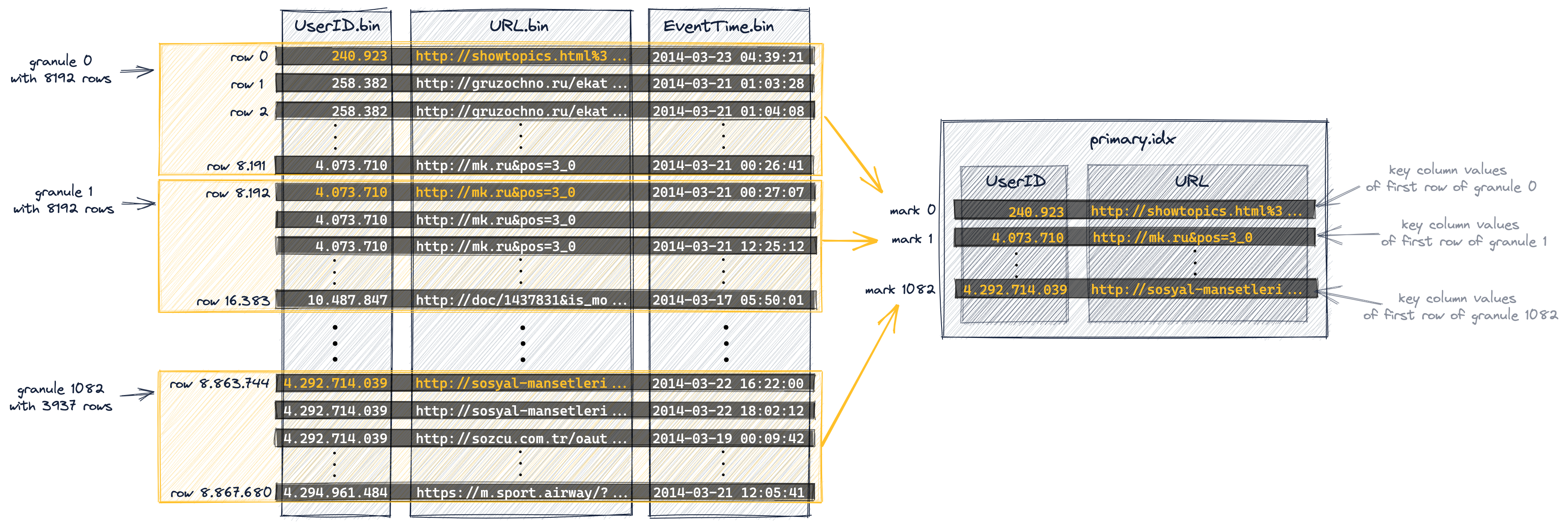
В целом индекс имеет 1083 записи для нашей таблицы из 8,87 миллионов строк и 1083 гранул:

-
Для таблиц с адаптивной гранулярностью индекса также хранится одна "финальная" метка в первичном индексе, которая фиксирует значения первичного ключа последней строки таблицы, но поскольку мы отключили адаптивную гранулярность индекса (чтобы упростить обсуждение в этом руководстве и сделать диаграммы и результаты воспроизводимыми), индекс нашей примерной таблицы не включает эту финальную метку.
-
Файл первичного индекса полностью загружается в основную память. Если файл больше доступного свободного места в памяти, ClickHouse выдает ошибку.
Проверка содержимого первичного индекса
На самоуправляемом кластере ClickHouse мы можем использовать табличную функцию file для проверки содержимого первичного индекса нашей примерной таблицы.
Для этого сначала нужно скопировать файл первичного индекса в user_files_path узла из запущенного кластера:
- Шаг 1: Получить путь к партии, которая содержит файл первичного индекса
- Шаг 2: Получить user_files_path значение по умолчанию user_files_path на Linux равно
- Шаг 3: Скопировать файл первичного индекса в user_files_path
SELECT path FROM system.parts WHERE table = 'hits_UserID_URL' AND active = 1возвращает /Users/tomschreiber/Clickhouse/store/85f/85f4ee68-6e28-4f08-98b1-7d8affa1d88c/all_1_9_4 на тестовой машине.
/var/lib/clickhouse/user_files/и на Linux вы можете проверить, изменилось ли оно: $ grep user_files_path /etc/clickhouse-server/config.xml
На тестовой машине путь — /Users/tomschreiber/Clickhouse/user_files/
cp /Users/tomschreiber/Clickhouse/store/85f/85f4ee68-6e28-4f08-98b1-7d8affa1d88c/all_1_9_4/primary.idx /Users/tomschreiber/Clickhouse/user_files/primary-hits_UserID_URL.idx
Теперь мы можем проверить содержимое первичного индекса через SQL:
- Получить количество записей
- Получить первые две метки индекса
- Получить последнюю метку индекса
SELECT count( )<br/>FROM file('primary-hits_UserID_URL.idx', 'RowBinary', 'UserID UInt32, URL String');
возвращает 1083SELECT UserID, URL<br/>FROM file('primary-hits_UserID_URL.idx', 'RowBinary', 'UserID UInt32, URL String')<br/>LIMIT 0, 2;возвращает
240923, http://showtopics.html%3...<br/> 4073710, http://mk.ru&pos=3_0
SELECT UserID, URL FROM file('primary-hits_UserID_URL.idx', 'RowBinary', 'UserID UInt32, URL String')<br/>LIMIT 1082, 1;
возвращает
4292714039 │ http://sosyal-mansetleri...Это полностью соответствует нашей диаграмме содержимого первичного индекса для нашей примерной таблицы:
Записи первичного ключа называются метками индекса, потому что каждая запись индекса помечает начало конкретного диапазона данных. В частности для примерной таблицы:
-
Индексные метки UserID:
Сохраненные значения
UserIDв первичном индексе отсортированы в порядке возрастания.
'метка 1' на диаграмме выше, таким образом, указывает на то, что значенияUserIDвсех строк таблицы в грануле 1 и во всех следующих гранулах гарантированно больше или равны 4.073.710.
Как мы увидим позже, этот глобальный порядок позволяет ClickHouse использовать бинарный поиск по меткам индекса для первого ключевого столбца, когда запрос фильтрует по первому столбцу первичного ключа.
-
Индексные метки URL:
Почти одинаковая кардинальность первичных ключевых колонок
UserIDиURLозначает, что метки индекса для всех ключевых колонок после первого столбца в общем случае только указывают на диапазон данных, пока предшествующее значение ключевого столбца остается одинаковым для всех строк таблицы внутри как минимум текущей гранулы.
Например, поскольку значения UserID меток 0 и 1 отличаются на диаграмме выше, ClickHouse не может предположить, что все значения URL всех строк таблицы в грануле 0 больше или равны'http://showtopics.html%3...'. Однако, если бы значения UserID меток 0 и 1 были одинаковыми на диаграмме выше (что означало бы, что значение UserID остается одинаковым для всех строк таблицы внутри гранулы 0), тогда ClickHouse мог бы предположить, что все значения URL всех строк таблицы в грануле 0 больше или равны'http://showtopics.html%3...'.Мы обсудим последствия этого для производительности выполнения запросов подробнее позже.
Первичный индекс используется для выбора гранул
Теперь мы можем выполнять наши запросы с поддержкой первичного индекса.
Следующий запрос вычисляет 10 наиболее кликаемых URL для UserID 749927693.
Ответ выглядит следующим образом:
Вывод клиента ClickHouse теперь показывает, что вместо полного сканирования таблицы только 8.19 тысячи строк были переданы в ClickHouse.
Если включено логирование трассировки, то файл журнала сервера ClickHouse показывает, что ClickHouse выполнял бинарный поиск по 1083 меткам индекса UserID, чтобы идентифицировать гранулы, которые могут содержать строки со значением столбца UserID 749927693. Это требует 19 шагов со средней временной сложностью O(log2 n):
Мы видим в журнале трассировки выше, что одна метка из 1083 существующих меток удовлетворила запрос.
Подробности журнала трассировки
Была идентифицирована метка 176 (левая граница метки найдена включительно, правая граница метки найдена исключительно), и, следовательно, все 8192 строки из гранулы 176 (которая начинается с строки 1.441.792 — мы увидим это позже в этом руководстве) затем передаются в ClickHouse, чтобы найти фактические строки со значением столбца UserID 749927693.
Мы также можем воспроизвести это, используя клауза EXPLAIN в нашем примерном запросе:
Ответ выглядит следующим образом:
Вывод клиента показывает, что одна из 1083 гранул была выбрана как потенциально содержащая строки со значением столбца UserID 749927693.
Когда запрос выполняет фильтрацию по колонке, которая является частью составного ключа и является первым ключевым столбцом, ClickHouse выполняет бинарный поисковый алгоритм по меткам индекса ключевого столбца.
Как обсуждалось выше, ClickHouse использует свой разреженный первичный индекс для быстрого (с помощью бинарного поиска) выбора гранул, которые могут содержать строки, соответствующие запросу.
Это первая стадия (выбор гранулы) выполнения запроса в ClickHouse.
На второй стадии (чтение данных) ClickHouse находит выбранные гранулы, чтобы передать все их строки в движок ClickHouse для нахождения строк, которые фактически соответствуют запросу.
Мы обсудим эту вторую стадию подробнее в следующем разделе.
Файлы меток используются для локализации гранул
Следующая диаграмма иллюстрирует часть файла первичного индекса для нашей таблицы.

Как обсуждалось выше, с помощью бинарного поиска по 1083 меткам UserID индекса была определена метка 176. Следовательно, соответствующая гранула 176 может содержать строки со значением столбца UserID 749.927.693.
Подробности выбора гранулы
На диаграмме выше показано, что метка 176 является первой записью индекса, где минимальное значение UserID связанной гранулы 176 меньше 749.927.693, а минимальное значение UserID гранулы 177 для следующей метки (метка 177) больше этого значения. Поэтому только соответствующая гранула 176 для метки 176 может содержать строки со значением столбца UserID 749.927.693.
Чтобы подтвердить (или опровергнуть), что некоторые строки в грануле 176 содержат значение столбца UserID 749.927.693, необходимо передать все 8192 строки, принадлежащие этой грануле, в ClickHouse.
Для достижения этой цели ClickHouse необходимо знать физическое местоположение гранулы 176.
