Простой гид по оптимизации запросов
Этот раздел предназначен для иллюстрации на общих примерах того, как использовать различные методы повышения производительности и оптимизации, такие как анализатор, профилирование запросов или избежание Nullable колонок, чтобы улучшить производительность запросов ClickHouse.
Понимание производительности запроса
Лучшее время для размышлений об оптимизации производительности - это момент, когда вы настраиваете свою схему данных перед загрузкой данных в ClickHouse в первый раз.
Но давайте будем честными; трудно предсказать, насколько ваши данные вырастут или какие типы запросов будут выполняться.
Если у вас есть существующее развертывание с несколькими запросами, которые вы хотите улучшить, первым шагом является понимание того, как эти запросы выполняются и почему некоторые выполняются за несколько миллисекунд, в то время как другие занимают больше времени.
ClickHouse предлагает богатый набор инструментов, чтобы помочь вам понять, как выполняется ваш запрос и какие ресурсы потребляются для выполнения.
В этом разделе мы рассмотрим эти инструменты и как их использовать.
Общие соображения
Чтобы понять производительность запроса, давайте посмотрим, что происходит в ClickHouse, когда запрос выполняется.
Следующая часть намеренно упрощена и делает некоторые сокращения; идея здесь не в том, чтобы загрузить вас деталями, а в том, чтобы познакомить вас с основными понятиями. Для получения дополнительной информации вы можете прочитать о анализаторе запросов.
С очень высокой точки зрения, когда ClickHouse выполняет запрос, происходит следующее:
- Парсинг и анализ запроса
Запрос разбирается и анализируется, и создается общий план выполнения запроса.
- Оптимизация запроса
План выполнения запроса оптимизируется, ненужные данные отбрасываются, и строится конвейер запросов из плана запроса.
- Выполнение конвейера запроса
Данные считываются и обрабатываются параллельно. Это этап, на котором ClickHouse фактически выполняет операции запроса, такие как фильтрация, агрегация и сортировка.
- Финальная обработка
Результаты объединяются, сортируются и форматируются в окончательный результат перед отправкой клиенту.
На самом деле происходит множество оптимизаций, и мы обсудим их немного подробнее в этом руководстве, но пока эти основные концепции дают нам хорошее представление о том, что происходит за кулисами, когда ClickHouse выполняет запрос.
С этим пониманием на высоком уровне давайте рассмотрим инструменты, которые предоставляет ClickHouse, и как мы можем использовать их для отслеживания метрик, которые влияют на производительность запроса.
Набор данных
Мы будем использовать реальный пример, чтобы проиллюстрировать, как мы подходим к производительности запросов.
Давайте используем набор данных такси NYC, который содержит данные о поездках на такси в Нью-Йорке. Сначала мы начнем с загрузки набора данных такси NYC без оптимизации.
Ниже приведена команда для создания таблицы и вставки данных из корзины S3. Обратите внимание, что мы намеренно выводим схему из данных, что не оптимизировано.
Давайте посмотрим на схему таблицы, автоматически выведенную из данных.
Поиск медленных запросов
Журналы запросов
По умолчанию ClickHouse собирает и регистрирует информацию о каждом выполненном запросе в журналах запросов. Эти данные хранятся в таблице system.query_log.
Для каждого выполненного запроса ClickHouse записывает статистику, такую как время выполнения запроса, количество прочитанных строк и использование ресурсов, таких как CPU, использование памяти или попадания в кеш файловой системы.
Таким образом, журнал запросов - хорошее место для начала, когда вы исследуете медленные запросы. Вы можете легко выявить запросы, которые требуют много времени для выполнения, и отобразить информацию о расходах ресурсов для каждого из них.
Давайте найдем пятерку самых длительных запросов в нашем наборе данных такси NYC.
Поле query_duration_ms указывает, сколько времени заняло выполнение данного запроса. Смотрев на результаты из журналов запросов, мы можем увидеть, что первый запрос выполняется 2967мс, что можно улучшить.
Вам также может быть интересно узнать, какие запросы нагнетают систему, изучив запрос, который потребляет больше всего памяти или CPU.
Давайте изолируем длительные запросы, которые мы нашли, и повторим их несколько раз, чтобы понять время отклика.
На этом этапе важно отключить кеш файловой системы, установив параметр enable_filesystem_cache в 0 для улучшения воспроизводимости.
