Использование JOIN в ClickHouse
ClickHouse имеет полную поддержку JOIN с широким выбором алгоритмов соединения. Чтобы максимизировать производительность, мы рекомендуем следовать рекомендациям по оптимизации соединений, приведенным в этом руководстве.
- Для оптимальной производительности пользователи должны стремиться снизить количество
JOINв запросах, особенно для аналитических рабочих нагрузок в реальном времени, где требуется производительность в миллисекундах. Стремитесь к максимуму 3-4 соединений в запросе. Мы подробно описываем ряд изменений для минимизации соединений в разделе моделирования данных, включая денормализацию, словари и материализованные представления. - В настоящее время ClickHouse не меняет порядок соединений. Всегда убедитесь, что самая маленькая таблица находится с правой стороны Join. Это будет удерживаться в памяти для большинства алгоритмов соединения и обеспечит наименьшие накладные расходы на память для запроса.
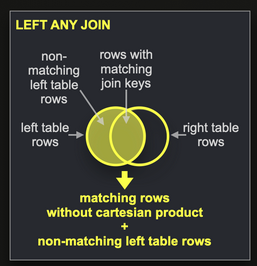
- Если ваш запрос требует прямого соединения, т.е.
LEFT ANY JOIN, как показано ниже, мы рекомендуем использовать Словари, где это возможно.
- Если выполняются внутренние соединения, часто более оптимально записывать их как подзапросы с использованием оператора
IN. Рассмотрим следующие запросы, которые функционально эквивалентны. Оба находят количествоposts, которые не упоминают ClickHouse в вопросе, но упоминают вcomments.
Обратите внимание, что мы используем ANY INNER JOIN вместо простого INNER join, поскольку не хотим получать декартово произведение, т.е. нам нужно только одно совпадение для каждого поста.
Это соединение можно переписать, используя подзапрос, значительно улучшая производительность:
Хотя ClickHouse пытается перенести условия во все положения соединений и подзапросов, мы рекомендуем пользователям всегда вручную применять условия ко всем подусловиям, где это возможно, тем самым минимизируя размер данных для JOIN. Рассмотрим следующий пример, в котором мы хотим вычислить количество голосов "за" для постов, связанных с Java, с 2020 года.
Наивный запрос, с более крупной таблицей с левой стороны, выполняется за 56 секунд:
Изменение порядка этого соединения dramatically улучшает производительность до 1.5 секунд:
Добавление фильтра к таблице с левой стороны еще больше улучшает производительность до 0.5 секунд.
Этот запрос можно улучшить еще больше, переместив INNER JOIN в подзапрос, как отмечалось ранее, сохраняя фильтр как в внешних, так и в внутренних запросах.
Выбор алгоритма JOIN
ClickHouse поддерживает множество алгоритмов соединения. Эти алгоритмы обычно балансируют использование памяти и производительность. Вот общий обзор алгоритмов соединения ClickHouse на основе их относительного потребления памяти и времени выполнения:
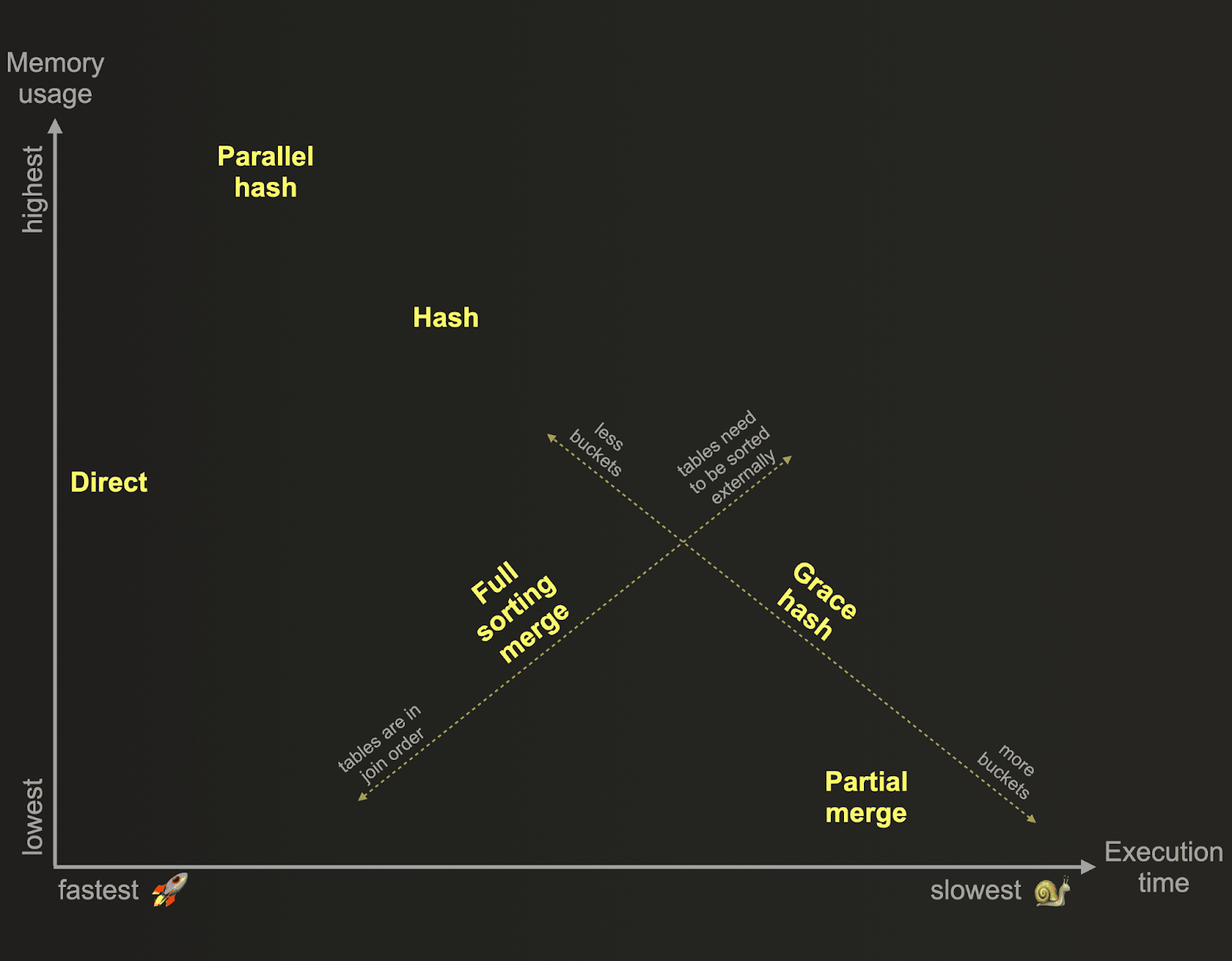
Эти алгоритмы определяют, как планируется и выполняется запрос соединения. По умолчанию ClickHouse использует прямой или хеш-алгоритм соединения в зависимости от используемого типа соединения, строгости и движка присоединенных таблиц. Кроме того, ClickHouse можно настроить таким образом, чтобы он адаптивно выбирал и динамически изменял алгоритм соединения для использования во время выполнения, в зависимости от доступности ресурсов и их использования: Когда join_algorithm=auto, ClickHouse сначала пытается использовать хеш-алгоритм соединения, и если этот алгоритм превышает предельное значение