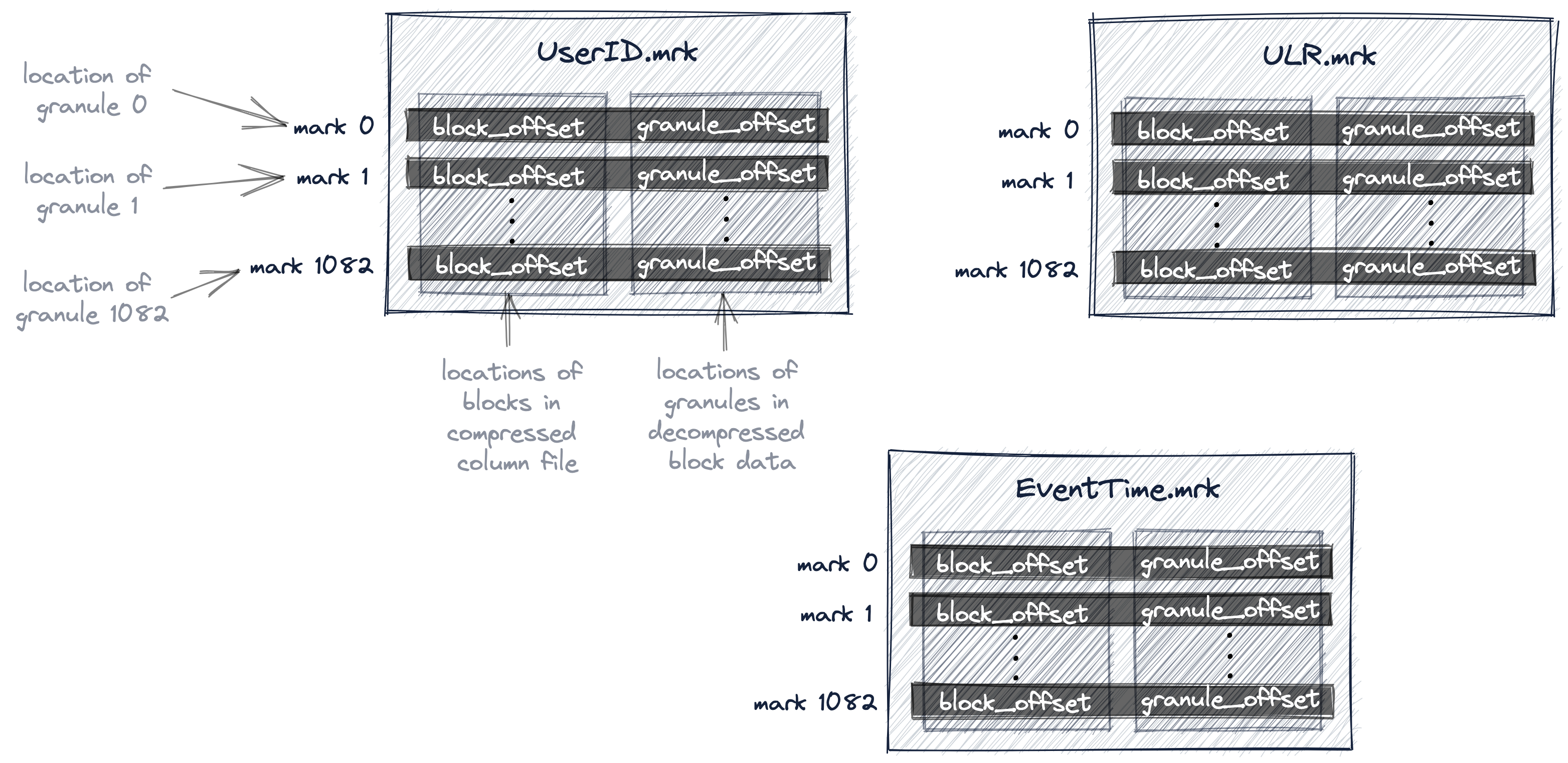
В ClickHouse физические местоположения всех гранул для нашей таблицы хранятся в файлах меток. Аналогично данным, для каждого столбца таблицы существует один файл меток.
Следующая диаграмма показывает три файла меток UserID.mrk, URL.mrk и EventTime.mrk, которые хранят физические местоположения гранул для столбцов UserID, URL и EventTime таблицы.
Мы обсуждали, что первичный индекс является плоским несжатым файловым массивом (primary.idx), содержащим метки индекса, которые пронумерованы, начиная с 0.
Аналогично, файл меток также является плоским несжатым файловым массивом (*.mrk), содержащим метки, которые также пронумерованы, начиная с 0.
Как только ClickHouse определил и выбрал метку индекса для гранулы, которая может содержать соответствующие строки для запроса, можно выполнить поиск по позиционному массиву в файлах меток, чтобы получить физические местоположения гранулы.
Каждая запись файла меток для конкретного столбца хранит два местоположения в виде смещений:
-
Первое смещение ('block_offset' на диаграмме выше) указывает на блок в сжатом файле данных столбца, который содержит сжатую версию выбранной гранулы. Этот сжатый блок потенциально может содержать несколько сжатых гранул. Найденный сжатый файл блока декомпрессируется в основную память при чтении.
-
Второе смещение ('granule_offset' на диаграмме выше) из файла меток указывает местоположение гранулы внутри несжатого блока данных.
Все 8192 строки, принадлежащие найденной несжатой грануле, затем передаются в ClickHouse для дальнейшей обработки.
- Для таблиц с широким форматом и без адаптивной зернистости индекса ClickHouse использует файлы меток
.mrk, как показано выше, которые содержат записи с двумя адресами длиной 8 байт на запись. Эти записи являются физическими местоположениями гранул, которые все имеют одинаковый размер.
Зернистость индекса является адаптивной по умолчанию, но для нашей примера таблицы мы отключили адаптивную зернистость индекса (чтобы упростить обсуждение в этом руководстве, а также сделать диаграммы и результаты воспроизводимыми). Наша таблица использует широкий формат, потому что размер данных больше, чем min_bytes_for_wide_part (который по умолчанию составляет 10 МБ для самоуправляемых кластеров).
-
Для таблиц с широким форматом и с адаптивной зернистостью индекса ClickHouse использует файлы меток
.mrk2, которые содержат аналогичные записи, как файлы меток.mrk, но с дополнительным третьим значением для каждой записи: количество строк гранулы, с которой связана текущая запись. -
Для таблиц с компактным форматом ClickHouse использует файлы меток
.mrk3.
Почему первичный индекс не содержит напрямую физические местоположения гранул, которые соответствуют меткам индекса?
Потому что на таком крупномасштабном уровне, для которого предназначен ClickHouse, важно быть очень эффективным в отношении дискового и памяти.
Файл первичного индекса должен уместиться в основной памяти.
Для нашего примера запроса ClickHouse использовал первичный индекс и выбрал одну гранулу, которая может содержать строки, соответствующие нашему запросу. Только для этой одной гранулы ClickHouse затем нужно физическое местоположение, чтобы передать соответствующие строки для дальнейшей обработки.
Более того, эта информация о смещении требуется только для столбцов UserID и URL.
Информация о смещении не требуется для столбцов, которые не использованы в запросе, например, EventTime.
Для нашего примера запроса ClickHouse необходимо только два физических смещения для гранулы 176 в файле данных UserID (UserID.bin) и два физических смещения для гранулы 176 в файле данных URL (URL.bin).
Недирекция, предоставляемая файлами меток, позволяет избежать хранения прямо в первичном индексе записей для физических местоположений всех 1083 гранул для всех трех столбцов: таким образом избегая наличия ненужных (возможно неиспользуемых) данных в основной памяти.
Следующая диаграмма и текст ниже иллюстрируют, как для нашего примера запроса ClickHouse локализует гранулу 176 в файле данных UserID.bin.
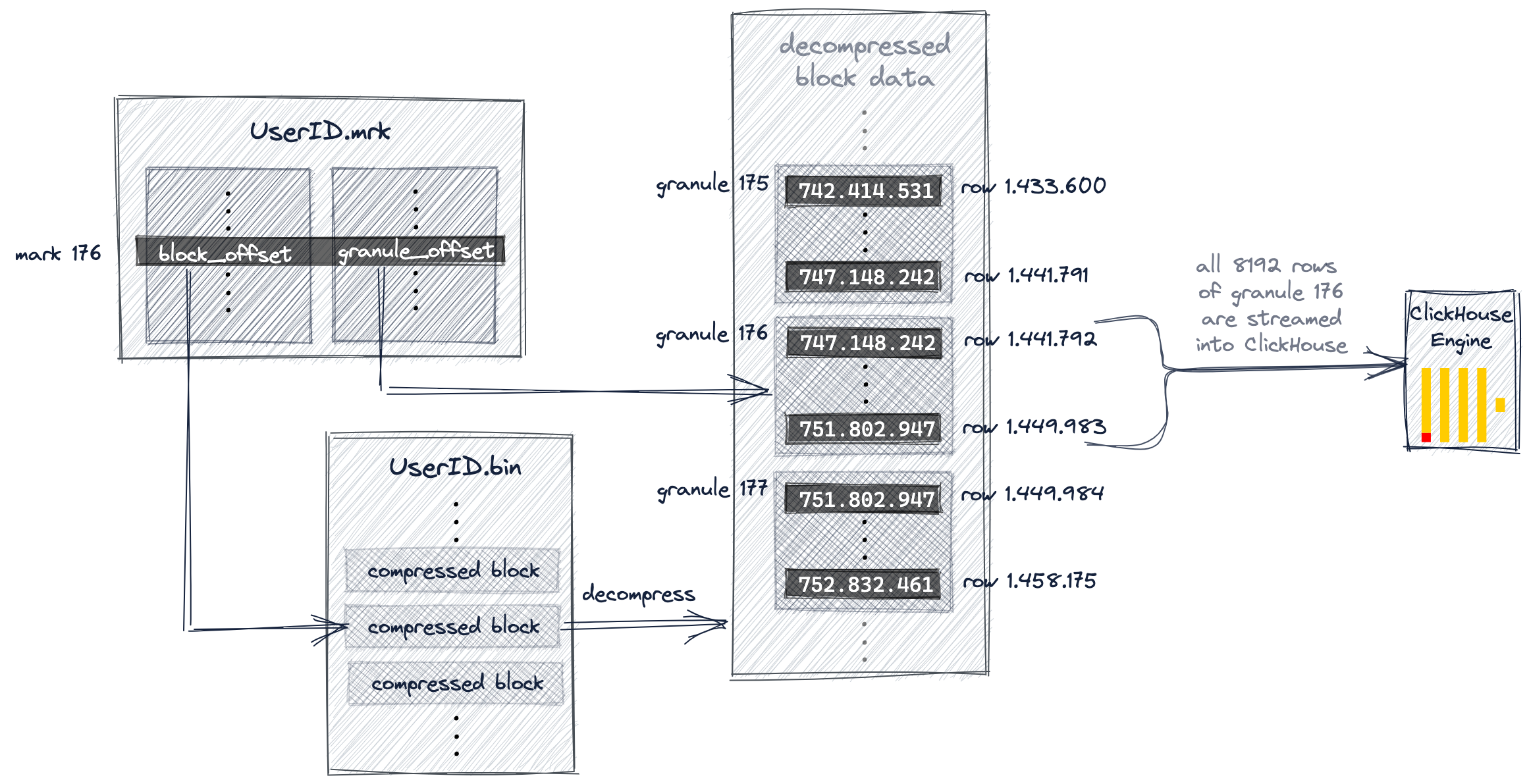
Мы обсуждали ранее в этом руководстве, что ClickHouse выбрал метку первичного индекса 176 и, следовательно, гранулу 176 как возможно содержащую соответствующие строки для нашего запроса.