Сводим в таблице для удобства чтения.
| Имя | Время выполнения | Обработанные строки | Пиковая память |
|---|---|---|---|
| Запрос 1 | 1.699 сек | 329.04 миллиона | 440.24 MiB |
| Запрос 2 | 1.419 сек | 329.04 миллиона | 546.75 MiB |
| Запрос 3 | 1.414 сек | 329.04 миллиона | 451.53 MiB |
Давайте немного лучше поймем, что достигают запросы.
- Запрос 1 вычисляет распределение расстояний в поездках со средней скоростью более 30 миль в час.
- Запрос 2 находит количество и среднюю стоимость поездок за неделю.
- Запрос 3 рассчитывает среднее время каждой поездки в наборе данных.
Ни один из этих запросов не производит очень сложную обработку, кроме первого запроса, который вычисляет время поездки на лету каждый раз, когда запрос выполняется. Однако каждый из этих запросов занимает более одной секунды для выполнения, что в мире ClickHouse является очень долгим временем. Мы также можем отметить использование памяти этих запросов; около 400 Мб для каждого запроса - это довольно много памяти. Также каждый запрос, похоже, читает одно и то же количество строк (329.04 миллиона). Давайте быстро подтвердим, сколько строк в этой таблице.
Таблица содержит 329.04 миллиона строк, поэтому каждый запрос выполняет полное сканирование таблицы.
Оператор Explain
Теперь, когда у нас есть несколько длительных запросов, давайте поймем, как они выполняются. Для этого ClickHouse поддерживает команду EXPLAIN. Это очень полезный инструмент, который предоставляет очень подробный обзор всех этапов выполнения запроса без фактического выполнения запроса. Хотя это может быть подавляющим для неподготовленного пользователя ClickHouse, это все же необходимый инструмент для получения информации о том, как выполняется ваш запрос.
Документация предоставляет подробный гид о том, что такое оператор EXPLAIN и как его использовать для анализа выполнения вашего запроса. Вместо того, чтобы повторять то, что содержится в этом руководстве, давайте сосредоточимся на нескольких командах, которые помогут нам выявить узкие места в производительности выполнения запросов.
Explain indexes = 1
Давайте начнем с EXPLAIN indexes = 1, чтобы просмотреть план запроса. План запроса - это дерево, показывающее, как будет выполнен запрос. Здесь вы можете увидеть, в каком порядке будут выполняться операторы из запроса. План запроса, возвращаемый оператором EXPLAIN, можно читать снизу вверх.
Давайте попробуем использовать первый из наших длительных запросов.
Вывод прост. Запрос начинает с считывания данных из таблицы nyc_taxi.trips_small_inferred. Затем применяется оператор WHERE для фильтрации строк на основе вычисленных значений. Отфильтрованные данные подготавливаются для агрегации, и вычисляются квантильные значения. В конце результат сортируется и выводится.
Здесь мы можем отметить, что первичные ключи не используются, что имеет смысл, так как мы не определили их при создании таблицы. В результате ClickHouse выполняет полное сканирование таблицы для запроса.
Explain Pipeline
EXPLAIN Pipeline показывает конкретную стратегию выполнения запроса. Здесь вы можете увидеть, как ClickHouse фактически выполнил общий план запроса, который мы смотрели ранее.
Здесь мы можем отметить количество потоков, используемых для выполнения запроса: 59 потоков, что указывает на высокую степень параллелизма. Это ускоряет выполнение запроса, который занял бы больше времени на меньшей машине. Количество потоков, работающих параллельно, может объяснить высокое потребление памяти запросом.
В идеале вам следует исследовать все ваши медленные запросы таким же образом, чтобы выявить ненужные сложные планы запросов и понять количество строк, прочитанных каждым запросом, и потребляемые ресурсы.
Методология
Может быть сложно определить проблемные запросы на развертывании в производственной среде, так как в любой момент времени в вашем развертывании ClickHouse выполняется, вероятно, большое количество запросов.
Если вы знаете, какой пользователь, база данных или таблицы имеют проблемы, вы можете использовать поля user, tables или databases из system.query_logs, чтобы сузить поиск.
Как только вы определите, какие запросы хотите оптимизировать, вы можете начать работать над ними. Одна распространенная ошибка, которую делают разработчики на этом этапе, - это одновременно менять несколько вещей, проводить экспериментальные тесты и, как правило, в конечном итоге получать смешанные результаты, но, что более важно, не понимая, что сделало запрос быстрее.
Оптимизация запросов требует структуры. Я не говорю о сложном бенчмаркинге, но наличие простого процесса, который поможет понять, как ваши изменения влияют на производительность запросов, может значительно повлиять.
