В этом разделе представлены руководства по настройке dbt и адаптера ClickHouse, а также пример использования dbt с ClickHouse. Пример охватывает следующие шаги:
- Создание проекта dbt и настройка адаптера ClickHouse.
- Определение модели.
- Обновление модели.
- Создание инкрементальной модели.
- Создание модели снимка.
- Использование материализованных представлений.
Эти руководства предназначены для использования в сочетании с остальной частью документации и функциями и конфигурациями.
Настройка
Следуйте инструкциям в разделе Настройка dbt и адаптера ClickHouse, чтобы подготовить вашу среду.
Важно: Следующее тестировалось под Python 3.9.
Подготовка ClickHouse
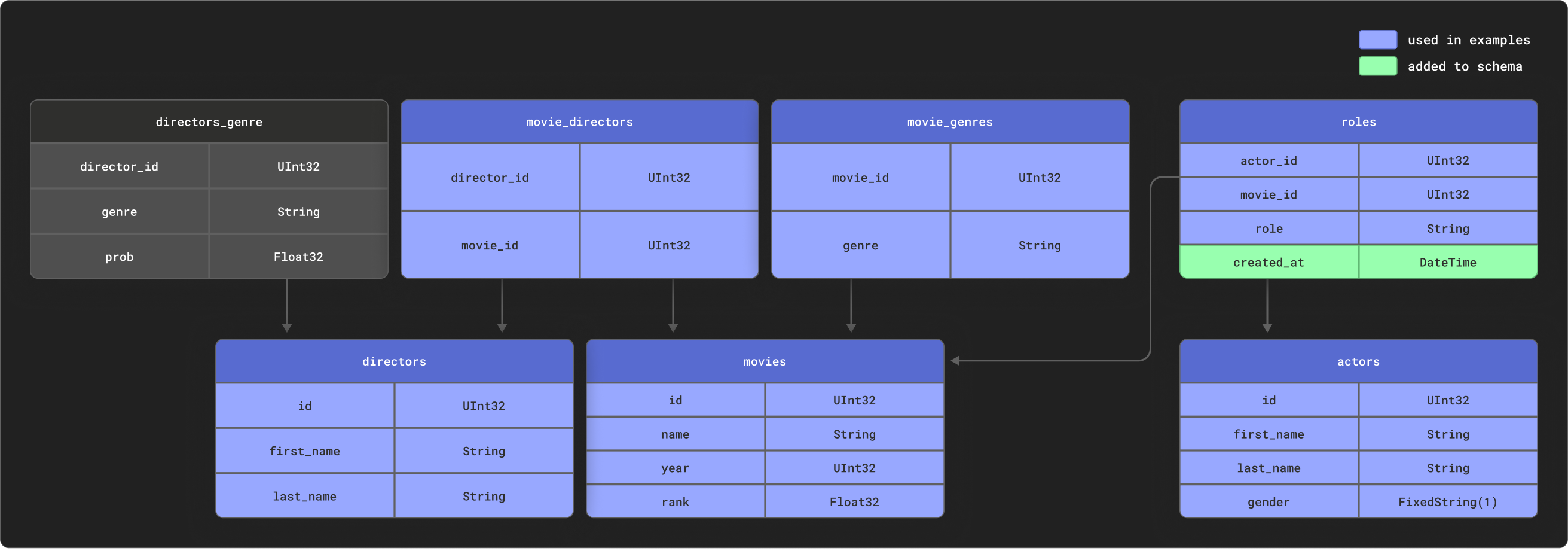
dbt отлично работает с моделированием высоко реляционных данных. В качестве примера мы предоставляем небольшой набор данных IMDB со следующим реляционным планом. Этот набор данных происходит из репозитория реляционных наборов данных. Это тривиально по сравнению с общими схемами, используемыми с dbt, но представляет собой управляемую выборку:
Мы используем подмножество этих таблиц, как показано.
Создайте следующие таблицы:
CREATE DATABASE imdb;
CREATE TABLE imdb.actors
(
id UInt32,
first_name String,
last_name String,
gender FixedString(1)
) ENGINE = MergeTree ORDER BY (id, first_name, last_name, gender);
CREATE TABLE imdb.directors
(
id UInt32,
first_name String,
last_name String
) ENGINE = MergeTree ORDER BY (id, first_name, last_name);
CREATE TABLE imdb.genres
(
movie_id UInt32,
genre String
) ENGINE = MergeTree ORDER BY (movie_id, genre);
CREATE TABLE imdb.movie_directors
(
director_id UInt32,
movie_id UInt64
) ENGINE = MergeTree ORDER BY (director_id, movie_id);
CREATE TABLE imdb.movies
(
id UInt32,
name String,
year UInt32,
rank Float32 DEFAULT 0
) ENGINE = MergeTree ORDER BY (id, name, year);
CREATE TABLE imdb.roles
(
actor_id UInt32,
movie_id UInt32,
role String,
created_at DateTime DEFAULT now()
) ENGINE = MergeTree ORDER BY (actor_id, movie_id);
примечание
Столбец created_at для таблицы roles имеет значение по умолчанию now(). Мы используем это позже, чтобы идентифицировать инкрементальные обновления наших моделей - см. Инкрементальные модели.
Мы используем функцию s3, чтобы прочитать исходные данные из публичных конечных точек для вставки данных. Выполните следующие команды, чтобы заполнить таблицы:
INSERT INTO imdb.actors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_actors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.directors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_directors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.genres
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_genres.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.movie_directors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_directors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.movies
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.roles(actor_id, movie_id, role)
SELECT actor_id, movie_id, role
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_roles.tsv.gz',
'TSVWithNames');
Время выполнения этих команд может варьироваться в зависимости от вашей пропускной способности, но каждая из них должна занимать всего лишь несколько секунд на выполнение. Выполните следующий запрос, чтобы вычислить сводку по каждому актеру, упорядочив по количеству появлений в фильмах, и чтобы подтвердить, что данные были загружены успешно:
SELECT id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS unique_genres,
uniqExact(director_name) AS uniq_directors,
max(created_at) AS updated_at
FROM (
SELECT imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC
LIMIT 5;
Ответ должен выглядеть следующим образом:
+------+------------+----------+------------------+-------------+--------------+-------------------+
|id |name |num_movies|avg_rank |unique_genres|uniq_directors|updated_at |
+------+------------+----------+------------------+-------------+--------------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 14:01:45|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 14:01:46|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 14:01:46|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 14:01:46|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 14:01:46|
+------+------------+----------+------------------+-------------+--------------+-------------------+
В последующих руководствах мы преобразуем этот запрос в модель - материализуем его в ClickHouse как представление и таблицу dbt.