ClickHouse теперь использует выбранный номер метки (176) из индекса для выполнения позиционного поиска массива в файле меток UserID.mrk, чтобы получить два смещения для локализации гранулы 176.
Как показано, первое смещение указывает на сжатый файл блока внутри файла данных UserID.bin, который, в свою очередь, содержит сжатую версию гранулы 176.
Как только найденный файл блока будет раскодирован в основную память, второе смещение из файла меток можно использовать для локализации гранулы 176 внутри несжатых данных.
ClickHouse необходимо локализовать (и отправить все значения из) гранулы 176 из обоих файлов данных UserID.bin и URL.bin, чтобы выполнить наш пример запроса (топ-10 самых кликабельных URL для интернет-пользователя с UserID 749.927.693).
Диаграмма выше показывает, как ClickHouse находит гранулу для файла данных UserID.bin.
Параллельно ClickHouse делает то же самое для гранулы 176 для файла данных URL.bin. Обе соответствующие гранулы выравниваются и передаются в движок ClickHouse для дальнейшей обработки, т.е. агрегации и подсчета значений URL по группам для всех строк, где UserID равен 749.927.693, перед окончательным выводом 10 крупнейших групп URL в порядке убывания количеств.
Использование нескольких первичных индексов
Вторичные ключевые столбцы могут быть (не) неэффективными
Когда запрос фильтрует по столбцу, который является частью составного ключа и является первым ключевым столбцом, то ClickHouse выполняет алгоритм бинарного поиска по меткам индекса этого ключевого столбца.
Но что происходит, когда запрос фильтрует по столбцу, который является частью составного ключа, но не является первым ключевым столбцом?
Мы обсуждаем сценарий, когда запрос явно не фильтрует по первому ключевому столбцу, а по вторичному ключевому столбцу.
Когда запрос фильтрует по первому ключевому столбцу и по любому ключевому столбцу после первого, тогда ClickHouse выполняет бинарный поиск по меткам индекса первого ключевого столбца.
Мы используем запрос, который вычисляет топ-10 пользователей, которые чаще всего кликали по URL "http://public_search":
Вывод клиента указывает, что ClickHouse почти выполнил полное сканирование таблицы, несмотря на то, что столбец URL является частью составного первичного ключа! ClickHouse считывает 8.81 миллиона строк из 8.87 миллионов строк таблицы.
Если trace_logging включено, то файл журнала сервера ClickHouse показывает, что ClickHouse использовал алгоритм общего исключения по 1083 меткам индекса URL, чтобы определить те гранулы, которые, возможно, могут содержать строки со значением столбца URL "http://public_search":
Мы можем видеть в примере журнала трассировки выше, что 1076 (по меткам) из 1083 гранул были выбраны как возможно содержащие строки с соответствующим значением URL.
Это приводит к тому, что 8.81 миллиона строк передается в движок ClickHouse (параллельно используя 10 потоков), чтобы идентифицировать строки, которые действительно содержат значение URL "http://public_search".
Тем не менее, как мы увидим позже, только 39 гранул из 1076 выбранных гранул на самом деле содержат соответствующие строки.
Хотя первичный индекс, основанный на составном первичном ключе (UserID, URL), оказался очень полезным для ускорения запросов на фильтрацию строк с определенным значением UserID, индекс не предоставляет значительной помощи в ускорении запроса, который фильтрует строки с определенным значением URL.
Причина этого в том, что столбец URL не является первым ключевым столбцом, и поэтому ClickHouse использует алгоритм общего исключения (вместо бинарного поиска) по меткам индекса столбца URL, и эффективность этого алгоритма зависит от разницы в кардинальности между столбцом URL и его предшествующим ключевым столбцом UserID.
Чтобы проиллюстрировать это, мы предоставим некоторые детали о том, как работает алгоритм общего исключения.
Алгоритм общего исключения
Следующее иллюстрирует, как работает алгоритм общего исключения ClickHouse, когда гранулы выбираются через вторичный столбец, где предшествующий ключевой столбец имеет низкую или высокую кардинальность.
В качестве примера для обоих случаев мы будем считать:
- запрос, который ищет строки со значением URL = "W3".
- абстрактную версию нашей таблицы с упрощенными значениями для UserID и URL.
- тот же составной первичный ключ (UserID, URL) для индекса. Это означает, что строки сначала упорядочены по значениям UserID. Строки с одинаковым значением UserID затем упорядочиваются по URL.
- размер гранулы равен двум, т.е. каждая гранула содержит две строки.
Мы отметили значения ключевого столбца для первых строк таблицы для каждой гранулы оранжевым цветом на диаграммах ниже.
Предшествующий ключевой столбец имеет низкую кардинальность
Предположим, что UserID имеет низкую кардинальность. В этом случае вполне вероятно, что одно и то же значение UserID распределено по нескольким строкам таблицы и гранулам, и, следовательно, по меткам индекса. Для меток индекса с одинаковым UserID значения URL для меток индекса сортируются в порядке возрастания (поскольку строки таблицы сначала упорядочены по UserID, а затем по URL). Это позволяет проводить эффективную фильтрацию, как описано ниже:
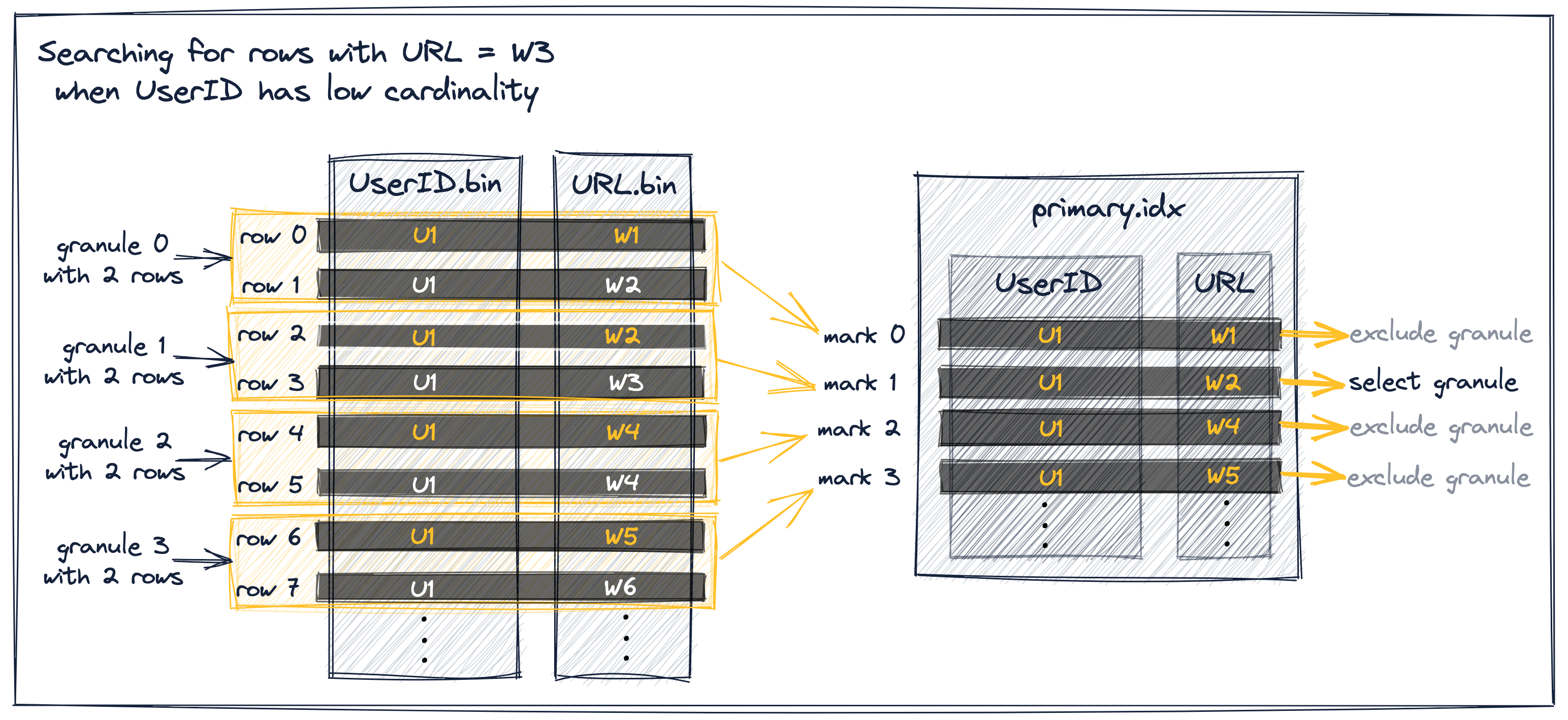
Существует три различных сценария для процесса выбора гранул для наших абстрактных примерных данных на диаграмме выше:
-
Метка индекса 0, для которой значение URL меньше W3 и значение URL следующей за ней метки также меньше W3, может быть исключена, потому что метка 0 и 1 имеют одно и то же значение UserID. Обратите внимание, что это предусловие исключения гарантирует, что гранула 0 полностью состоит из значений UserID U1, так что ClickHouse может предположить, что и максимальное значение URL в грануле 0 меньше W3 и исключить гранулу.
