Первичные индексы
Эта страница представляет собой описание разреженного первичного индекса ClickHouse, как он строится, как работает и как помогает ускорять запросы.
Для продвинутых стратегий индексации и углубленных технических деталей смотрите глубокое погружение в первичные индексы.
Как работает разреженный первичный индекс в ClickHouse?
Разреженный первичный индекс в ClickHouse помогает эффективно идентифицировать гранулы—блоки строк—которые могут содержать данные, соответствующие условию запроса по ^^первичному ключу^^ таблицы. В следующем разделе мы объясним, как этот индекс строится из значений в этих колонках.
Создание разреженного первичного индекса
Для иллюстрации того, как строится разреженный первичный индекс, мы используем таблицу uk_price_paid_simple вместе с некоторыми анимациями.
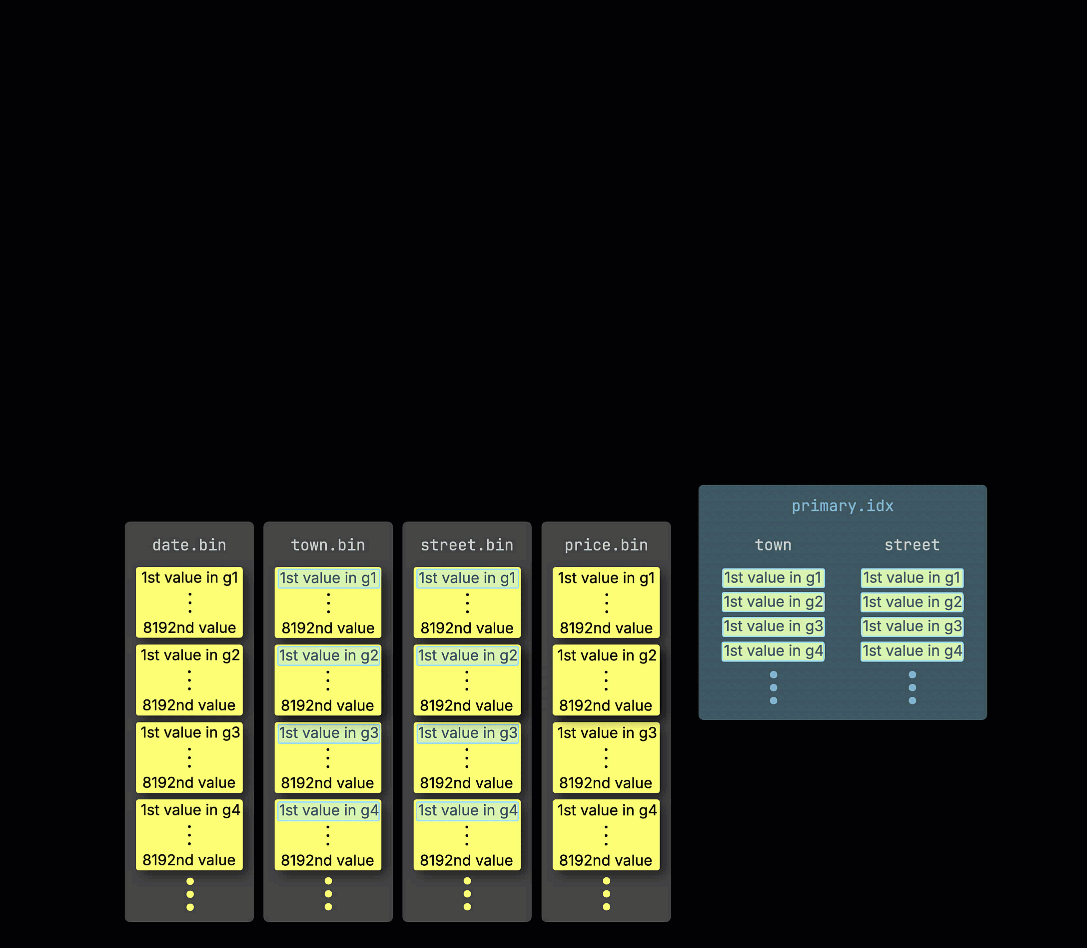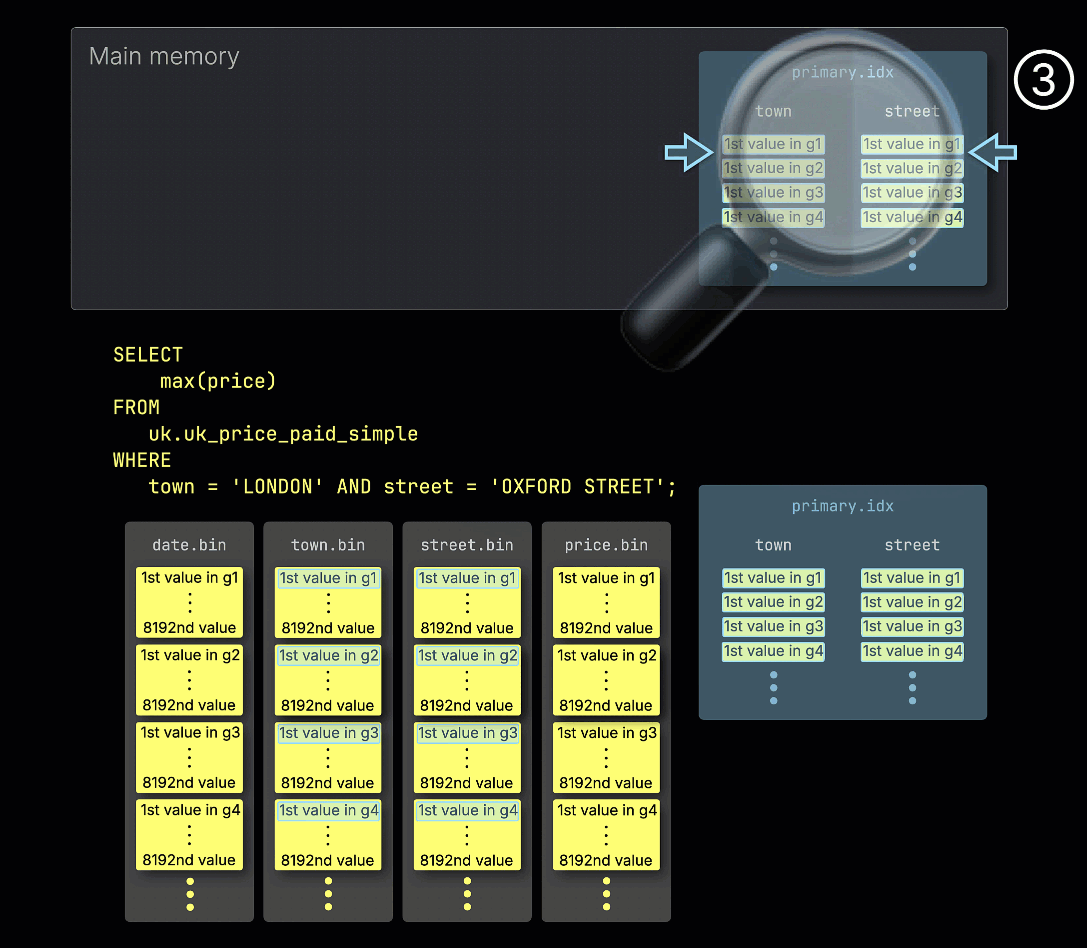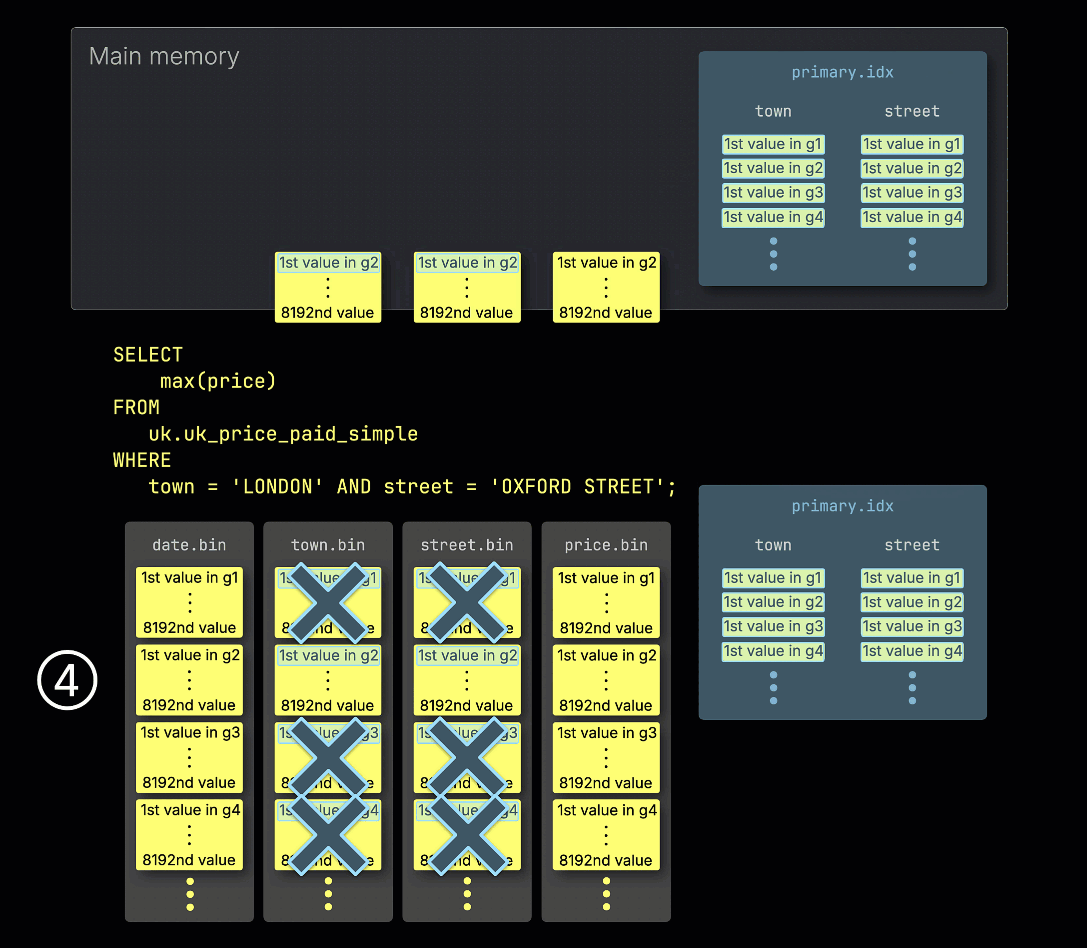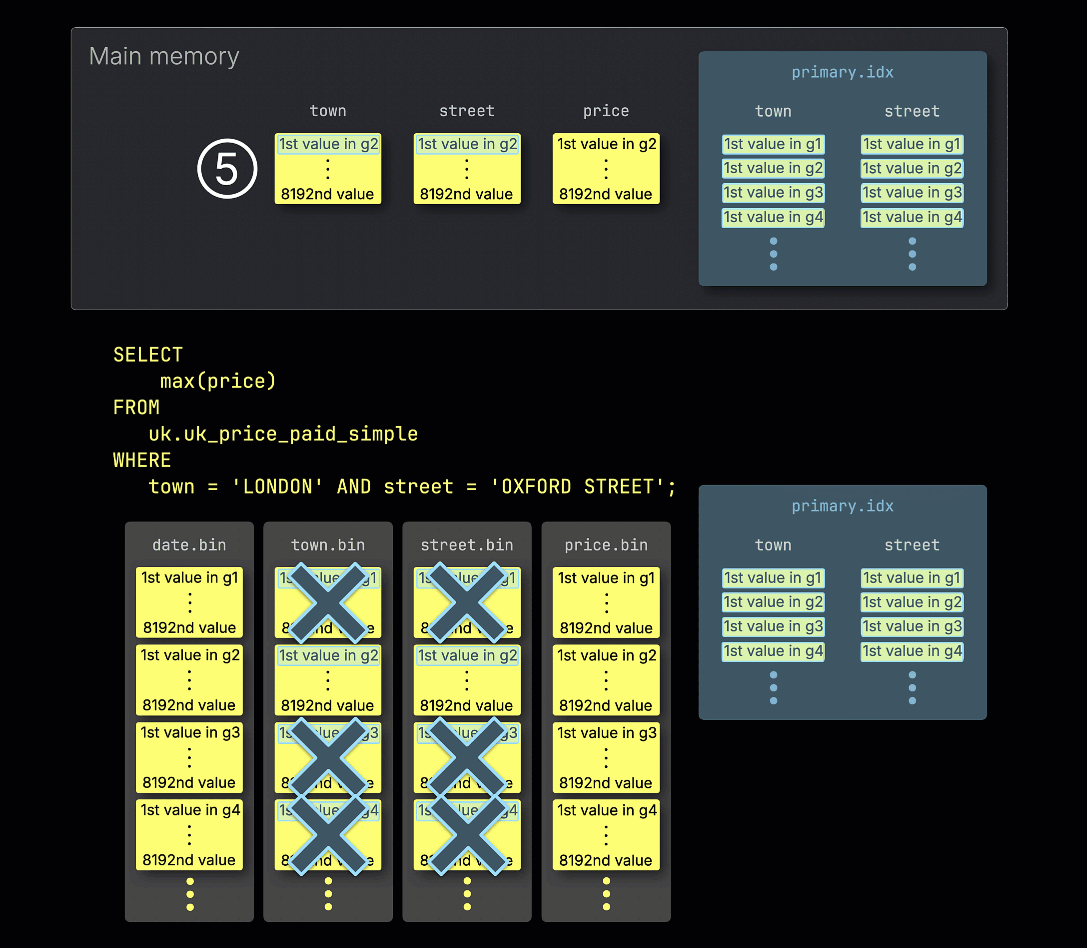
В качестве напоминания, в нашей ① примерной таблице с ^^первичным ключом^^ (town, street), ② вставленные данные ③ хранятся на диске, сортируются по значениям колонок ^^первичного ключа^^ и сжаты, в отдельных файлах для каждой колонки:
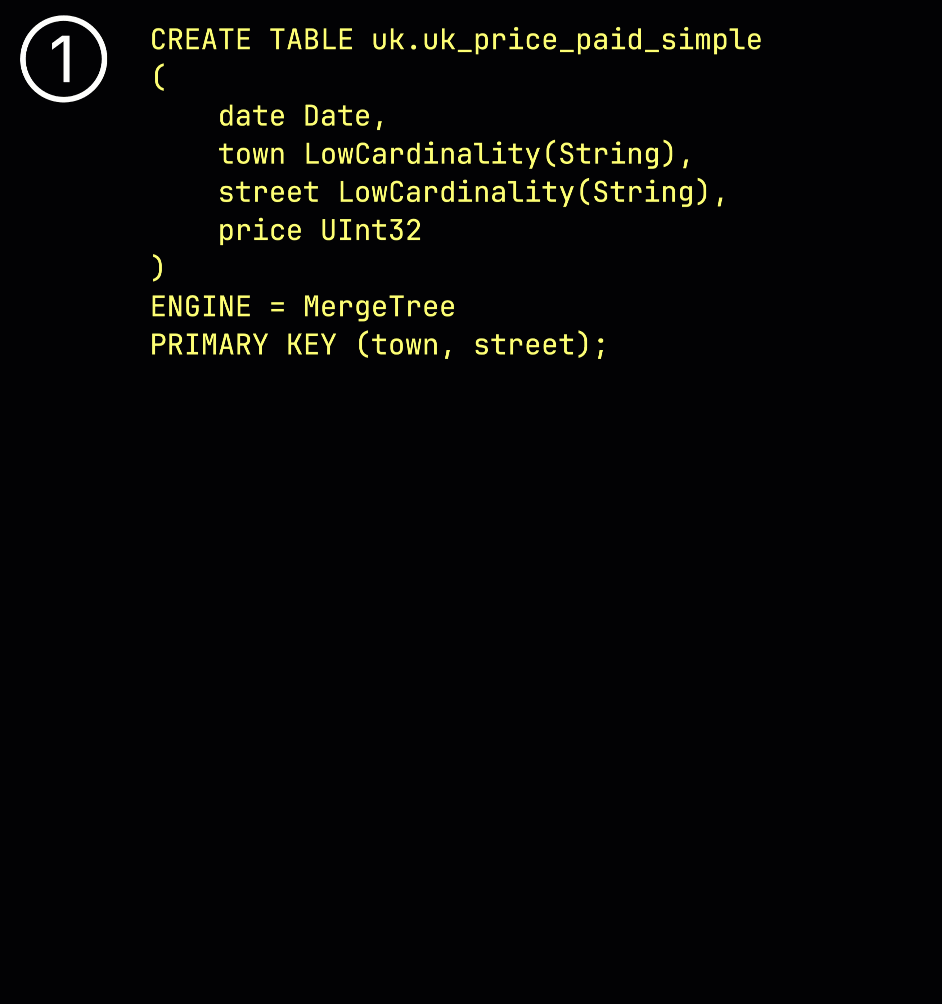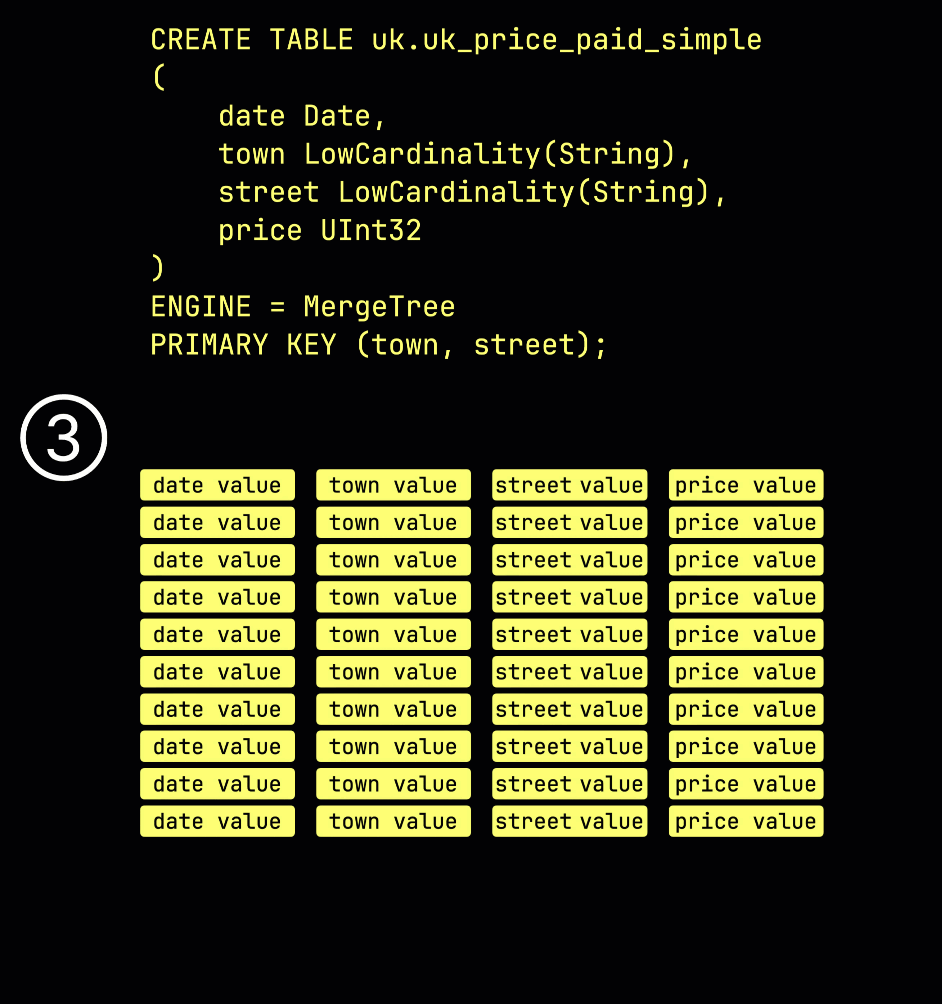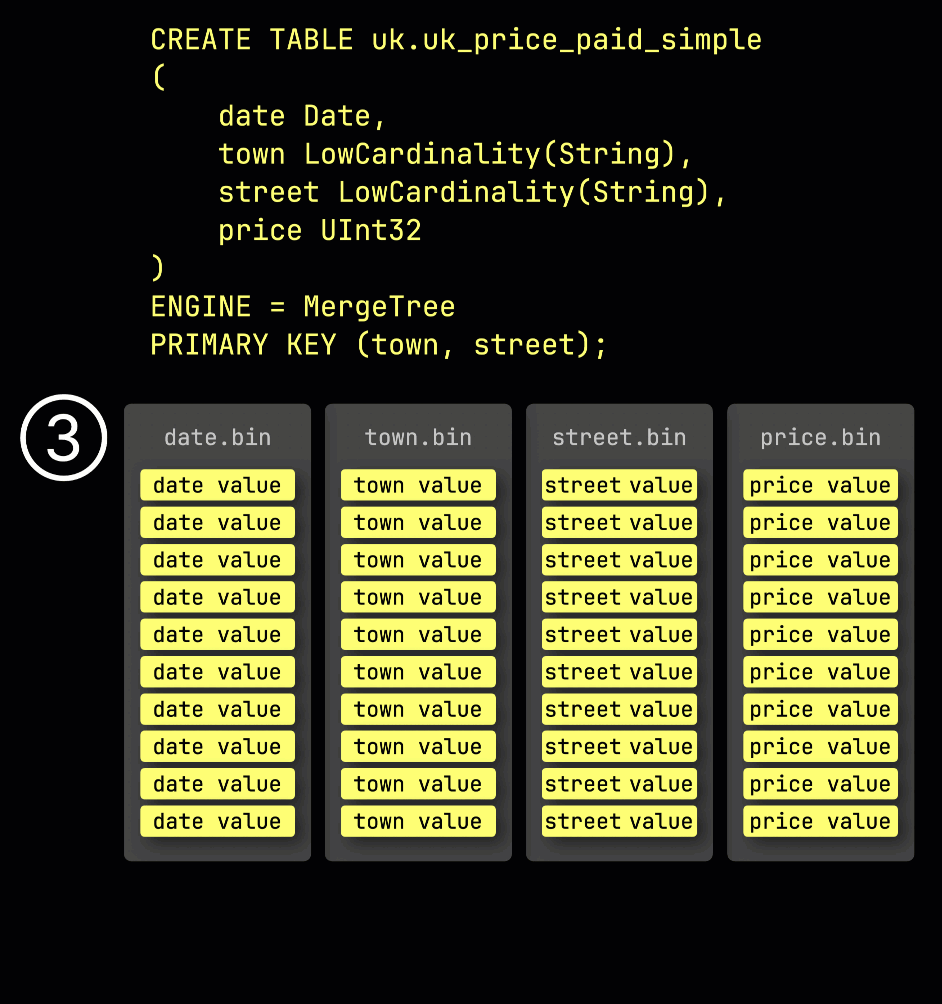