Подключение к ClickHouse
- Создайте проект dbt. В этом случае мы назовем его в честь нашего источника
imdb. Когда вас попросят, выберите clickhouse в качестве источника базы данных.
clickhouse-user@clickhouse:~$ dbt init imdb
16:52:40 Running with dbt=1.1.0
Which database would you like to use?
[1] clickhouse
(Don't see the one you want? https://docs.getdbt.com/docs/available-adapters)
Enter a number: 1
16:53:21 No sample profile found for clickhouse.
16:53:21
Your new dbt project "imdb" was created!
For more information on how to configure the profiles.yml file,
please consult the dbt documentation here:
https://docs.getdbt.com/docs/configure-your-profile
cd в папку вашего проекта:
-
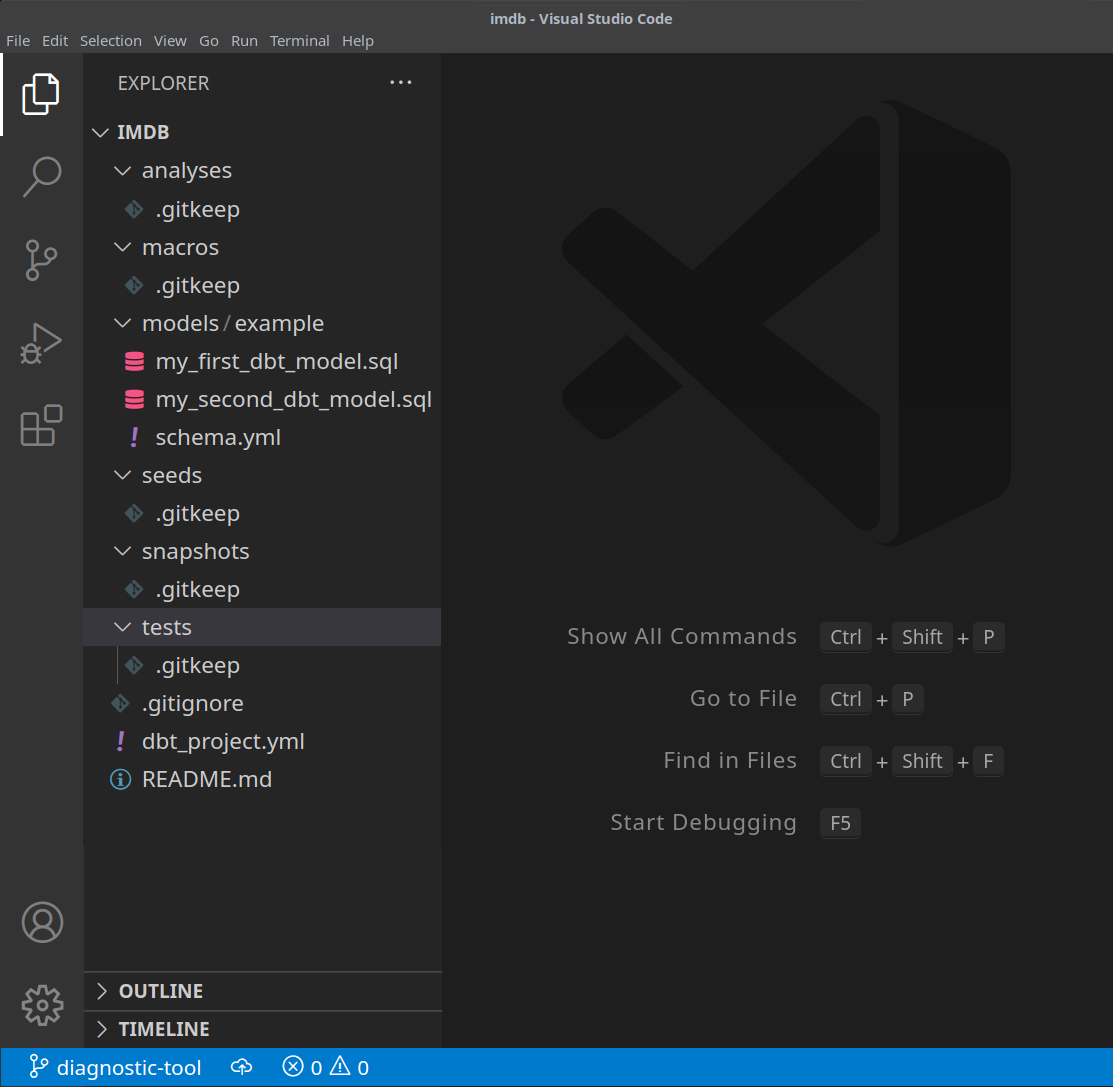
На этом этапе вам потребуется текстовый редактор на ваш выбор. В приведенных ниже примерах мы используем популярный VS Code. Открыв каталог IMDB, вы должны увидеть коллекцию yml и sql файлов:
-
Обновите ваш файл dbt_project.yml, чтобы указать нашу первую модель - actor_summary и установите профиль на clickhouse_imdb.
-
Затем нам нужно предоставить dbt данные для подключения к нашему экземпляру ClickHouse. Добавьте следующее в ваш ~/.dbt/profiles.yml.
clickhouse_imdb:
target: dev
outputs:
dev:
type: clickhouse
schema: imdb_dbt
host: localhost
port: 8123
user: default
password: ''
secure: False
Обратите внимание на необходимость изменить пользователя и пароль. Дополнительные доступные настройки задокументированы здесь.