-
Метка индекса 1, для которой значение URL меньше (или равно) W3 и значение URL следующей за ней метки больше (или равно) W3, выбрана, потому что это означает, что гранула 1 может содержать строки со значением URL W3.
-
Метки индексов 2 и 3, для которых значение URL больше W3, могут быть исключены, поскольку метки индексов первичного индекса хранят значения ключевых столбцов для первой строки таблицы для каждой гранулы, и строки таблицы отсортированы на диске по значениям ключевых столбцов, поэтому гранулы 2 и 3 не могут содержать значение URL W3.
Предшествующий ключевой столбец имеет высокую кардинальность
Когда UserID имеет высокую кардинальность, маловероятно, что одно и то же значение UserID распределено по нескольким строкам таблицы и гранулам. Это означает, что значения URL для меток индекса не увеличиваются монотонно:
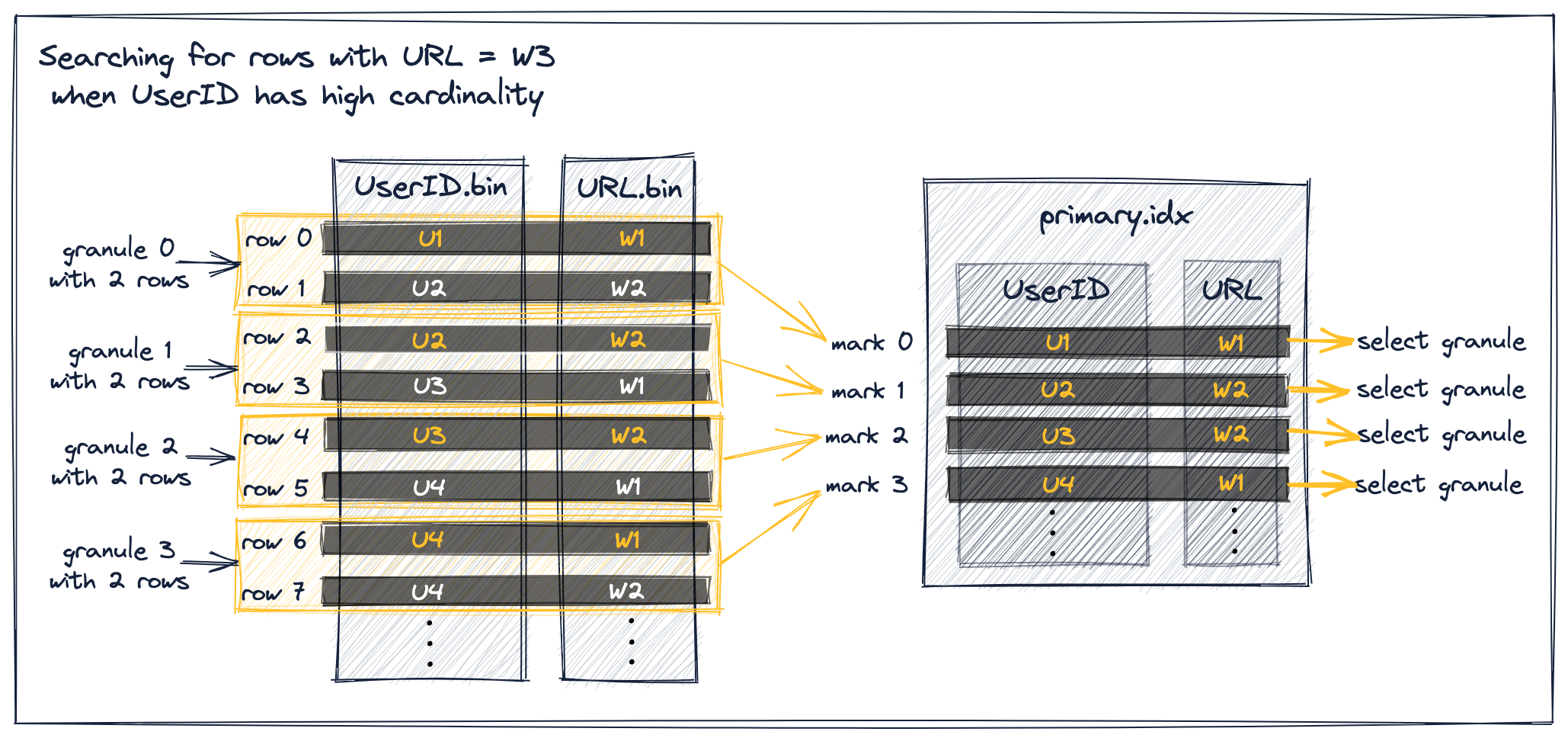
Как мы видим на диаграмме выше, все показанные метки, у которых значения URL меньше W3, выбираются для передачи строк их ассоциированных гранул в движок ClickHouse.
Это потому, что хотя все метки индекса на диаграмме попадают в сценарий 1, описанный выше, они не удовлетворяют упомянутому предположению об исключении, что следующая за ней метка индекса имеет то же значение UserID, что и текущая метка, и поэтому их нельзя исключить.
Например, рассмотрим метку индекса 0, для которой значение URL меньше W3 и значение URL следующей метки также меньше W3. Эта метка не может быть исключена, потому что следующая метка индекса 1 не имеет того же значения UserID, что и текущая метка 0.
Это, в конечном итоге, предотвращает ClickHouse от распространения предположений о максимальном значении URL в грануле 0. Вместо этого ему необходимо предположить, что гранула 0 потенциально содержит строки со значением URL W3 и вынуждено выбрать метку 0.
Та же ситуация справедлива для меток 1, 2 и 3.
Алгоритм общего исключения, который использует ClickHouse вместо алгоритма бинарного поиска, когда запрос фильтрует по столбцу, который является частью составного ключа, но не является первым ключевым столбцом, наиболее эффективен, когда предшествующий ключевой столбец имеет низкую кардинальность.
В нашем наборе примерных данных оба ключевых столбца (UserID, URL) имеют схожую высокую кардинальность, и, как объяснено, алгоритм общего исключения не очень эффективен, когда предшествующий ключевой столбец столбца URL имеет высокую или аналогичную кардинальность.
Примечание о индексе пропуска данных
Из-за схожей высокой кардинальности UserID и URL, наш запрос, фильтрующий по URL также не получит значительной выгоды от создания вторичного индекса пропуска данных по столбцу URL нашей таблицы с составным первичным ключом (UserID, URL).
Например, эти два выражения создают и заполняют минмакс индекс пропуска данных по столбцу URL нашей таблицы:
ClickHouse теперь создал дополнительный индекс, который хранит - для группы из 4 последовательных гранул (обратите внимание на оператор GRANULARITY 4 в выражении ALTER TABLE выше) - минимальное и максимальное значение URL:

Первая запись индекса ('метка 0' на диаграмме выше) хранит минимальные и максимальные значения URL для строк, принадлежащих первой группе из 4 гранул нашей таблицы.
Вторая запись индекса ('метка 1') хранит минимальные и максимальные значения URL для строк, принадлежащих следующей группе из 4 гранул нашей таблицы, и так далее.
(ClickHouse также создал специальный файл меток для индекса пропуска данных для локализации групп гранул, связанных с метками индекса.)
Из-за схожей высокой кардинальности UserID и URL этот вторичный индекс пропуска данных не может помочь в исключении гранул из выборки, когда наш запрос, фильтрующий по URL выполняется.
Конкретное значение URL, которого ищет запрос (т.е. 'http://public_search'), очень вероятно находится между минимальным и максимальным значением, хранящимся индексом для каждой группы гранул, что приводит к тому, что ClickHouse вынужден выбрать группу гранул (поскольку они могут содержать строки, соответствующие запросу).
Необходимость использовать несколько первичных индексов
Таким образом, если мы хотим значительно ускорить наш пример запроса, который фильтрует строки с определенным URL, то нам необходимо использовать первичный индекс, оптимизированный для этого запроса.
В дополнение, если мы хотим сохранить хорошую производительность нашего примера запроса, который фильтрует строки с определенным UserID, нам необходимо использовать несколько первичных индексов.
Следующее показывает способы достижения этого.