памяти, алгоритм переключается на лету на частичное слияние. Вы можете увидеть, какой алгоритм был выбран, с помощью журналов трассировки. ClickHouse также позволяет пользователям самостоятельно указывать желаемый алгоритм соединения через настройку join_algorithm.
Поддерживаемые типы JOIN для каждого алгоритма соединения показаны ниже и должны быть учтены перед оптимизацией:
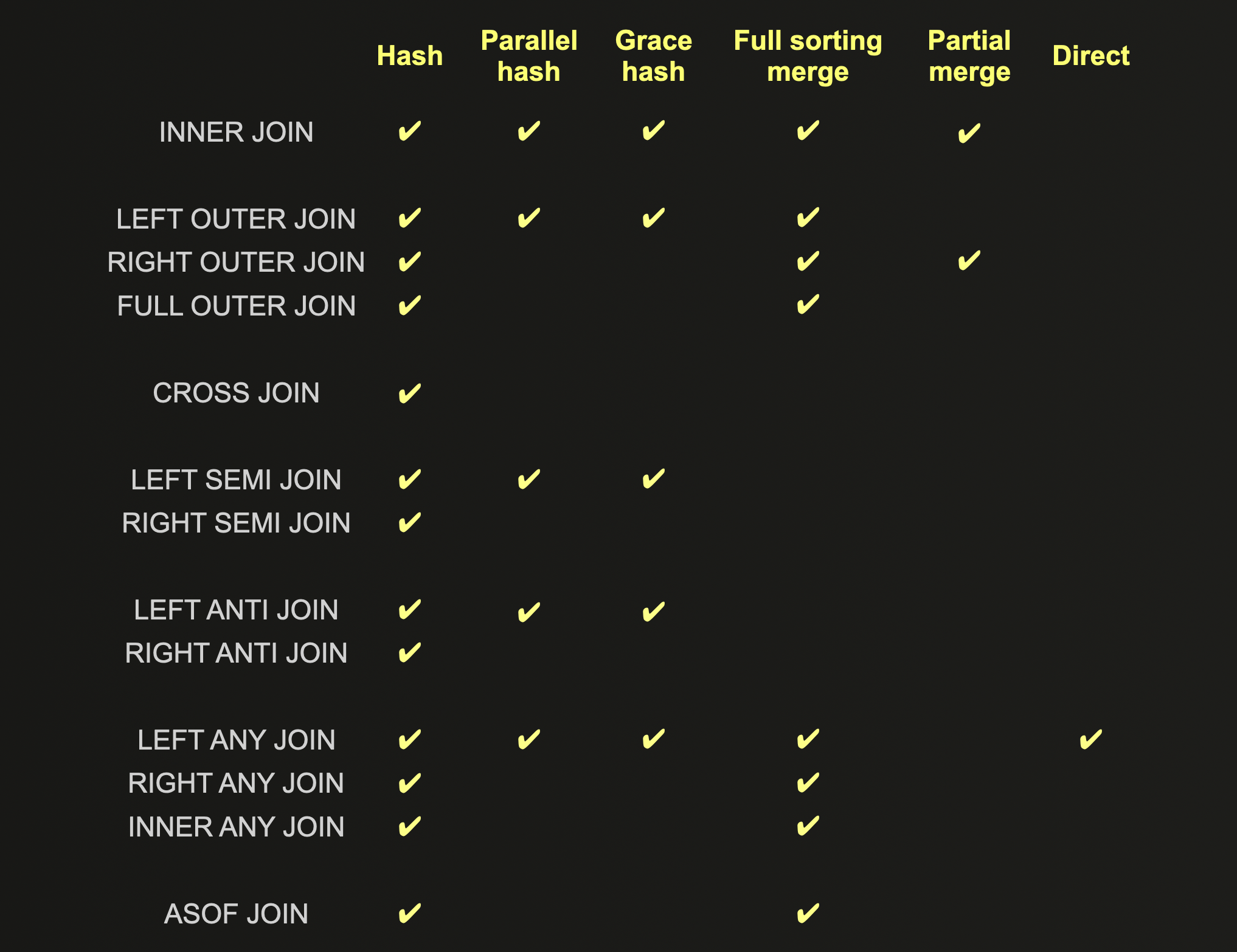
Подробное описание каждого алгоритма JOIN можно найти здесь, включая их плюсы, минусы и свойства масштабирования.
Выбор подходящего алгоритма соединения зависит от того, хотите ли вы оптимизировать под память или производительность.
Оптимизация производительности JOIN
Если ваш ключевой показатель оптимизации — производительность и вы хотите выполнять соединение как можно быстрее, вы можете использовать следующие дерево решений для выбора правильного алгоритма соединения:
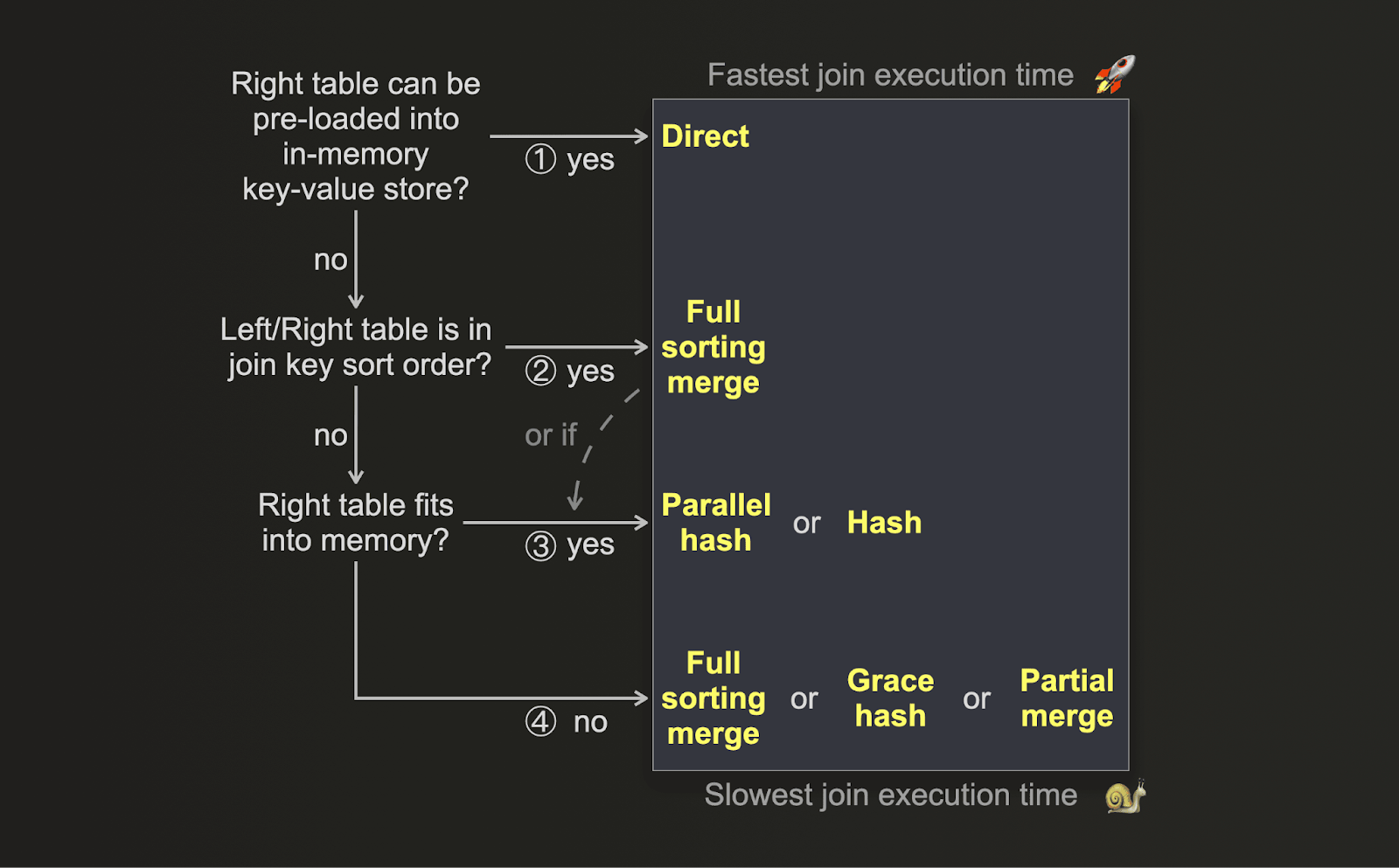
-
(1) Если данные из правой таблицы можно заранее загрузить в структуру данных ключ-значение в памяти с низкой задержкой, например, словарь, и если ключ соединения совпадает с атрибутом ключа базового хранилища ключ-значение, и если семантика
LEFT ANY JOINявляется адекватной, то применим прямой join, который предлагает самый быстрый подход. -
(2) Если физический порядок строк вашей таблицы %physical row order% совпадает с порядком сортировки ключа соединения, то это зависит. В этом случае полное слияние с сортировкой пропускает этап сортировки, что приводит к значительно снижению потребления памяти, а также, в зависимости от размера данных и распределения значений ключа соединения, более быстрым времени выполнения, чем у некоторых хеш-алгоритмов соединения.
-