- Из каталога IMDB выполните команду
dbt debug, чтобы подтвердить, сможет ли dbt подключиться к ClickHouse.
clickhouse-user@clickhouse:~/imdb$ dbt debug
17:33:53 Running with dbt=1.1.0
dbt version: 1.1.0
python version: 3.10.1
python path: /home/dale/.pyenv/versions/3.10.1/bin/python3.10
os info: Linux-5.13.0-10039-tuxedo-x86_64-with-glibc2.31
Using profiles.yml file at /home/dale/.dbt/profiles.yml
Using dbt_project.yml file at /opt/dbt/imdb/dbt_project.yml
Configuration:
profiles.yml file [OK found and valid]
dbt_project.yml file [OK found and valid]
Required dependencies:
- git [OK found]
Connection:
host: localhost
port: 8123
user: default
schema: imdb_dbt
secure: False
verify: False
Connection test: [OK connection ok]
All checks passed!
Подтвердите, что ответ включает Connection test: [OK connection ok], что указывает на успешное подключение.
Создание простой материализации представления
При использовании материализации представления, модель перестраивается как представление при каждом запуске, с помощью оператора CREATE VIEW AS в ClickHouse. Это не требует дополнительного хранения данных, но будет медленнее для запросов, чем материализации таблиц.
- Из папки
imdb удалите каталог models/example:
clickhouse-user@clickhouse:~/imdb$ rm -rf models/example
- Создайте новый файл в каталоге
actors в папке models. Здесь мы создаем файлы, каждый из которых представляет модель актера:
clickhouse-user@clickhouse:~/imdb$ mkdir models/actors
- Создайте файлы
schema.yml и actor_summary.sql в папке models/actors.
clickhouse-user@clickhouse:~/imdb$ touch models/actors/actor_summary.sql
clickhouse-user@clickhouse:~/imdb$ touch models/actors/schema.yml
Файл schema.yml определяет наши таблицы. Они впоследствии будут доступны для использования в макросах. Отредактируйте
models/actors/schema.yml, чтобы содержать этот контент:
version: 2
sources:
- name: imdb
tables:
- name: directors
- name: actors
- name: roles
- name: movies
- name: genres
- name: movie_directors
Файл actors_summary.sql определяет нашу фактическую модель. Обратите внимание, что в функции конфигурации мы также запрашиваем, чтобы модель была материализована как представление в ClickHouse. Наши таблицы ссылаются на файл schema.yml через функцию source, например, source('imdb', 'movies') ссылается на таблицу movies в базе данных imdb. Отредактируйте models/actors/actors_summary.sql, чтобы содержать этот контент:
{{ config(materialized='view') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
Обратите внимание, как мы включаем столбец updated_at в нашу финальную actor_summary. Мы используем это позже для инкрементальных материализаций.
- Из каталога
imdb выполните команду dbt run.
clickhouse-user@clickhouse:~/imdb$ dbt run
15:05:35 Running with dbt=1.1.0
15:05:35 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:05:35
15:05:36 Concurrency: 1 threads (target='dev')
15:05:36
15:05:36 1 of 1 START view model imdb_dbt.actor_summary.................................. [RUN]
15:05:37 1 of 1 OK created view model imdb_dbt.actor_summary............................. [OK in 1.00s]
15:05:37
15:05:37 Finished running 1 view model in 1.97s.
15:05:37
15:05:37 Completed successfully
15:05:37
15:05:37 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
- dbt представит модель как представление в ClickHouse, как и запрашивалось. Теперь мы можем напрямую запрашивать это представление. Это представление будет создано в базе данных
imdb_dbt - это определяется параметром схемы в файле ~/.dbt/profiles.yml под профилем clickhouse_imdb.
+------------------+
|name |
+------------------+
|INFORMATION_SCHEMA|
|default |
|imdb |
|imdb_dbt | <---created by dbt!
|information_schema|
|system |
+------------------+
Запрашивая это представление, мы можем воспроизвести результаты нашего предыдущего запроса с более простой синтаксисом:
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;
+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+
Создание материализации таблицы
В предыдущем примере наша модель была материализована как представление. Хотя это может предложить достаточную производительность для некоторых запросов, более сложные SELECT или часто выполняемые запросы могут лучше материализоваться как таблица. Эта материализация полезна для моделей, которые будут запрашиваться инструментами BI, чтобы обеспечить пользователям более быстрый опыт. Это фактически приводит к тому, что результаты запроса хранятся как новая таблица с сопутствующими накладными расходами на хранение - фактически выполняется INSERT TO SELECT. Обратите внимание, что эта таблица будет перестраиваться каждый раз, т.е. она не инкрементальна. Поэтому большие наборы данных могут привести к длительным временам выполнения - см. Ограничения dbt.
- Измените файл
actors_summary.sql так, чтобы параметр materialized был установлен на table. Обратите внимание, как определяется ORDER BY, и обратите внимание, что мы используем движок таблицы MergeTree:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='table') }}
- Из каталога
imdb выполните команду dbt run. Это выполнение может занять немного больше времени - около 10 секунд на большинстве машин.
clickhouse-user@clickhouse:~/imdb$ dbt run
15:13:27 Running with dbt=1.1.0
15:13:27 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:13:27
15:13:28 Concurrency: 1 threads (target='dev')
15:13:28
15:13:28 1 of 1 START table model imdb_dbt.actor_summary................................. [RUN]
15:13:37 1 of 1 OK created table model imdb_dbt.actor_summary............................ [OK in 9.22s]
15:13:37
15:13:37 Finished running 1 table model in 10.20s.