Начните с выявления ваших медленных запросов из журналов запросов, затем исследуйте потенциальные улучшения в изоляции. При тестировании запроса убедитесь, что вы отключили кеш файловой системы.
ClickHouse использует кэширование, чтобы ускорить производительность запросов на различных этапах. Это хорошо для производительности запросов, но при устранении неполадок это может скрыть потенциальные узкие места ввода-вывода или плохую схему таблицы. По этой причине я рекомендую отключить кеш файловой системы во время тестирования. Убедитесь, что он включен в производственной среде.
Как только вы определите потенциальные оптимизации, рекомендуется реализовывать их одну за другой, чтобы лучше отслеживать, как они влияют на производительность. Ниже представлена схема, описывающая общий подход.
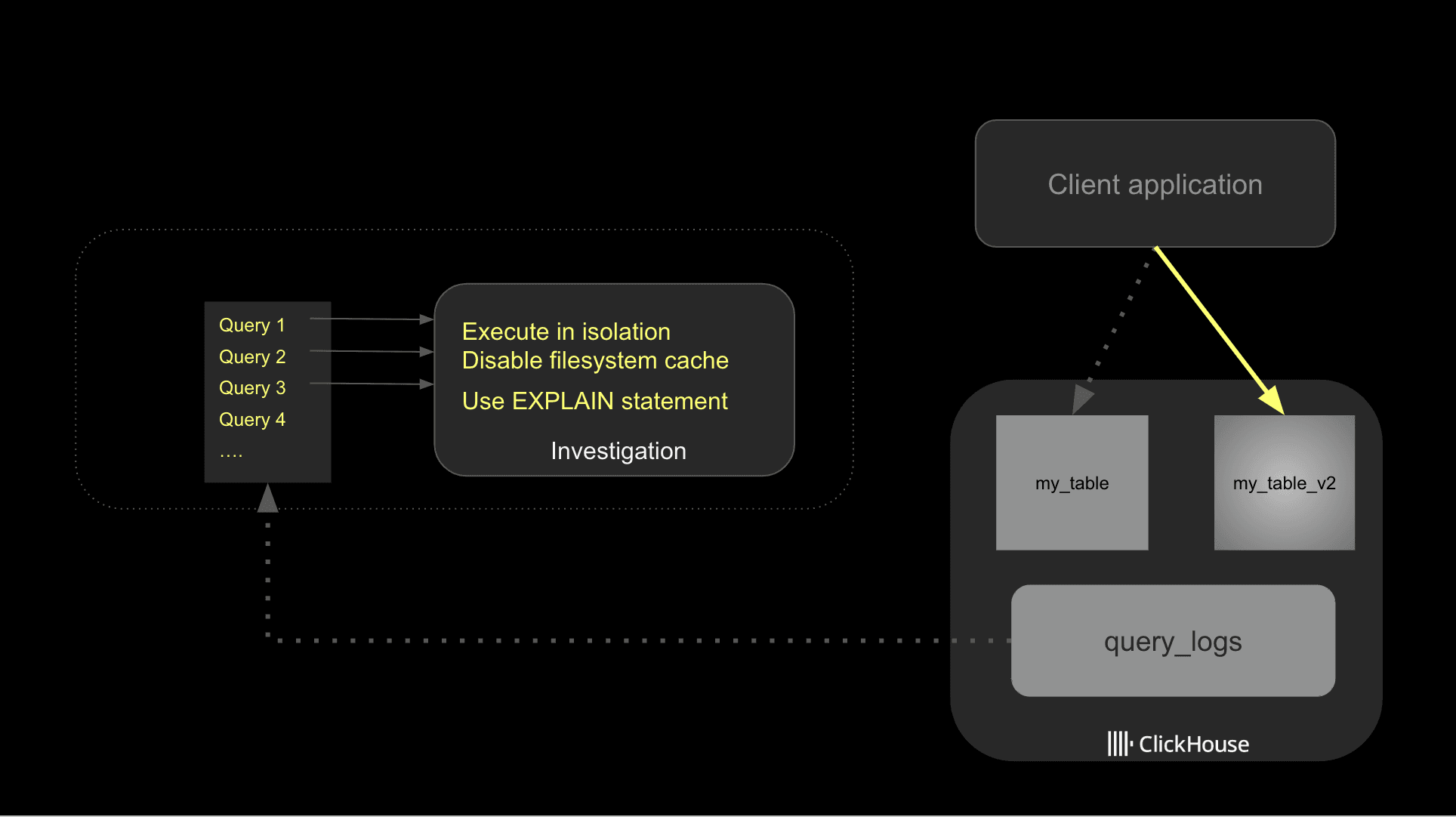
Наконец, будьте осторожны с выбросами; довольно часто запрос может выполняться медленно, либо потому, что пользователь пытался выполнить дорогой запрос, либо по другой причине, связанной с нагрузкой на систему. Вы можете сгруппировать данные по полю normalized_query_hash, чтобы идентифицировать дорогие запросы, которые выполняются регулярно. Именно их вам, вероятно, следует изучить.