(3) Если правая таблица помещается в память, даже с дополнительными накладными расходами на память параллельного хеш-join, то этот алгоритм или хеш-join могут быть быстрее. Это зависит от размера данных, типов данных и распределения значений колонок ключа соединения.
-
(4) Если правая таблица не помещается в память, тогда снова зависит. ClickHouse предлагает три алгоритма соединения, не зависящих от памяти. Все три временно сбрасывают данные на диск. Полное слияние с сортировкой и частичное слияние требуют предварительной сортировки данных. Grace hash join вместо этого строит хеш-таблицы из данных. В зависимости от объема данных, типов данных и распределения значений колонок ключа соединения могут быть сценарии, когда построение хеш-таблиц из данных быстрее, чем сортировка данных. И наоборот.
Частичное слияние оптимизировано для минимизации использования памяти при соединении больших таблиц, за счет скорости соединения, которая довольно низка. Это особенно актуально, когда физический порядок строк левой таблицы не совпадает с порядком сортировки ключа соединения.
Grace hash join является наиболее гибким из трех алгоритмов, не зависящих от памяти, и предлагает хороший контроль использования памяти по сравнению со скоростью соединения с помощью настройки grace_hash_join_initial_buckets. В зависимости от объема данных grace hash может быть быстрее или медленнее, чем частичное слияние, когда количество корзин выбрано таким образом, что использование памяти обоих алгоритмов примерно совпадает. Когда использование памяти grace hash join настроено так, чтобы быть примерно согласованным с использованием памяти полного слияния, тогда полное слияние всегда было быстрее в наших тестах.