15:13:37
15:13:37 Completed successfully
15:13:37
15:13:37 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
- Подтвердите создание таблицы
imdb_dbt.actor_summary:
SHOW CREATE TABLE imdb_dbt.actor_summary;
Вы должны увидеть таблицу с соответствующими типами данных:
+----------------------------------------
|statement
+----------------------------------------
|CREATE TABLE imdb_dbt.actor_summary
|(
|`id` UInt32,
|`first_name` String,
|`last_name` String,
|`num_movies` UInt64,
|`updated_at` DateTime
|)
|ENGINE = MergeTree
|ORDER BY (id, first_name, last_name)
+----------------------------------------
- Подтвердите, что результаты из этой таблицы согласуются с предыдущими ответами. Обратите внимание на значительное улучшение времени ответа теперь, когда модель является таблицей:
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;
+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+
Не стесняйтесь выполнять другие запросы к этой модели. Например, какие актеры имеют фильмы с самым высоким рейтингом и более чем 5 появлениями?
SELECT * FROM imdb_dbt.actor_summary WHERE num_movies > 5 ORDER BY avg_rank DESC LIMIT 10;
Создание инкрементальной материализации
В предыдущем примере была создана таблица для материализации модели. Эта таблица будет перестраиваться для каждого выполнения dbt. Это может быть непрактично и крайне затратно для больших наборов данных или сложных преобразований. Чтобы решить эту проблему и сократить время сборки, dbt предлагает инкрементальные материализации. Это позволяет dbt вставлять или обновлять записи в таблице с момента последнего выполнения, что подходит для событийных данных. Результатом явится создание временной таблицы со всеми обновленными записями, после чего все неизмененные записи и обновленные записи вставляются в новую целевую таблицу. Это приводит к аналогичным ограничениям для больших наборов данных, как и для модели таблицы.
Чтобы преодолеть эти ограничения для больших наборов, адаптер поддерживает режим 'inserts_only', при котором все обновления вставляются в целевую таблицу без создания временной таблицы (подробнее об этом ниже).
Чтобы проиллюстрировать этот пример, мы добавим актера "Clicky McClickHouse", который появится в невероятных 910 фильмах - обеспечивая, чтобы он появился в большем количестве фильмов, чем даже Мел Бланк.
-
Сначала мы модифицируем нашу модель так, чтобы она была инкрементального типа. Эта добавка требует:
- unique_key - Чтобы адаптер мог уникально идентифицировать строки, мы должны предоставить уникальный ключ - в данном случае поле
id из нашего запроса будет достаточным. Это гарантирует, что у нас не будет дубликатов строк в нашей материализованной таблице. Более подробную информацию о ограничениях уникальности смотрите здесь.
- Инкрементальный фильтр - Мы также должны сообщить dbt, как ему следует определять, какие строки изменились при инкрементальном запуске. Это достигается путем предоставления дельта-выражения. Обычно это связано с временной меткой для событийных данных; поэтому мы используем наш временной столбец
updated_at. Этот столбец, который по умолчанию имеет значение now() при вставке строк, позволяет идентифицировать новые роли. Кроме того, нам необходимо определить альтернативный случай, когда добавляются новые актеры. Используя переменную {{this}}, чтобы обозначить существующую материализованную таблицу, мы получаем выражение where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}}). Мы встраиваем это внутри условия {% if is_incremental() %}, гарантируя, что оно будет использоваться только при инкрементальных запусках, а не при первом создании таблицы. Для получения дополнительной информации о фильтрации строк для инкрементальных моделей смотрите это обсуждение в документации dbt.
Обновите файл actor_summary.sql следующим образом:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})
{% endif %}
Обратите внимание, что наша модель будет реагировать только на обновления и добавления в таблицы roles и actors. Чтобы реагировать на все таблицы, пользователям рекомендуется разделить эту модель на несколько подмоделей - каждая из которых с собственными инкрементальными критериями. Эти модели могут, в свою очередь, ссылаться и соединяться. Для получения дополнительных сведений о перекрестных ссылках на модели смотрите здесь.
- Выполните
dbt run и подтвердите результаты полученной таблицы:
clickhouse-user@clickhouse:~/imdb$ dbt run
15:33:34 Running with dbt=1.1.0
15:33:34 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:33:34
15:33:35 Concurrency: 1 threads (target='dev')
15:33:35
15:33:35 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
15:33:41 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 6.33s]
15:33:41
15:33:41 Finished running 1 incremental model in 7.30s.
15:33:41
15:33:41 Completed successfully
15:33:41
15:33:41 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;
+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+
- Теперь мы добавим данные к нашей модели, чтобы проиллюстрировать инкрементальное обновление. Добавьте нашего актера "Clicky McClickHouse" в таблицу
actors:
INSERT INTO imdb.actors VALUES (845466, 'Clicky', 'McClickHouse', 'M');
- Давайте сделаем так, чтобы "Clicky" снялся в 910 случайных фильмах:
INSERT INTO imdb.roles
SELECT now() as created_at, 845466 as actor_id, id as movie_id, 'Himself' as role
FROM imdb.movies
LIMIT 910 OFFSET 10000;
- Убедитесь, что он действительно сейчас является актером с наибольшим числом появлений, выполнив запрос к исходной таблице и обойдя любые модели dbt:
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as unique_genres,
uniqExact(director_name) as uniq_directors,
max(created_at) as updated_at
FROM (
SELECT imdb.actors.id as id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) as actor_name,
imdb.movies.id as movie_id,
imdb.movies.rank as rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) as director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC
LIMIT 2;
+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
- Выполните
dbt run и подтвердите, что наша модель была обновлена и соответствует приведенным выше результатам:
clickhouse-user@clickhouse:~/imdb$ dbt run
16:12:16 Running with dbt=1.1.0
16:12:16 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
16:12:16
16:12:17 Concurrency: 1 threads (target='dev')
16:12:17
16:12:17 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
16:12:24 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 6.82s]
16:12:24
16:12:24 Finished running 1 incremental model in 7.79s.