Базовая оптимизация
Теперь, когда у нас есть наша структура для тестирования, мы можем начать оптимизацию.
Лучшее место для начала - это посмотреть, как хранятся данные. Как и для любой базы данных, чем меньше данных мы читаем, тем быстрее будет выполняться запрос.
В зависимости от того, как вы загрузили свои данные, вы могли использовать возможности ClickHouse для вывода схемы на основе загруженных данных. Хотя это очень удобно для начала, если вы хотите оптимизировать производительность своего запроса, вам нужно будет пересмотреть схему данных, чтобы лучше соответствовать вашему случаю использования.
Nullable
Как описано в документации по лучшим практикам, избегайте nullable-колонок, где это возможно. Искушение использовать их часто велико, так как они делают механизм загрузки данных более гибким, но они негативно влияют на производительность, так как каждый раз нужно обрабатывать дополнительную колонку.
Запуск SQL-запроса, который подсчитывает строки с NULL значением, может легко выявить колонки в ваших таблицах, которые на самом деле нуждаются в Nullable значении.
У нас есть только две колонки с null значениями: mta_tax и payment_type. Остальные поля не должны использовать Nullable колонку.
Низкая кардинальность
Легкая оптимизация, которую можно применять к строкам, - это наиболее эффективное использование типа данных LowCardinality. Как описано в документации по низкой кардинальности, ClickHouse применяет кодирование словаря к колонкам LowCardinality, что значительно увеличивает производительность запросов.
Простое правило для определения, какие колонки являются хорошими кандидатами для LowCardinality, заключается в том, что любую колонку с менее чем 10 000 уникальными значениями можно считать идеальным кандидатом.
Вы можете использовать следующий SQL-запрос, чтобы найти колонки с небольшим количеством уникальных значений.
С низкой кардинальностью, эти четыре колонки, ratecode_id, pickup_location_id, dropoff_location_id и vendor_id, являются хорошими кандидатами для типа поля LowCardinality.
Оптимизация типа данных
ClickHouse поддерживает большое количество типов данных. Убедитесь, что вы выбрали наименьший возможный тип данных, который подходит для вашего случая использования, чтобы оптимизировать производительность и сократить место хранения данных на диске.
Для чисел вы можете проверить минимальное/максимальное значение в вашем наборе данных, чтобы убедиться, что текущее значение точности соответствует действительности вашего набора данных.
Для дат вам следует выбрать точность, которая соответствует вашему набору данных и лучше всего подходит для ответов на запросы, которые вы собираетесь выполнять.
Применение оптимизаций
Давайте создадим новую таблицу, чтобы использовать оптимизированную схему и вновь загрузим данные.
Мы снова запускаем запросы, используя новую таблицу, чтобы проверить улучшения.
| Имя | Запуск 1 - Время | Время выполнения | Обработанные строки | Пиковая память |
|---|---|---|---|---|
| Запрос 1 | 1.699 сек | 1.353 сек | 329.04 миллиона | 337.12 MiB |
| Запрос 2 | 1.419 сек | 1.171 сек | 329.04 миллиона | 531.09 MiB |
| Запрос 3 | 1.414 сек | 1.188 сек | 329.04 миллиона | 265.05 MiB |
Мы замечаем некоторые улучшения как в времени запроса, так и в использовании памяти. Благодаря оптимизации в схеме данных мы сокращаем общий объем данных, представляющих наши данные, что ведет к улучшенному потреблению памяти и сокращению времени обработки.
Давайте проверим размер таблиц, чтобы увидеть разницу.
Новая таблица значительно меньше, чем предыдущая. Мы видим сокращение примерно на 34% в дисковом пространстве для таблицы (7.38 GiB против 4.89 GiB).
