Интеграция Amazon Glue с ClickHouse и Spark
Amazon Glue — это полностью управляемый, безсерверный сервис интеграции данных, предоставляемый Amazon Web Services (AWS). Он упрощает процесс обнаружения, подготовки и преобразования данных для аналитики, машинного обучения и разработки приложений.
Установка
Чтобы интегрировать ваш код Glue с ClickHouse, вы можете использовать наш официальный Spark коннектор в Glue через один из следующих способов:
- Установить ClickHouse Glue коннектор из AWS Marketplace (рекомендуется).
- Вручную добавить JAR-файлы Spark Connector в вашу задачу Glue.
- AWS Marketplace
- Ручная установка
-
Подписка на коннектор
Чтобы получить доступ к коннектору в вашем аккаунте, подпишитесь на ClickHouse AWS Glue Connector из AWS Marketplace. -
Предоставьте необходимые разрешения
Убедитесь, что IAM роль вашей задачи Glue имеет необходимые разрешения, как описано в руководстве по минимальным привилегиям. -
Активируйте коннектор и создайте подключение
Вы можете активировать коннектор и создать подключение, нажав на эту ссылку, которая открывает страницу создания соединения Glue с предзаполненными ключевыми полями. Дайте соединению имя и нажмите создать (не нужно предоставлять детали подключения ClickHouse на этом этапе). -
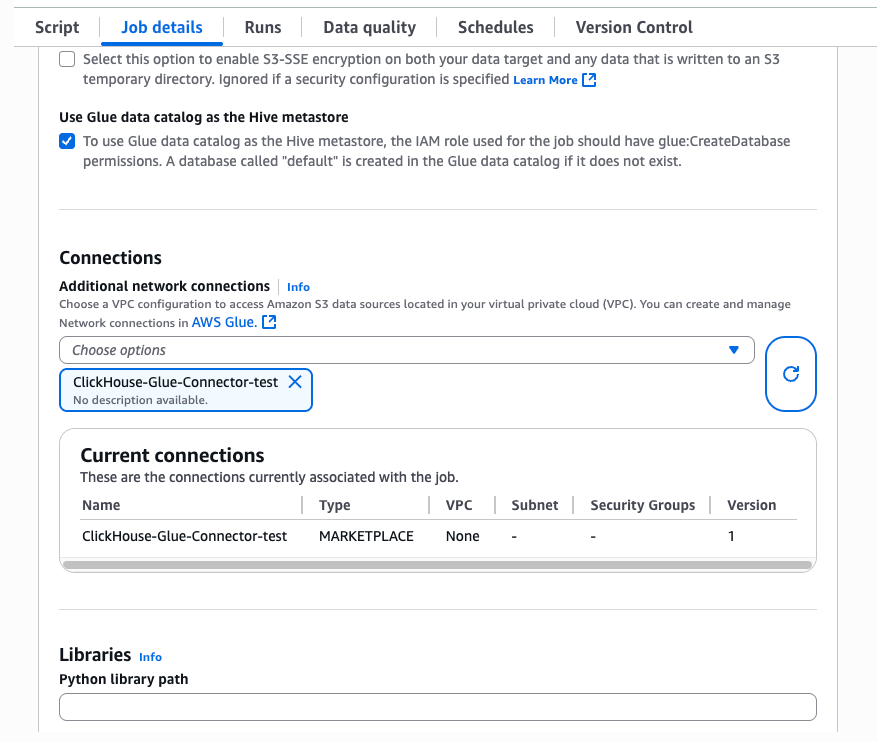
Использование в задаче Glue
В вашей задаче Glue выберите вкладкуJob detailsи разверните окноAdvanced properties. В разделеConnectionsвыберите только что созданное соединение. Коннектор автоматически внедрит необходимые JAR-файлы в выполнение задачи.
примечание
JAR-файлы, используемые в коннекторе Glue, построены для Spark 3.3, Scala 2 и Python 3. Убедитесь, что вы выбрали эти версии при настройке вашей задачи Glue.
Чтобы вручную добавить необходимые JAR-файлы, выполните следующее:
- Загрузите следующие JAR-файлы в S3 корзину -
clickhouse-jdbc-0.6.X-all.jarиclickhouse-spark-runtime-3.X_2.X-0.8.X.jar. - Убедитесь, что задача Glue имеет доступ к этой корзине.
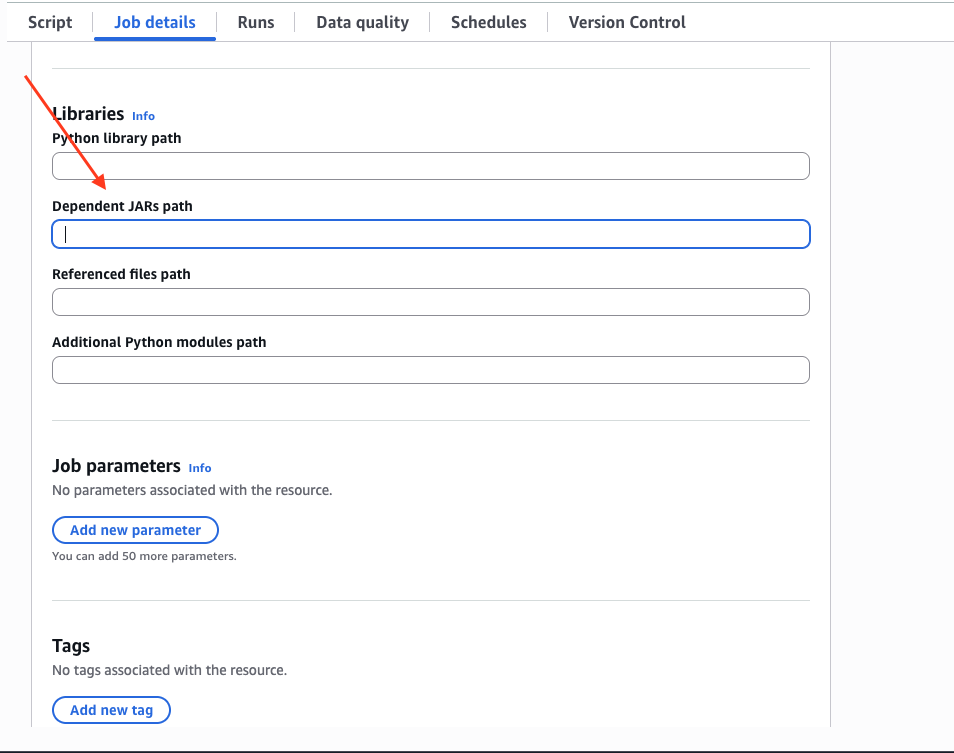
- На вкладке
Job detailsпрокрутите вниз и разверните выпадающее менюAdvanced properties, и заполните путь к JAR-файлам вDependent JARs path:
Примеры
- Scala
- Python
Для получения дополнительной информации, пожалуйста, посетите нашу документацию по Spark.