16:12:24
16:12:24 Completed successfully
16:12:24
16:12:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 2;
+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
Внутреннее устройство
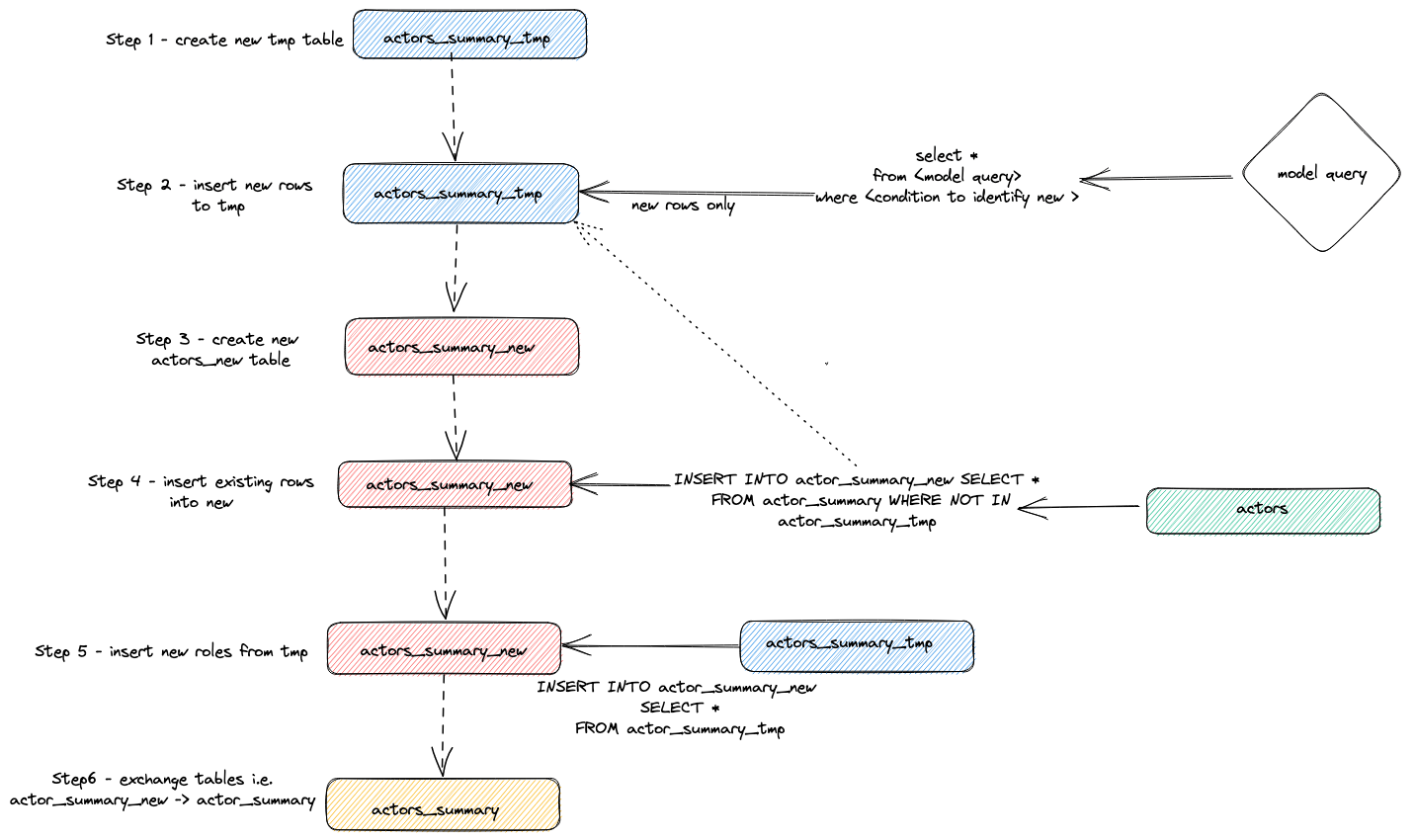
Мы можем идентифицировать выполняемые операторы для достижения вышеуказанного инкрементального обновления, запрашивая журнал запросов ClickHouse.
SELECT event_time, query FROM system.query_log WHERE type='QueryStart' AND query LIKE '%dbt%'
AND event_time > subtractMinutes(now(), 15) ORDER BY event_time LIMIT 100;
Настройте вышеуказанный запрос на период выполнения. Мы оставляем проверку результата пользователю, но подчеркиваем общую стратегию, используемую адаптером для выполнения инкрементальных обновлений:
- Адаптер создает временную таблицу
actor_sumary__dbt_tmp. Измененные строки передаются в эту таблицу.
- Создается новая таблица
actor_summary_new, строки из старой таблицы, в свою очередь, передаются из старой в новую таблицу с проверкой, чтобы гарантировать, что идентификаторы строк не существуют во временной таблице. Это эффективно обрабатывает обновления и дубликаты.
- Результаты из временной таблицы передаются в новую таблицу
actor_summary.
- В конце новая таблица атомарно меняется на старую версию через оператор
EXCHANGE TABLES. Старая и временные таблицы при этом удаляются.
Это визуализировано ниже:
Эта стратегия может столкнуться с проблемами при очень больших моделях. Для получения дополнительной информации смотрите Ограничения.
Стратегия добавления (режим только вставки)
Чтобы преодолеть ограничения больших наборов данных в инкрементальных моделях, адаптер использует параметр конфигурации dbt incremental_strategy. Это может быть установлено на значение append. Когда установлено, обновленные строки вставляются непосредственно в целевую таблицу (также известную как imdb_dbt.actor_summary), и временная таблица не создается.
Обратите внимание: режим только добавления требует, чтобы ваши данные были неизменяемыми или чтобы дубликаты были приемлемыми. Если вы хотите инкрементальную модель таблицы, которая поддерживает изменённые строки, не используйте этот режим!
Чтобы проиллюстрировать этот режим, мы добавим еще одного нового актера и повторно выполним dbt run с incremental_strategy='append'.
- Настройте режим только добавления в actor_summary.sql:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='append') }}
- Давайте добавим другого известного актера - Дэнни ДеВито.