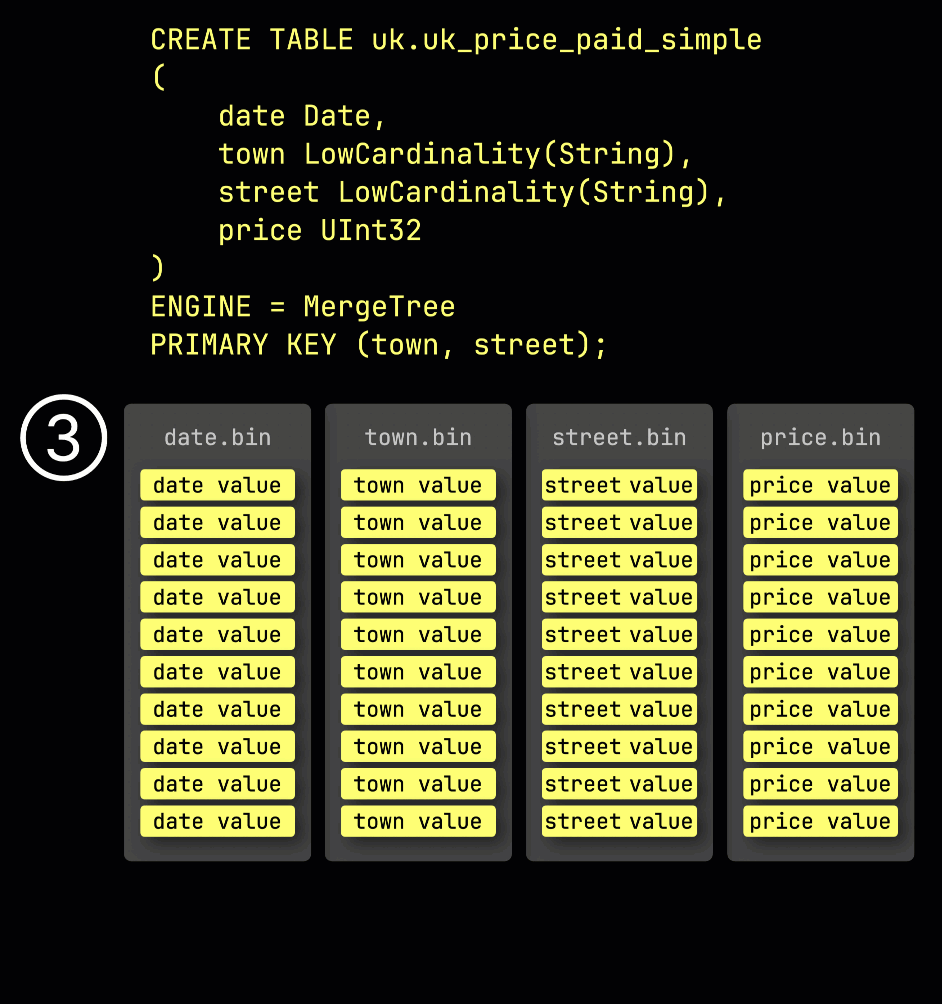
Для обработки данные каждой колонки ④ логически делятся на гранулы — каждая охватывает 8,192 строки — которые являются наименьшими единицами, с которыми работают механизмы обработки данных ClickHouse.