Какой из трех алгоритмов не зависят от памяти быстрее, зависит от объема данных, типов данных и распределения значений колонок ключа соединения. Всегда лучше провести некоторые бенчмарки с реалистичными объемами данных, чтобы определить, какой алгоритм является самым быстрым.
Оптимизация по памяти
Если вы хотите оптимизировать соединение для минимального использования памяти вместо самой быстрой скорости выполнения, то вы можете использовать вместо этого дерево решений:
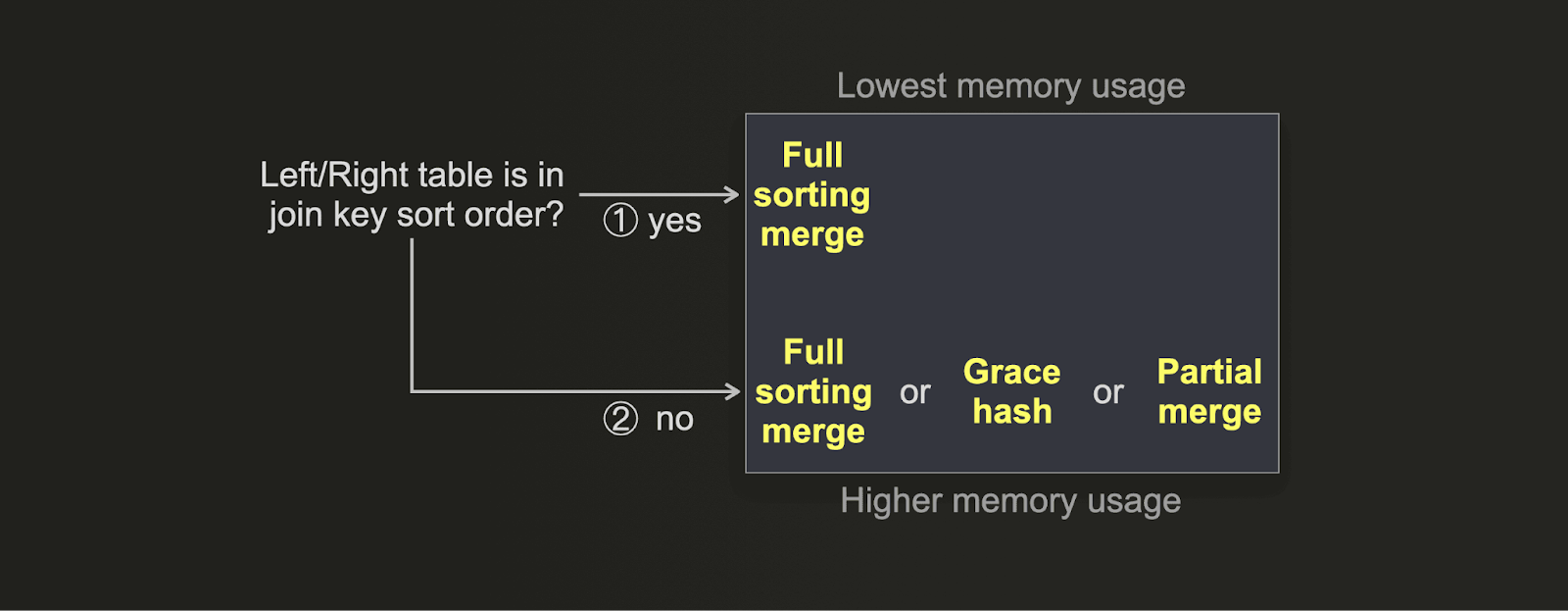
- (1) Если физический порядок строк вашей таблицы совпадает с порядком сортировки ключа соединения, то использование памяти полного слияния с сортировкой будет минимальным. С дополнительным преимуществом хорошей скорости соединения, поскольку этап сортировки отключен.
- (2) Grace hash join может быть настроен для очень низкого использования памяти путем настройки большого количества корзин за счет скорости соединения. Частичное слияние намеренно использует небольшое количество основной памяти. Полное слияние с сортировкой с включенной внешней сортировкой, как правило, использует больше памяти, чем частичное слияние (предполагая, что порядок строк не совпадает с порядком сортировки ключа), с преимуществом значительно лучшего времени выполнения соединения.
Для пользователей, которым нужна более подробная информация по вышеуказанным вопросам, мы рекомендуем следующую серии блогов.