INSERT INTO imdb.actors VALUES (845467, 'Danny', 'DeBito', 'M');
- Давайте сделаем так, чтобы Дэнни снялся в 920 случайных фильмах.
INSERT INTO imdb.roles
SELECT now() as created_at, 845467 as actor_id, id as movie_id, 'Himself' as role
FROM imdb.movies
LIMIT 920 OFFSET 10000;
- Выполните dbt run и подтвердите, что Дэнни был добавлен в таблицу actor-summary.
clickhouse-user@clickhouse:~/imdb$ dbt run
16:12:16 Running with dbt=1.1.0
16:12:16 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 186 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
16:12:16
16:12:17 Concurrency: 1 threads (target='dev')
16:12:17
16:12:17 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
16:12:24 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 0.17s]
16:12:24
16:12:24 Finished running 1 incremental model in 0.19s.
16:12:24
16:12:24 Completed successfully
16:12:24
16:12:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 3;
+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845467|Danny DeBito |920 |1.4768987303293204|21 |670 |2022-04-26 16:22:06|
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
Обратите внимание, насколько быстрее было это инкрементальное обновление по сравнению с вставкой "Clicky".
Проверка снова журнала запросов показывает различия между двумя инкрементальными запусками:
INSERT INTO imdb_dbt.actor_summary ("id", "name", "num_movies", "avg_rank", "genres", "directors", "updated_at")
WITH actor_summary AS (
SELECT id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS genres,
uniqExact(director_name) AS directors,
max(created_at) AS updated_at
FROM (
SELECT imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
)
SELECT *
FROM actor_summary
-- this filter will only be applied on an incremental run
WHERE id > (SELECT max(id) FROM imdb_dbt.actor_summary) OR updated_at > (SELECT max(updated_at) FROM imdb_dbt.actor_summary)
В этом запуске только новые строки добавляются напрямую в таблицу imdb_dbt.actor_summary, и создание таблицы не принимается во внимание.
Режим удаления и вставки (экспериментальный)
Исторически ClickHouse имел только ограниченную поддержку обновлений и удалений в виде асинхронных мутаций. Эти операции могут быть чрезмерно требовательными к вводу-выводу и обычно должны избегаться.
ClickHouse 22.8 представил легковесные удаления, а ClickHouse 25.7 представил легковесные обновления. С введением этих функций, изменения от одиночных запросов на обновление, даже при асинхронной материализации, будут происходить мгновенно с точки зрения пользователя.
Этот режим может быть настроен для модели с помощью параметра incremental_strategy, т.е.
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='delete+insert') }}
Эта стратегия работает напрямую с таблицей целевой модели, поэтому, если возникнет проблема во время операции, данные в инкрементальной модели, вероятно, окажутся в недействительном состоянии - атомарного обновления не происходит.
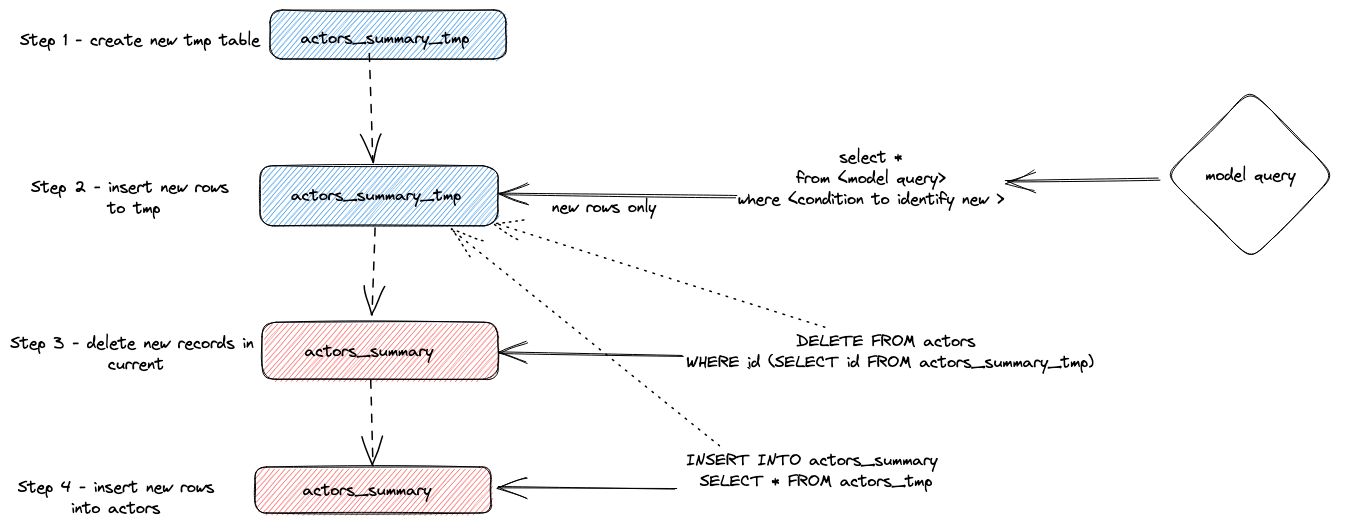
В summary, этот подход:
- Адаптер создает временную таблицу
actor_sumary__dbt_tmp. Измененные строки передаются в эту таблицу.
- Выполняется
DELETE на текущей таблице actor_summary. Строки удаляются по идентификатору из actor_sumary__dbt_tmp.
- Строки из
actor_sumary__dbt_tmp вставляются в actor_summary с помощью INSERT INTO actor_summary SELECT * FROM actor_sumary__dbt_tmp.