Опции для создания дополнительных первичных индексов
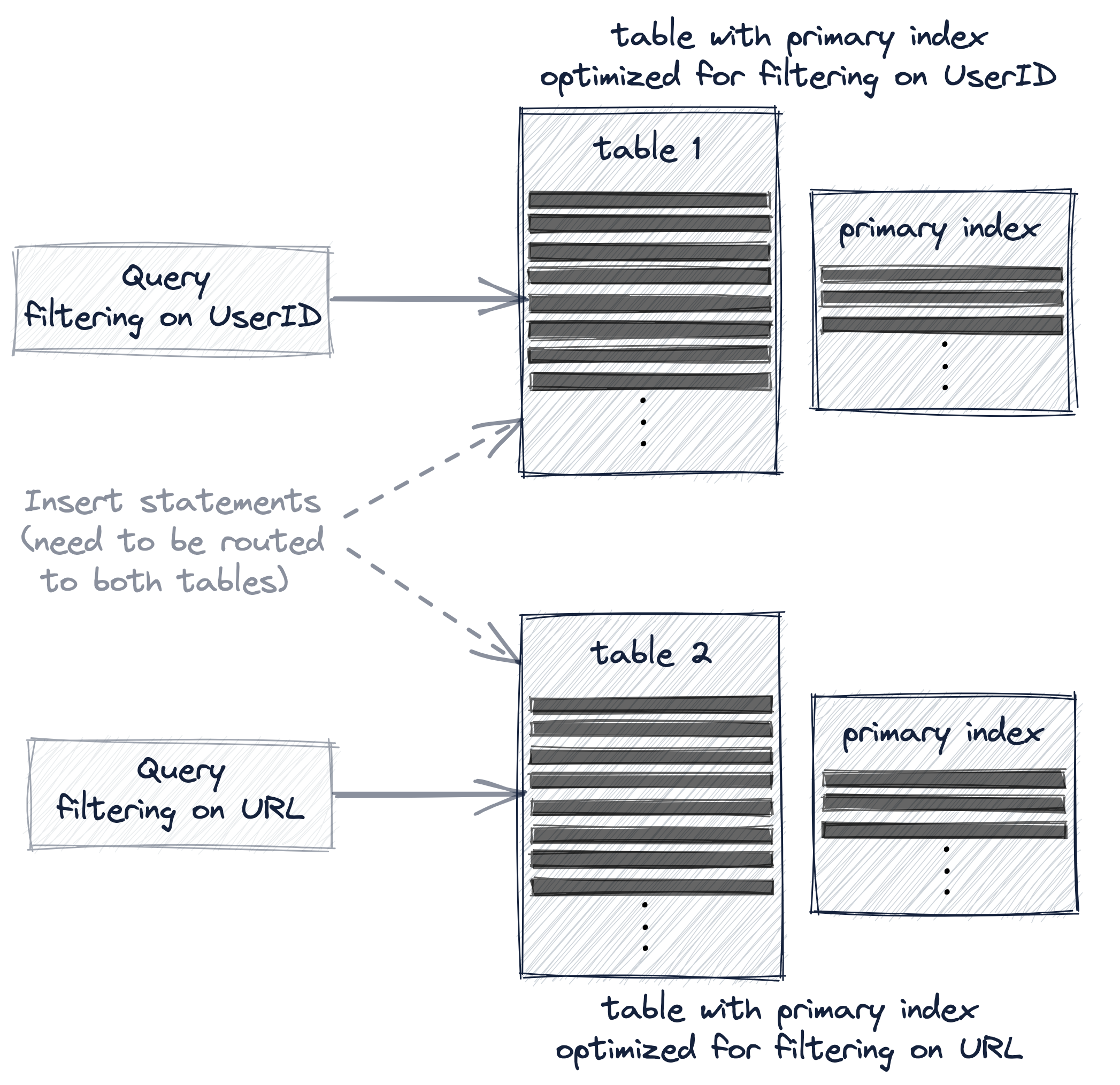
Если мы хотим значительно ускорить оба наших примера запросов - тот, который фильтрует строки с конкретным UserID и тот, который фильтрует строки с конкретным URL - тогда нам необходимо использовать несколько первичных индексов, воспользовавшись одним из этих трех вариантов:
- Создание второй таблицы с другим первичным ключом.
- Создание материализованного представления на нашей существующей таблице.
- Добавление проекции к нашей существующей таблице.
Все три варианта эффективно дублируют наши примерные данные в дополнительной таблице для реорганизации первичного индекса таблицы и порядка сортировки строк.
Однако три варианта различаются тем, насколько прозрачна эта дополнительная таблица для пользователя в отношении маршрутизации запросов и операторов вставки.
При создании второй таблицы с другим первичным ключом запросы должны быть явно отправлены版本 таблицы, наиболее подходящей для запроса, и новые данные должны быть явно вставлены в обе таблицы для поддержания синхронизации таблиц:
С материализованным представлением дополнительная таблица создается неявно, и данные автоматически поддерживаются в синхронизации между обеими таблицами:
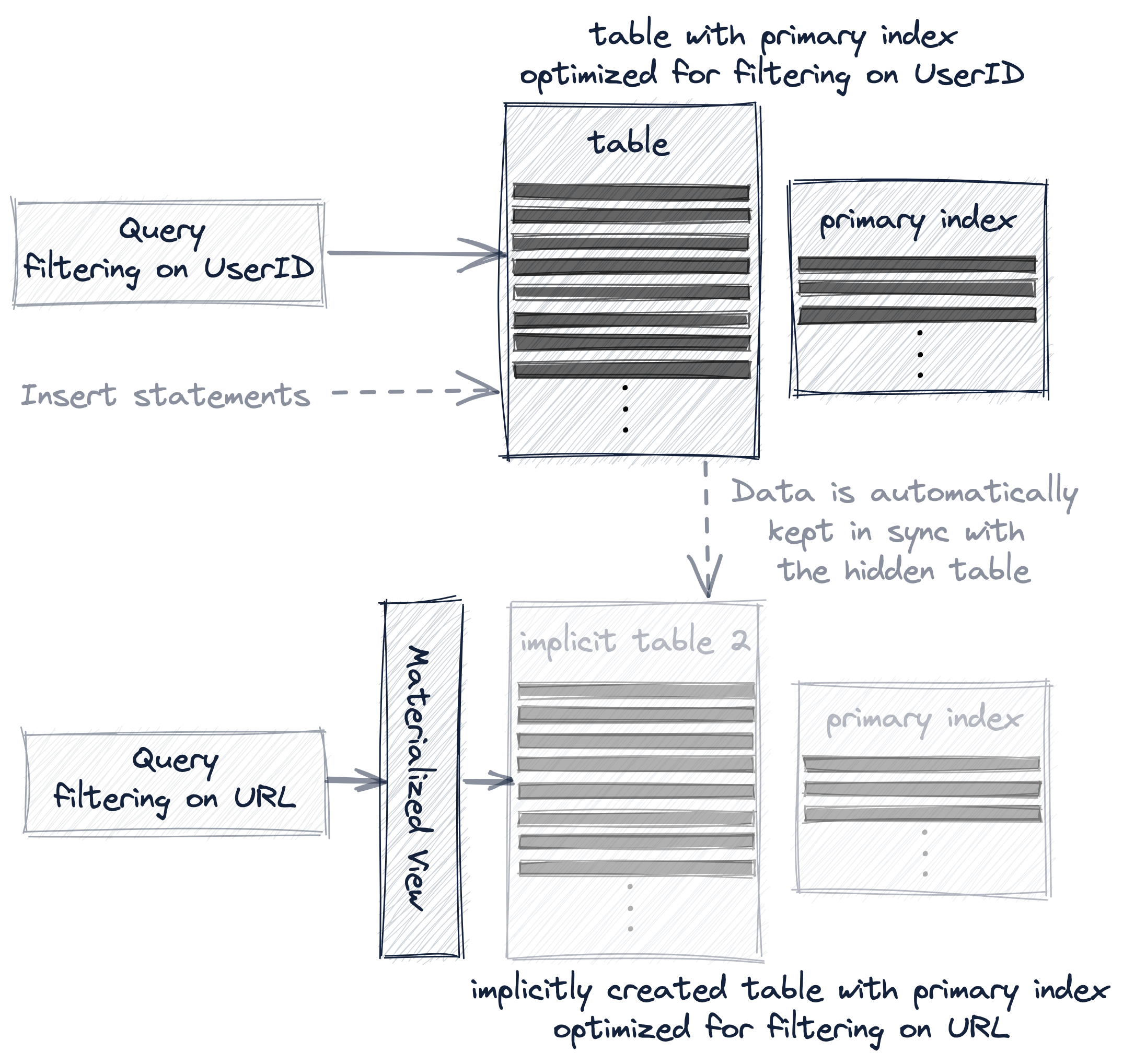
А проекция является наиболее прозрачным вариантом, потому что помимо автоматической синхронизации неявно созданной (и скрытой) дополнительной таблицы с изменениями данных, ClickHouse автоматически выберет наиболее эффективную версию таблицы для запросов:
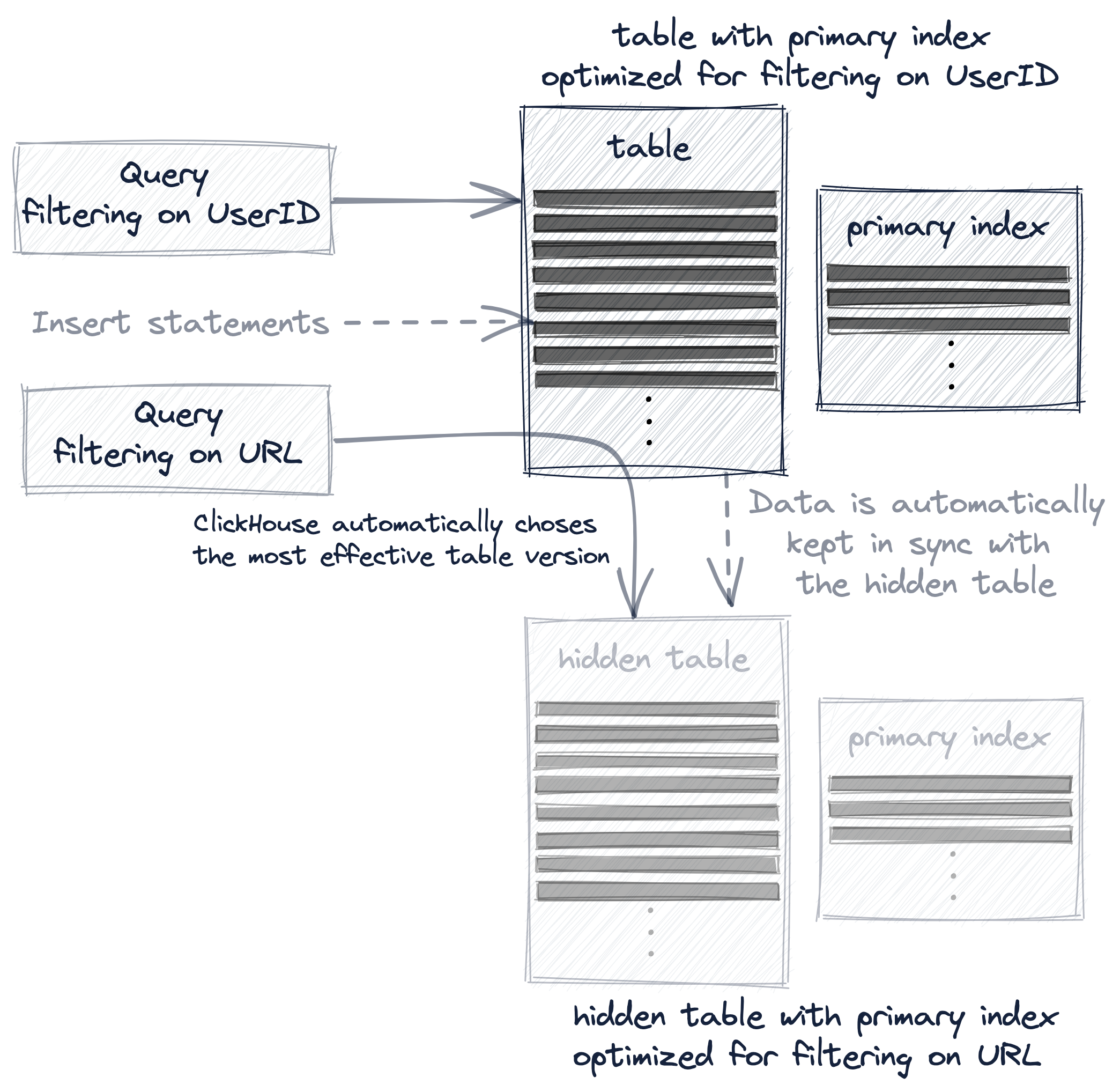
В следующем мы подробнее обсудим эти три варианта создания и использования нескольких первичных индексов с реальными примерами.