Важность первичных ключей
Первичные ключи в ClickHouse работают иначе, чем в большинстве традиционных систем управления базами данных. В этих системах первичные ключи обеспечивают уникальность и целостность данных. Любая попытка вставить дублирующиеся значения первичного ключа отклоняется, и обычно создается индекс на основе B-дерева или хэш-таблицы для быстрого поиска.
В ClickHouse цель первичного ключа иная; он не обеспечивает уникальность или помогает с целостностью данных. Вместо этого он предназначен для оптимизации производительности запросов. Первичный ключ определяет порядок, в котором данные хранятся на диске, и реализуется как разреженный индекс, который хранит указатели на первую строку каждого гранулы.
Гранулы в ClickHouse - это наименьшие единицы данных, читаемые во время выполнения запроса. Они содержат до фиксированного количества строк, определяемого index_granularity, с умолчательным значением 8192 строки. Гранулы хранятся последовательно и сортируются по первичному ключу.
Выбор хорошего набора первичных ключей важен для производительности, и на самом деле обычно хранится одни и те же данные в разных таблицах и используются разные наборы первичных ключей для ускорения определенного набора запросов.
Другие опции, поддерживаемые ClickHouse, такие как проекция или материализованное представление, позволяют использовать другой набор первичных ключей на одних и тех же данных. Вторая часть этой серии блогов освятит эту тему более подробно.
Выбор первичных ключей
Выбор правильного набора первичных ключей - это сложная задача, и для нахождения лучшей комбинации могут потребоваться компромиссы и эксперименты.
На данный момент мы будем следовать этим простым практикам:
- Используйте поля, которые используются для фильтрации в большинстве запросов
- Сначала выбирайте колонки с низкой кардинальностью
- Учитывайте временной компонент в своем первичном ключе, так как фильтрация по времени для набора данных с временными метками довольно распространена.
В нашем случае мы будем экспериментировать с следующими первичными ключами: passenger_count, pickup_datetime и dropoff_datetime.
Кардинальность для passenger_count мала (24 уникальных значения) и используется в наших медленных запросах. Мы также добавляем временные поля (pickup_datetime и dropoff_datetime), так как они могут часто фильтроваться.
Создайте новую таблицу с первичными ключами и снова загрузите данные.
Затем мы повторно запустим наши запросы. Мы собираем результаты из трех экспериментов, чтобы посмотреть улучшения в времени выполнения, обработанных строках и потреблении памяти.
| Запрос 1 | |||
|---|---|---|---|
| Запуск 1 | Запуск 2 | Запуск 3 | |
| Время выполнения | 1.699 сек | 1.353 сек | 0.765 сек |
| Обработанные строки | 329.04 миллиона | 329.04 миллиона | 329.04 миллиона |
| Пиковая память | 440.24 MiB | 337.12 MiB | 444.19 MiB |
| Запрос 2 | |||
|---|---|---|---|
| Запуск 1 | Запуск 2 | Запуск 3 | |
| Время выполнения | 1.419 сек | 1.171 сек | 0.248 сек |
| Обработанные строки | 329.04 миллиона | 329.04 миллиона | 41.46 миллиона |
| Пиковая память | 546.75 MiB | 531.09 MiB | 173.50 MiB |
| Запрос 3 | |||
|---|---|---|---|
| Запуск 1 | Запуск 2 | Запуск 3 | |
| Время выполнения | 1.414 сек | 1.188 сек | 0.431 сек |
| Обработанные строки | 329.04 миллиона | 329.04 миллиона | 276.99 миллиона |
| Пиковая память | 451.53 MiB | 265.05 MiB | 197.38 MiB |
Мы можем увидеть значительное улучшение по всем фронтам в времени выполнения и использованию памяти.
Запрос 2 получает наибольшую выгоду от первичного ключа. Давайте посмотрим, как план запроса, сгенерированный до и после, отличается.
Благодаря первичному ключу был выбран только поднабор гранул таблицы. Это значительно улучшает производительность запроса, так как ClickHouse должен обрабатывать значительно меньше данных.
Следующие шаги
Надеюсь, этот гид дает хорошее понимание того, как исследовать медленные запросы с помощью ClickHouse и как делать их быстрее. Чтобы узнать больше о данной теме, вы можете прочитать больше о анализаторе запросов и профилировании, чтобы лучше понять, как именно ClickHouse выполняет ваш запрос.
По мере того как вы становитесь более знакомыми с особенностями ClickHouse, я бы порекомендовал прочитать о ключах партиционирования и индексах пропуска данных, чтобы узнать о более продвинутых техниках, которые вы можете использовать для ускорения своих запросов.