Этот процесс представлен ниже:
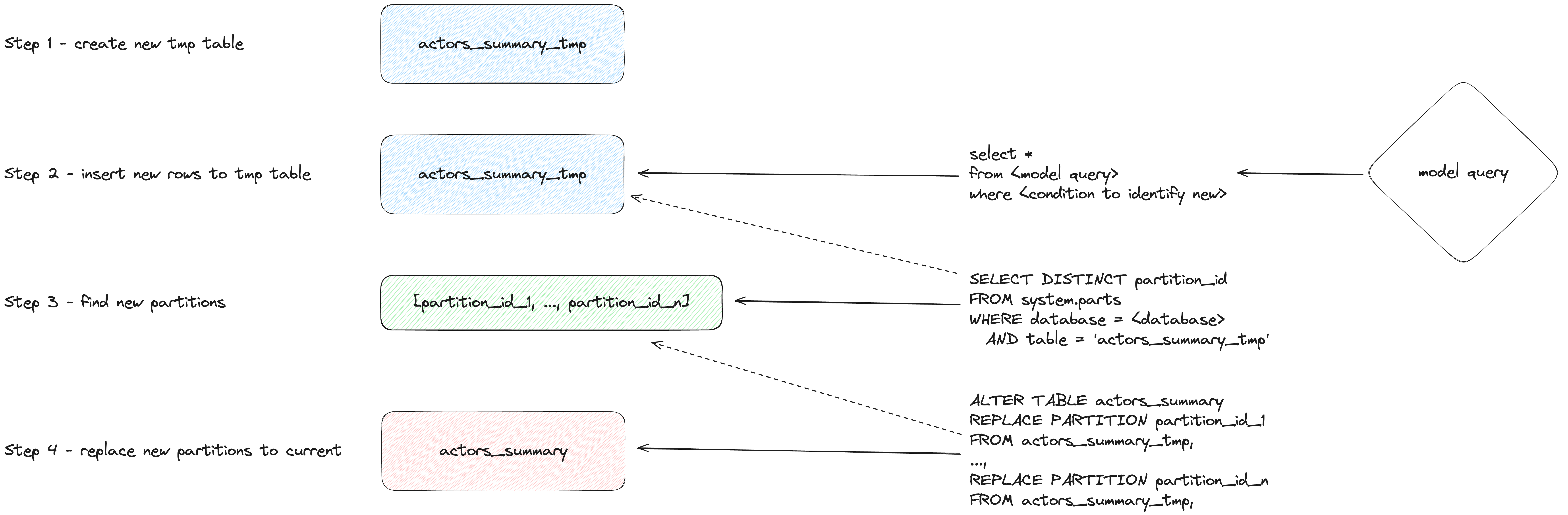
Режим вставки и перезаписи (экспериментальный)
Выполняет следующие шаги:
- Создает временную (постоянную) таблицу с такой же структурой, как инкрементальная модель:
CREATE TABLE {staging} AS {target}.
- Вставляет только новые записи (произведенные с помощью SELECT) во временную таблицу.
- Заменяет только новые партиции (находящиеся во временной таблице) в целевой таблице.
Этот подход имеет следующие преимущества:
- Он быстрее, чем стратегия по умолчанию, потому что не требует копирования всей таблицы.
- Он безопаснее, чем другие стратегии, потому что не изменяет оригинальную таблицу, пока операция INSERT успешно не завершена: в случае промежуточного сбоя оригинальная таблица не изменяется.
- Он реализует лучшие практики инженерии данных "неизменяемости партиций". Что упрощает инкрементальную и параллельную обработку данных, отмену и так далее.
Создание снимка
Снимки dbt позволяют вести учет изменений в изменяемой модели с течением времени. Это, в свою очередь, позволяет выполнять запросы на модели в момент времени, когда аналитики могут "посмотреть назад" на предыдущее состояние модели. Это достигается с использованием типа 2 Постепенно Изменяющиеся Размерности, где столбцы from и to фиксируют, когда строка была действительна. Эта функциональность поддерживается адаптером ClickHouse и демонстрируется ниже.
Этот пример предполагает, что вы завершили Создание инкрементальной модели таблицы. Убедитесь, что ваш файл actor_summary.sql не устанавливает inserts_only=True. Ваши models/actor_summary.sql должны выглядеть так:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})
{% endif %}
- Создайте файл
actor_summary в каталоге снимков.
touch snapshots/actor_summary.sql
- Обновите содержимое файла actor_summary.sql следующим содержимым:
{% snapshot actor_summary_snapshot %}
{{
config(
target_schema='snapshots',
unique_key='id',
strategy='timestamp',
updated_at='updated_at',
)
}}
select * from {{ref('actor_summary')}}
{% endsnapshot %}
Несколько замечаний относительно этого содержимого:
- Запрос select определяет результаты, которые вы хотите фиксировать с течением времени. Функция ref используется для ссылки на ранее созданную модель actor_summary.
- Нам требуется столбец временной метки, чтобы указать изменения записи. Наш столбец updated_at (см. Создание инкрементальной модели таблицы) может быть использован здесь. Параметр стратегии указывает на использование временной метки для обозначения обновлений, с параметром updated_at, указывающим, какой столбец использовать. Если он отсутствует в вашей модели, вы можете использовать стратегию проверки. Это значительно менее эффективно и требует от пользователя указать список столбцов для сравнения. dbt сравнивает текущие и исторические значения этих столбцов, фиксируя любые изменения (или ничего не делает, если они идентичны).
- Выполните команду
dbt snapshot.
clickhouse-user@clickhouse:~/imdb$ dbt snapshot
13:26:23 Running with dbt=1.1.0
13:26:23 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:26:23
13:26:25 Concurrency: 1 threads (target='dev')
13:26:25
13:26:25 1 of 1 START snapshot snapshots.actor_summary_snapshot...................... [RUN]
13:26:25 1 of 1 OK snapshotted snapshots.actor_summary_snapshot...................... [OK in 0.79s]
13:26:25
13:26:25 Finished running 1 snapshot in 2.11s.
13:26:25
13:26:25 Completed successfully
13:26:25
13:26:25 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
Обратите внимание, что в базе данных снимков была создана таблица actor_summary_snapshot (определяемая параметром target_schema).
- При выборке этих данных вы увидите, как dbt включила столбцы dbt_valid_from и dbt_valid_to. Последний имеет значения, установленные в null. Последующие запуски обновят это.