Вариант 1: Вторичные таблицы
Мы создаем новую дополнительную таблицу, где меняем порядок ключевых столбцов (по сравнению с нашей оригинальной таблицей) в первичном ключе:
Вставляем все 8.87 миллионов строк из нашей оригинальной таблицы в дополнительную таблицу:
Ответ выглядит так:
И в конце оптимизируем таблицу:
Поскольку мы поменяли порядок столбцов в первичном ключе, вставленные строки теперь хранятся на диске в другом лексикографическом порядке (по сравнению с нашей оригинальной таблицей), и, следовательно, 1083 гранулы этой таблицы содержат другие значения, чем прежде:
Вот как выглядит первичный ключ результирующей таблицы:

Этот ключ теперь можно использовать для значительного ускорения выполнения нашего примерного запроса, фильтрующего по столбцу URL, чтобы вычислить топ-10 пользователей, наиболее часто кликавших по URL "http://public_search":
Ответ:
Теперь, вместо почти полного сканирования таблицы ClickHouse выполнил этот запрос гораздо более эффективно.
С первичным индексом из оригинальной таблицы, где UserID был первым, а URL вторым ключевым столбцом, ClickHouse использовал алгоритм общего исключения для выполнения этого запроса, и это было не очень эффективно из-за схожей высокой кардинальности UserID и URL.
С URL в качестве первого столбца в первичном индексе ClickHouse теперь проводит бинарный поиск по меткам индекса. Соответствующий журнал трассировки в файле журнала сервера ClickHouse подтверждает, что:
ClickHouse выбрал только 39 меток индекса, вместо 1076, когда использовался алгоритм общего исключения.
Обратите внимание, что дополнительная таблица оптимизирована для ускорения выполнения нашего примерного запроса, фильтрующего по URL.
Похожим образом, как в случае низкой производительности этого запроса в нашей оригинальной таблице, наш пример запроса, фильтрующего по UserID не будет выполняться очень эффективно с новой дополнительной таблицей, потому что UserID теперь является вторым ключевым столбцом в первичном индексе этой таблицы, и поэтому ClickHouse будет использовать общий алгоритм исключения для выбора гранул, что неэффективно для схожей высокой кардинальности UserID и URL. Откройте подробности для уточнения.
Теперь у нас есть две таблицы. Оптимизированные для ускорения запросов фильтрации по UserID, и для ускорения запросов фильтрации по URL, соответственно:
Вариант 2: Материализованные представления
Создать материализованное представление на нашей существующей таблице.
Ответ выглядит так:
- мы меняем порядок ключевых столбцов (по сравнению с нашей оригинальной таблицей) в первичном ключе представления
- материализованное представление поддерживается неявно созданной таблицей, чья сортировка строк и первичный индекс основаны на заданном определении первичного ключа
- неявно созданная таблица отображается по запросу
SHOW TABLESи имеет имя, начинающееся с.inner - также возможно сначала явно создать вспомогательную таблицу для материализованного представления, а затем это представление может обращаться к этой таблице через клаузу
TO [db].[table] - мы используем ключевое слово
POPULATE, чтобы немедленно заполнить неявно созданную таблицу всеми 8.87 миллионами строк из исходной таблицы hits_UserID_URL - если в исходную таблицу hits_UserID_URL будут добавлены новые строки, то эти строки также автоматически будут вставляться в неявно созданную таблицу
- Эффективно неявно созданная таблица имеет тот же порядок строк и первичный индекс, что и вторичная таблица, которую мы создали явно:
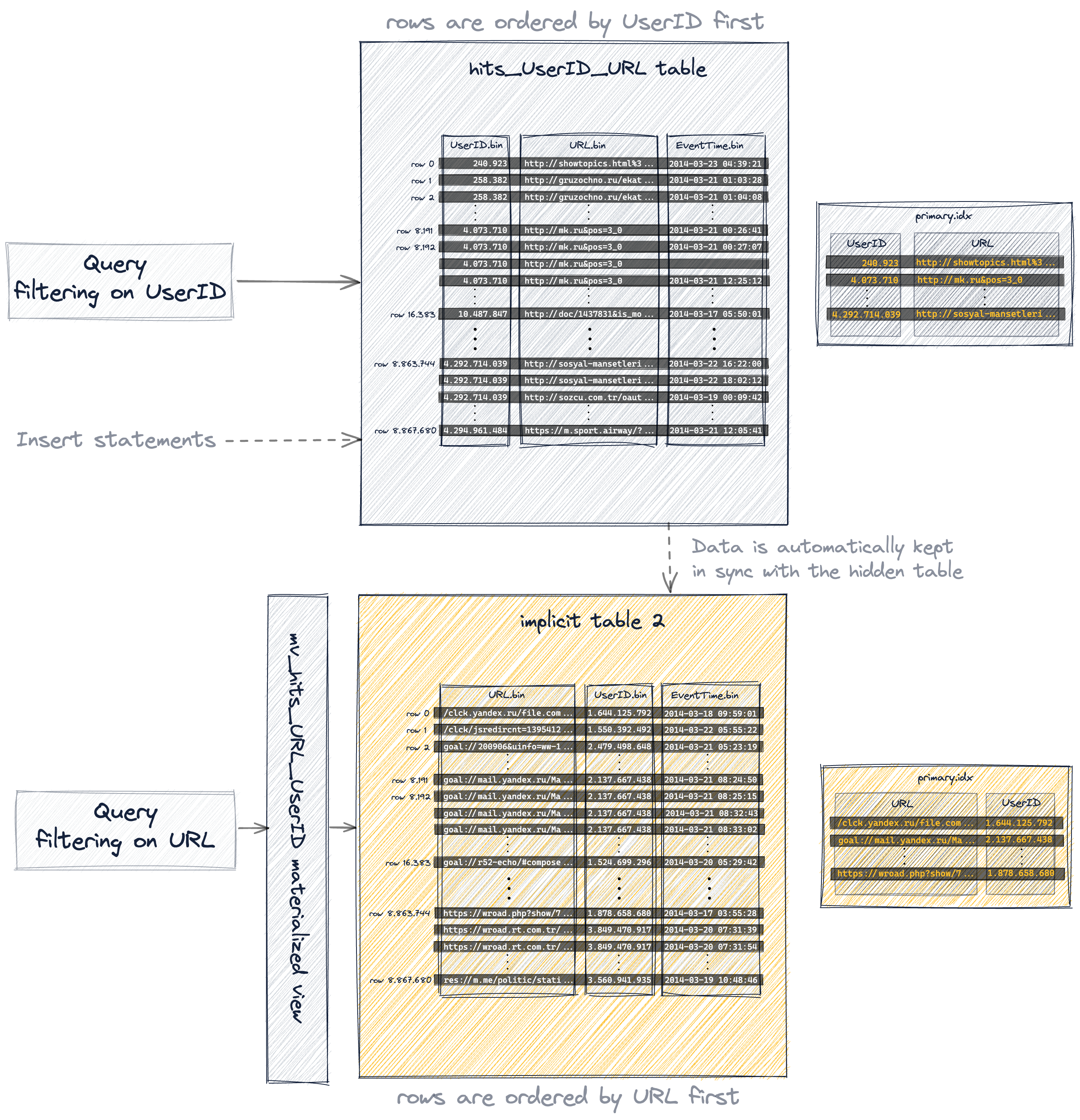
ClickHouse хранит файлы данных столбцов (.bin), файлы меток (.mrk2) и первичный индекс (primary.idx) неявно созданной таблицы в специальной папке внутри каталога данных сервера ClickHouse:
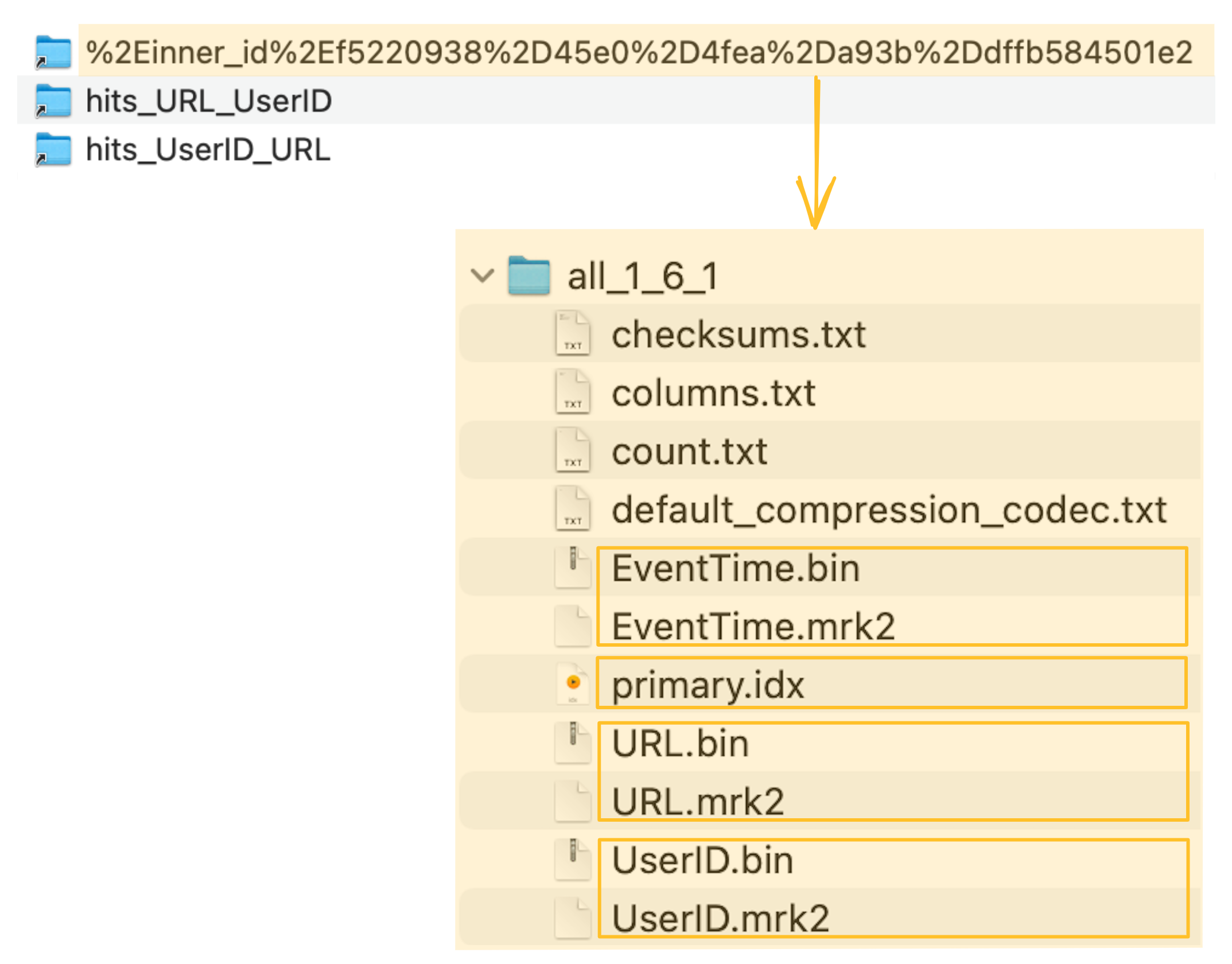
Неявно созданная таблица (и ее первичный индекс), которая поддерживает материализованное представление, теперь может быть использована для значительного ускорения выполнения нашего примерного запроса, фильтрующего по столбцу URL:
Ответ:
Поскольку фактически неявно созданная таблица (и ее первичный индекс), поддерживающая материализованное представление, идентична вторичной таблице, которую мы создали явно, запрос выполняется так же эффективно, как и с явно созданной таблицей.