SELECT id, name, num_movies, dbt_valid_from, dbt_valid_to FROM snapshots.actor_summary_snapshot ORDER BY num_movies DESC LIMIT 5;
+------+----------+------------+----------+-------------------+------------+
|id |first_name|last_name |num_movies|dbt_valid_from |dbt_valid_to|
+------+----------+------------+----------+-------------------+------------+
|845467|Danny |DeBito |920 |2022-05-25 19:33:32|NULL |
|845466|Clicky |McClickHouse|910 |2022-05-25 19:32:34|NULL |
|45332 |Mel |Blanc |909 |2022-05-25 19:31:47|NULL |
|621468|Bess |Flowers |672 |2022-05-25 19:31:47|NULL |
|283127|Tom |London |549 |2022-05-25 19:31:47|NULL |
+------+----------+------------+----------+-------------------+------------+
- Давайте заставим нашего любимого актера Clicky McClickHouse появиться еще в 10 фильмах.
INSERT INTO imdb.roles
SELECT now() as created_at, 845466 as actor_id, rand(number) % 412320 as movie_id, 'Himself' as role
FROM system.numbers
LIMIT 10;
- Повторно выполните команду dbt run из каталога
imdb. Это обновит инкрементальную модель. После завершения выполните dbt snapshot, чтобы зафиксировать изменения.
clickhouse-user@clickhouse:~/imdb$ dbt run
13:46:14 Running with dbt=1.1.0
13:46:14 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:46:14
13:46:15 Concurrency: 1 threads (target='dev')
13:46:15
13:46:15 1 of 1 START incremental model imdb_dbt.actor_summary....................... [RUN]
13:46:18 1 of 1 OK created incremental model imdb_dbt.actor_summary.................. [OK in 2.76s]
13:46:18
13:46:18 Finished running 1 incremental model in 3.73s.
13:46:18
13:46:18 Completed successfully
13:46:18
13:46:18 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
clickhouse-user@clickhouse:~/imdb$ dbt snapshot
13:46:26 Running with dbt=1.1.0
13:46:26 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:46:26
13:46:27 Concurrency: 1 threads (target='dev')
13:46:27
13:46:27 1 of 1 START snapshot snapshots.actor_summary_snapshot...................... [RUN]
13:46:31 1 of 1 OK snapshotted snapshots.actor_summary_snapshot...................... [OK in 4.05s]
13:46:31
13:46:31 Finished running 1 snapshot in 5.02s.
13:46:31
13:46:31 Completed successfully
13:46:31
13:46:31 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
- Если мы теперь запрашиваем наш снимок, обратите внимание, что у нас есть 2 строки для Clicky McClickHouse. Наша предыдущая запись теперь имеет значение dbt_valid_to. Наша новая запись зафиксирована с тем же значением в столбце dbt_valid_from и значением dbt_valid_to, равным null. Если бы у нас были новые строки, они также были бы добавлены в снимок.
SELECT id, name, num_movies, dbt_valid_from, dbt_valid_to FROM snapshots.actor_summary_snapshot ORDER BY num_movies DESC LIMIT 5;
+------+----------+------------+----------+-------------------+-------------------+
|id |first_name|last_name |num_movies|dbt_valid_from |dbt_valid_to |
+------+----------+------------+----------+-------------------+-------------------+
|845467|Danny |DeBito |920 |2022-05-25 19:33:32|NULL |
|845466|Clicky |McClickHouse|920 |2022-05-25 19:34:37|NULL |
|845466|Clicky |McClickHouse|910 |2022-05-25 19:32:34|2022-05-25 19:34:37|
|45332 |Mel |Blanc |909 |2022-05-25 19:31:47|NULL |
|621468|Bess |Flowers |672 |2022-05-25 19:31:47|NULL |
+------+----------+------------+----------+-------------------+-------------------+
Для получения дополнительной информации о снимках dbt смотрите здесь.
Использование семян
dbt предоставляет возможность загружать данные из CSV файлов. Эта возможность не подходит для загрузки больших экспортов баз данных и больше предназначена для небольших файлов, которые обычно используются для кодовых таблиц и словарей, например, для сопоставления кодов стран с названиями стран. Для простого примера мы сгенерируем и загрузим список кодов жанра с помощью функционала семян.
- Мы генерируем список кодов жанра из нашего существующего набора данных. Из каталога dbt используйте
clickhouse-client, чтобы создать файл seeds/genre_codes.csv:
clickhouse-user@clickhouse:~/imdb$ clickhouse-client --password <password> --query
"SELECT genre, ucase(substring(genre, 1, 3)) as code FROM imdb.genres GROUP BY genre
LIMIT 100 FORMAT CSVWithNames" > seeds/genre_codes.csv
- Выполните команду
dbt seed. Это создаст новую таблицу genre_codes в нашей базе данных imdb_dbt (как определено нашей конфигурацией схемы) с строками из нашего csv файла.
clickhouse-user@clickhouse:~/imdb$ dbt seed
17:03:23 Running with dbt=1.1.0
17:03:23 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 1 seed file, 6 sources, 0 exposures, 0 metrics
17:03:23
17:03:24 Concurrency: 1 threads (target='dev')
17:03:24
17:03:24 1 of 1 START seed file imdb_dbt.genre_codes..................................... [RUN]
17:03:24 1 of 1 OK loaded seed file imdb_dbt.genre_codes................................. [INSERT 21 in 0.65s]
17:03:24
17:03:24 Finished running 1 seed in 1.62s.
17:03:24
17:03:24 Completed successfully
17:03:24
17:03:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
- Подтвердите, что они были загружены:
SELECT * FROM imdb_dbt.genre_codes LIMIT 10;
+-------+----+
|genre |code|
+-------+----+
|Drama |DRA |
|Romance|ROM |
|Short |SHO |
|Mystery|MYS |
|Adult |ADU |
|Family |FAM |
|Action |ACT |
|Sci-Fi |SCI |
|Horror |HOR |
|War |WAR |
+-------+----+=