Соответствующий журнал трассировки в файле журнала сервера ClickHouse подтверждает, что ClickHouse выполняет бинарный поиск по меткам индекса:
Вариант 3: Проекции
Создайте проекцию на нашей существующей таблице:
И материализуйте проекцию:
- проекция создает скрытую таблицу, чья сортировка строк и первичный индекс основаны на данной клаузе
ORDER BYпроекции - скрытая таблица не отображается по запросу
SHOW TABLES - мы используем ключевое слово
MATERIALIZE, чтобы немедленно заполнить скрытую таблицу всеми 8.87 миллионами строк из исходной таблицы hits_UserID_URL - если в исходную таблицу hits_UserID_URL будут добавлены новые строки, то эти строки также автоматически будут вставляться в скрытую таблицу
- запрос всегда (по синтаксису) обращается к исходной таблице hits_UserID_URL, но если порядок строк и первичный индекс скрытой таблицы позволяют более эффективное выполнение запроса, то при этом будет использоваться скрытая таблица
- пожалуйста, обратите внимание, что проекции не делают запросы, использующие ORDER BY, более эффективными, даже если ORDER BY совпадает с ORDER BY утверждением проекции (см. https://github.com/ClickHouse/ClickHouse/issues/47333)
- Эффективно неявно созданная скрытая таблица имеет тот же порядок строк и первичный индекс, что и вторичная таблица, которую мы создали явно:
ClickHouse хранит файлы данных столбцов (.bin), файлы меток (.mrk2) и первичный индекс (primary.idx) скрытой таблицы в специальной папке (отмеченной оранжевым цветом на скриншоте ниже), рядом с файлами данных, файлами меток и файлами первичного индекса исходной таблицы:
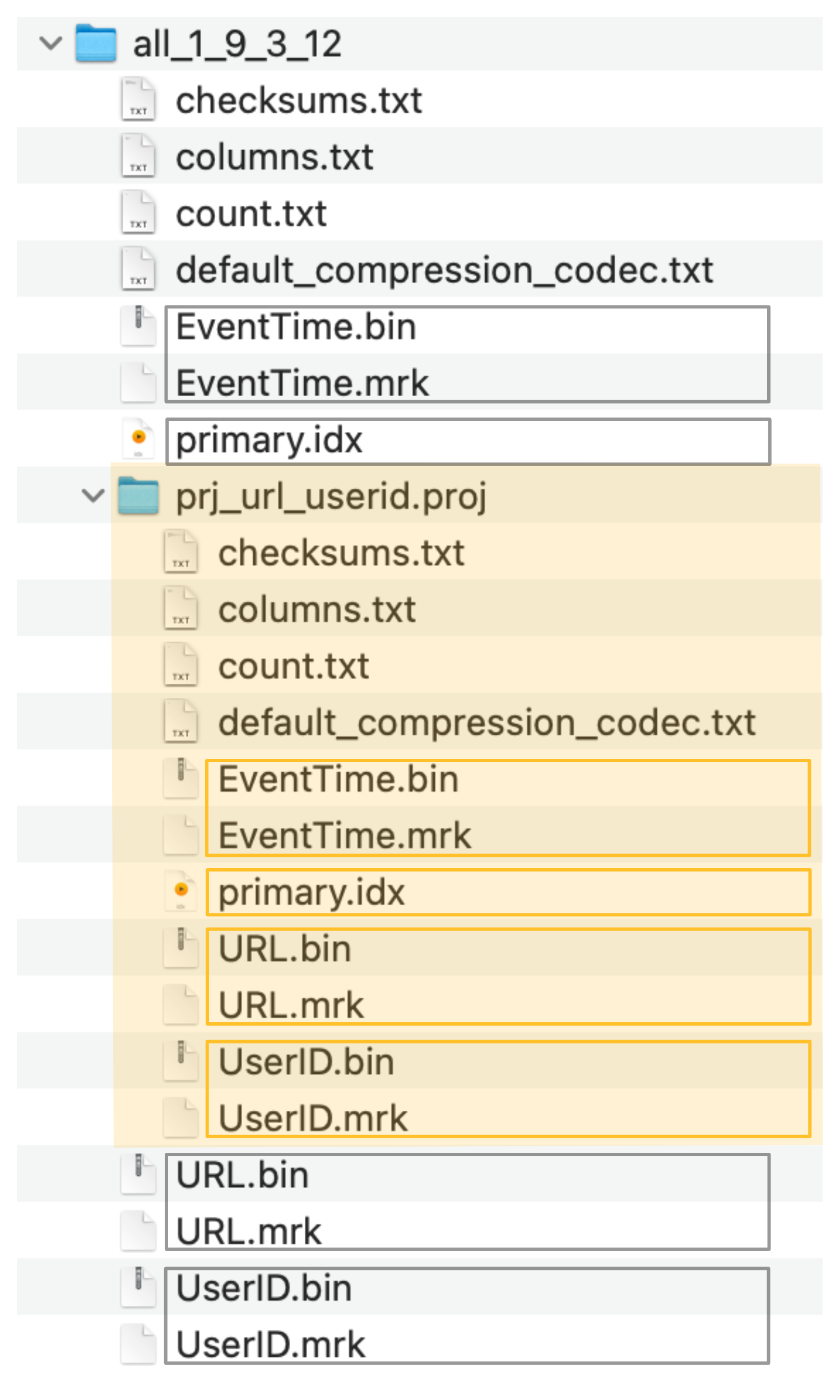
Скрытая таблица (и ее первичный индекс), созданные проекцией, теперь могут (неявно) использоваться для значительного ускорения выполнения нашего примерного запроса, фильтрующего по столбцу URL. Обратите внимание, что запрос по синтаксису обращается к исходной таблице проекции.
Ответ:
Поскольку фактически скрытая таблица (и ее первичный индекс), созданные проекцией, идентичны вторичной таблице, которую мы создали явно, запрос выполняется так же эффективно, как и с явно созданной таблицей.
Соответствующий журнал трассировки в файле журнала сервера ClickHouse подтверждает, что ClickHouse выполняет бинарный поиск по меткам индекса:
Резюме
Первичный индекс нашей таблицы со сложным первичным ключом (UserID, URL) был очень полезен для ускорения запроса с фильтрацией по UserID. Но этот индекс не предоставляет значительной помощи в ускорении запроса с фильтрацией по URL, несмотря на то, что колонка URL является частью сложного первичного ключа.
И наоборот: Первичный индекс нашей таблицы со сложным первичным ключом (URL, UserID) ускорял запрос с фильтрацией по URL, но не предоставлял много поддержки для запроса с фильтрацией по UserID.
Из-за схожей высокой кардинальности колонок первичного ключа UserID и URL, запрос, который фильтрует по второму ключевому столбцу, не извлекает много пользы от того, что второй ключевой столбец находится в индексе.
Поэтому имеет смысл удалить второй ключевой столбец из первичного индекса (что приведет к меньшему потреблению памяти индекса) и использовать несколько первичных индексов вместо этого.
Однако, если ключевые столбцы в сложном первичном ключе имеют большие различия в кардинальности, то это полезно для запросов упорядочить ключевые столбцы по кардинальности в порядке возрастания.
Чем больше разница в кардинальности между ключевыми столбцами, тем больше значения имеет порядок этих столбцов в ключе. Мы продемонстрируем это в следующем разделе.
Эффективное упорядочивание ключевых столбцов
В сложном первичном ключе порядок ключевых столбцов может значительно влиять как на:
- эффективность фильтрации по вторичным ключевым столбцам в запросах, так и
- коэффициент сжатия для файлов данных таблицы.
Чтобы продемонстрировать это, мы используем версию нашего набора данных веб-трафика, где каждая строка содержит три колонки, которые указывают, помечен ли доступ интернет 'пользователя' (UserID колонка) к URL (URL колонка) как бот-трафик (IsRobot колонка).
Мы будем использовать сложный первичный ключ, содержащий все три упомянутые колонки, который может быть использован для ускорения типичных веб-аналитических запросов, которые вычисляют:
- сколько (в процентах) трафика к определенному URL исходит от ботов или
- насколько мы уверены, что конкретный пользователь является (не является) ботом (каков процент трафика от этого пользователя, который (не) предполагается как бот-трафик)
Мы используем этот запрос для вычисления кардинальностей трех колонок, которые мы хотим использовать в качестве ключевых столбцов в сложном первичном ключе (обратите внимание, что мы используем табличную функцию URL для запроса TSV данных без необходимости создавать локальную таблицу). Выполните этот запрос в clickhouse client:
Ответ:
Мы видим, что есть большая разница между кардинальностями, особенно между колонками URL и IsRobot, и поэтому порядок этих колонок в сложном первичном ключе значителен как для эффективного ускорения запросов, фильтрующих по этим колонкам, так и для достижения оптимальных коэффициентов сжатия для файлов данных колонок таблицы.
Чтобы продемонстрировать это, мы создадим две версии таблицы для нашего анализа бот-трафика:
- таблица
hits_URL_UserID_IsRobotсо сложным первичным ключом(URL, UserID, IsRobot), где мы упорядочиваем ключевые столбцы по кардинальности в порядке убывания - таблица
hits_IsRobot_UserID_URLсо сложным первичным ключом(IsRobot, UserID, URL), где мы упорядочиваем ключевые столбцы по кардинальности в порядке возрастания
Создайте таблицу hits_URL_UserID_IsRobot со сложным первичным ключом (URL, UserID, IsRobot):
И заполните её 8.87 миллиона строками:
Вот ответ:
Следующим шагом создайте таблицу hits_IsRobot_UserID_URL со сложным первичным ключом (IsRobot, UserID, URL):
И заполните её теми же 8.87 миллиона строками, которые мы использовали для заполнения предыдущей таблицы:
Ответ:
Эффективная фильтрация по вторичным ключевым столбцам
Когда запрос фильтрует по как минимум одному столбцу, который является частью составного ключа и является первым ключевым столбцом, то ClickHouse выполняет бинарный поиск по индексным меткам ключевого столбца.
Когда запрос фильтрует (только) по столбцу, который является частью составного ключа, но не является первым ключевым столбцом, то ClickHouse использует алгоритм общего исключения по индексным меткам ключевого столбца.
Для второго случая порядок ключевых столбцов в сложном первичном ключе имеет значение для эффективности алгоритма общего исключения.
Это запрос, который фильтрует по колонке UserID таблицы, где мы упорядочили ключевые столбцы (URL, UserID, IsRobot) по кардинальности в порядке убывания:
Ответ:
Это тот же запрос к таблице, где мы упорядочили ключевые столбцы (IsRobot, UserID, URL) по кардинальности в порядке возрастания:
Ответ:
Мы можем увидеть, что выполнение запроса значительно более эффективно и быстрее в таблице, где мы упорядочили ключевые столбцы по кардинальности в порядке возрастания.
Причина этого в том, что алгоритм общего исключения работает наиболее эффективно, когда гранулы выбираются через вторичный ключевой столбец, где предшествующий ключевой столбец имеет более низкую кардинальность. Мы подробно проиллюстрировали это в предыдущем разделе этого руководства.
Оптимальный коэффициент сжатия файлов данных
Этот запрос сравнивает коэффициент сжатия колонки UserID между двумя таблицами, которые мы создали выше:
Ответ:
Мы видим, что коэффициент сжатия для колонки UserID значительно выше для таблицы, где мы упорядочили ключевые столбцы (IsRobot, UserID, URL) по кардинальности в порядке возрастания.
Хотя в обеих таблицах хранится точно одинаковые данные (мы вставили одинаковые 8.87 миллиона строк в обе таблицы), порядок ключевых столбцов в сложном первичном ключе имеет значительное влияние на то, сколько дискового пространства требуют сжатые данные в файлах данных колонок таблицы:
- в таблице
hits_URL_UserID_IsRobotсо сложным первичным ключом(URL, UserID, IsRobot), где мы упорядочили ключевые столбцы по кардинальности в порядке убывания, файл данныхUserID.binзанимает 11.24 MiB дискового пространства - в таблице
hits_IsRobot_UserID_URLсо сложным первичным ключом(IsRobot, UserID, URL), где мы упорядочили ключевые столбцы по кардинальности в порядке возрастания, файл данныхUserID.binзанимает всего 877.47 KiB дискового пространства
Наличие хорошего коэффициента сжатия для данных колонки таблицы на диске не только экономит место на диске, но также ускоряет запросы (особенно аналитические), которые требуют чтения данных из этой колонки, так как требуется меньше ввода-вывода для перемещения данных колонки с диска в оперативную память (кэш файловой системы операционной системы).
В следующем разделе мы иллюстрируем, почему для коэффициента сжатия колонок таблицы имеет смысл упорядочить первичные ключевые столбцы по кардинальности в порядке возрастания.
Диаграмма ниже иллюстрирует порядок строк на диске для первичного ключа, где ключевые столбцы упорядочены по кардинальности в порядке возрастания:

Мы обсуждали, что данные строк таблицы хранятся на диске упорядоченными по ключевым колонкам.
На диаграмме выше строки таблицы (их значения колонок на диске) сначала упорядочены по их значению cl, а строки, имеющие одинаковое значение cl, упорядочены по их значению ch. И поскольку первый ключевой столбец cl имеет низкую кардинальность, вероятно, что есть строки с одинаковым значением cl. И из-за этого также вероятно, что значения ch упорядочены (локально - для строк с одинаковым значением cl).
Если в колонке похожие данные расположены близко друг к другу, например, за счет сортировки, то эти данные будут сжаты лучше. В общем, алгоритм сжатия выигрывает от длины последовательности данных (чем больше данных он видит, тем лучше для сжатия) и локальности (чем более схожи данные, тем лучше коэффициент сжатия).
В противоположность диаграмме выше, диаграмма ниже иллюстрирует порядок строк на диске для первичного ключа, где ключевые столбцы упорядочены по кардинальности в порядке убывания:

Теперь строки таблицы сначала упорядочены по их значению ch, а строки, имеющие одинаковое значение ch, упорядочены по их значению cl.
Но поскольку первый ключевой столбец ch имеет высокую кардинальность, маловероятно, что есть строки с одинаковым значением ch. И, следовательно, также маловероятно, что значения cl упорядочены (локально - для строк с одинаковым значением ch).
Поэтому значения cl, скорее всего, расположены в случайном порядке и, следовательно, имеют плохую локальность и коэффициент сжатия.
Резюме
Как для эффективной фильтрации по вторичным ключевым столбцам в запросах, так и для коэффициента сжатия файлов данных колонок таблицы полезно упорядочить колонки в первичном ключе по их кардинальности в порядке возрастания.
Эффективное выявление отдельных строк
Хотя в общем это не является наилучшим вариантом использования ClickHouse, иногда приложения, построенные на основе ClickHouse, требуют идентификации отдельных строк таблицы ClickHouse.
Интуитивным решением для этого может быть использование колонки UUID с уникальным значением для каждой строки, а для быстрого извлечения строк использовать эту колонку в качестве ключевого столбца.
Для самого быстрого извлечения колонка UUID должна быть первым ключевым столбцом.
Мы обсуждали, что поскольку данные строк таблицы ClickHouse хранятся на диске упорядоченными по первичному ключевому столбцу(ам), наличие колонки с очень высокой кардинальностью (например, колонки UUID) в первичном ключе или в сложном первичном ключе перед колонками с более низкой кардинальностью вредно для коэффициента сжатия других колонок таблицы.
Компромисс между самым быстрым извлечением и оптимальным сжатием данных состоит в использовании сложного первичного ключа, где UUID является последним ключевым столбцом, после колонок с низкой (или такой же) кардинальностью, которые используются для обеспечения хорошего коэффициента сжатия для некоторых колонок таблицы.
Конкретный пример
Одним из конкретных примеров является сервис для хранения текста https://pastila.nl, который разработал Алексей Миловидов и публиковал в блоге.
При каждом изменении текстового поля данные автоматически сохраняются в строку таблицы ClickHouse (одна строка на каждое изменение).
И одним из способов идентифицировать и извлечь (конкретную версию) вставленного контента является использование хеша контента в качестве UUID для строки таблицы, содержащей этот контент.
Следующая диаграмма показывает:
- порядок вставки строк, когда контент изменяется (например, из-за нажатия клавиш для ввода текста в текстовое поле) и
- порядок данных на диске из вставленных строк, когда используется
PRIMARY KEY (hash):

Поскольку колонка hash используется в качестве первичного ключевого столбца,
- конкретные строки можно извлекать очень быстро, но
- строки таблицы (их данные колонок) хранятся на диске, упорядоченные по возрастанию (уникальных и случайных) хеш-значений. Поэтому значения колонки контента также хранятся в случайном порядке без локальности данных, что приводит к субоптимальному коэффициенту сжатия для файла данных колонки контента.
Для того чтобы значительно улучшить коэффициент сжатия для колонки контента, при этом всё равно достигая быстрого извлечения конкретных строк, pastila.nl использует два хеша (и сложный первичный ключ) для идентификации конкретной строки:
- хеш контента, как обсуждалось выше, который уникален для различных данных, и
- локально-чувствительный хеш (отпечаток), который не изменяется при небольших изменениях данных.
Следующая диаграмма показывает:
- порядок вставки строк, когда контент изменяется (например, из-за нажатия клавиш для ввода текста в текстовое поле) и
- порядок данных на диске из вставленных строк, когда используется сложный
PRIMARY KEY (fingerprint, hash):

Теперь строки на диске сначала упорядочены по fingerprint, а для строк с одинаковым значением fingerprint их значение hash определяет окончательный порядок.
Поскольку данные, которые отличаются только небольшими изменениями, получают одно и то же значение fingerprint, похожие данные теперь хранятся на диске близко друг к другу в колонке контента. И это очень хорошо для коэффициента сжатия колонки контента, поскольку алгоритм сжатия в целом выигрывает от локальности данных (чем более схожи данные, тем лучше коэффициент сжатия).
Компромисс заключается в том, что для извлечения конкретной строки требуется два поля (fingerprint и hash), чтобы оптимально использовать первичный индекс, который возникает из сложного PRIMARY KEY (fingerprint, hash).