Эта структура ^^гранулы^^ также делает первичный индекс разреженным: вместо индексирования каждой строки, ClickHouse хранит ⑤ значения ^^первичного ключа^^ только из одной строки на ^^гранулу^^ — конкретно, из первой строки. Это приводит к тому, что на каждую ^^гранулу^^ приходится одна запись индекса:
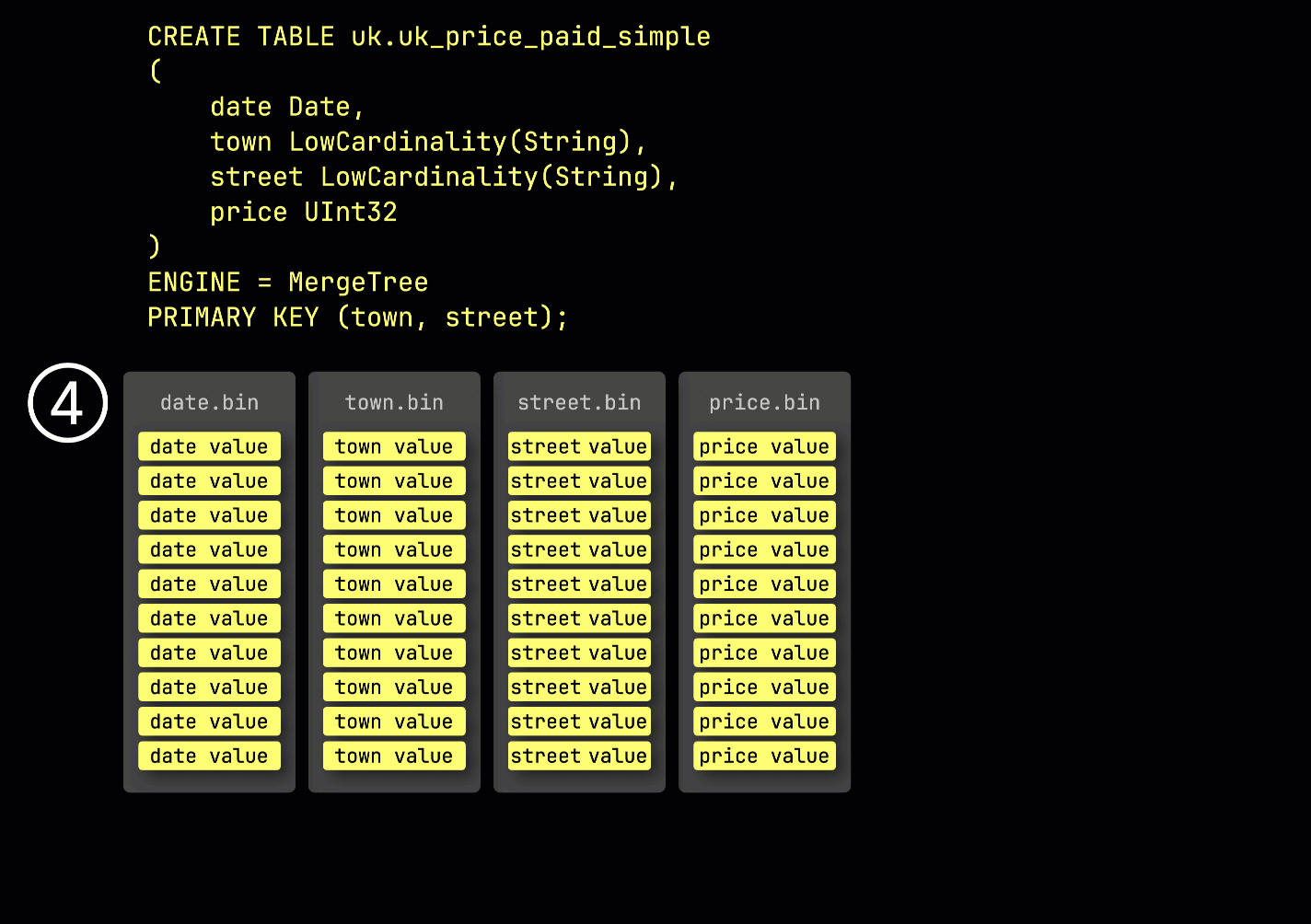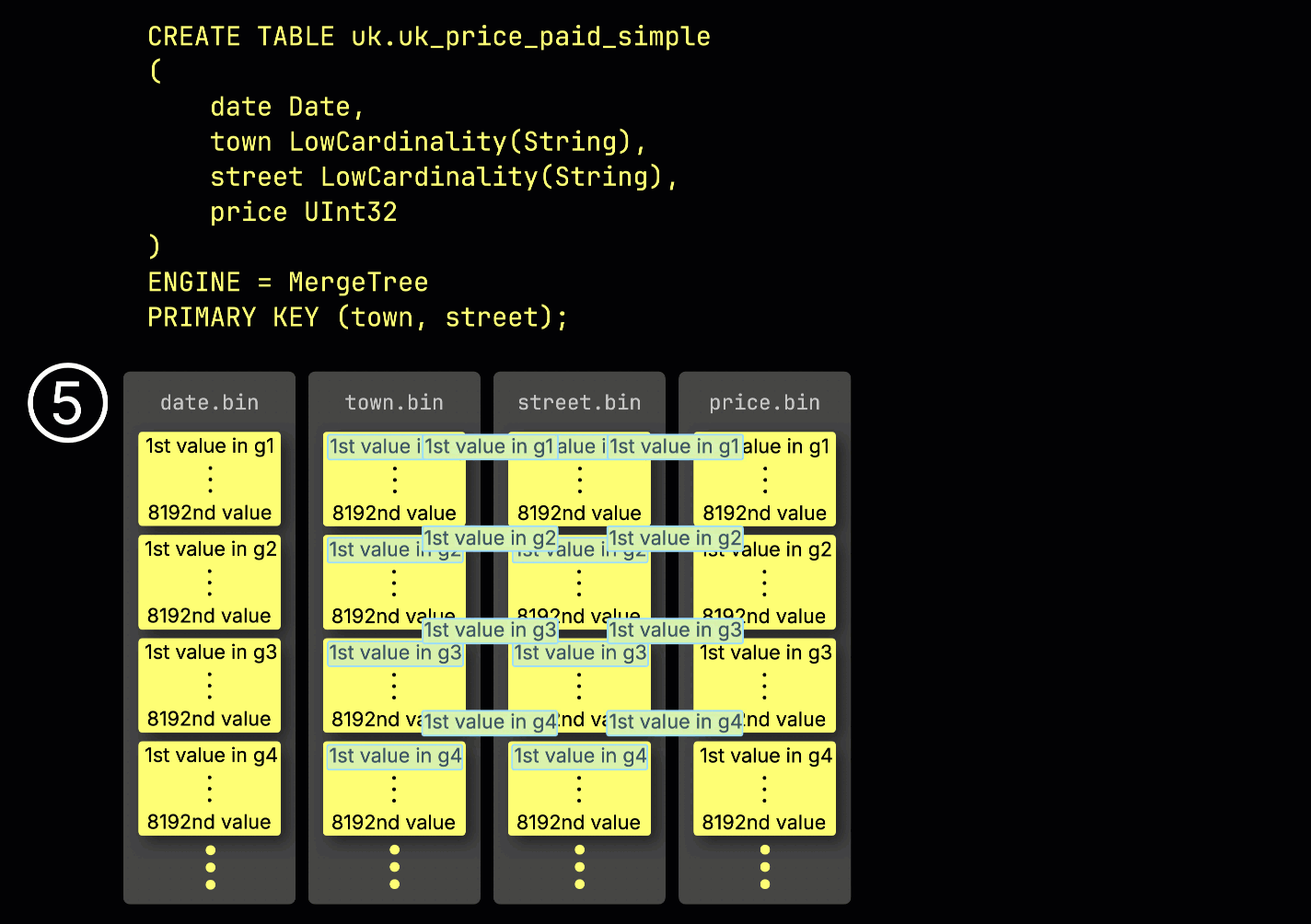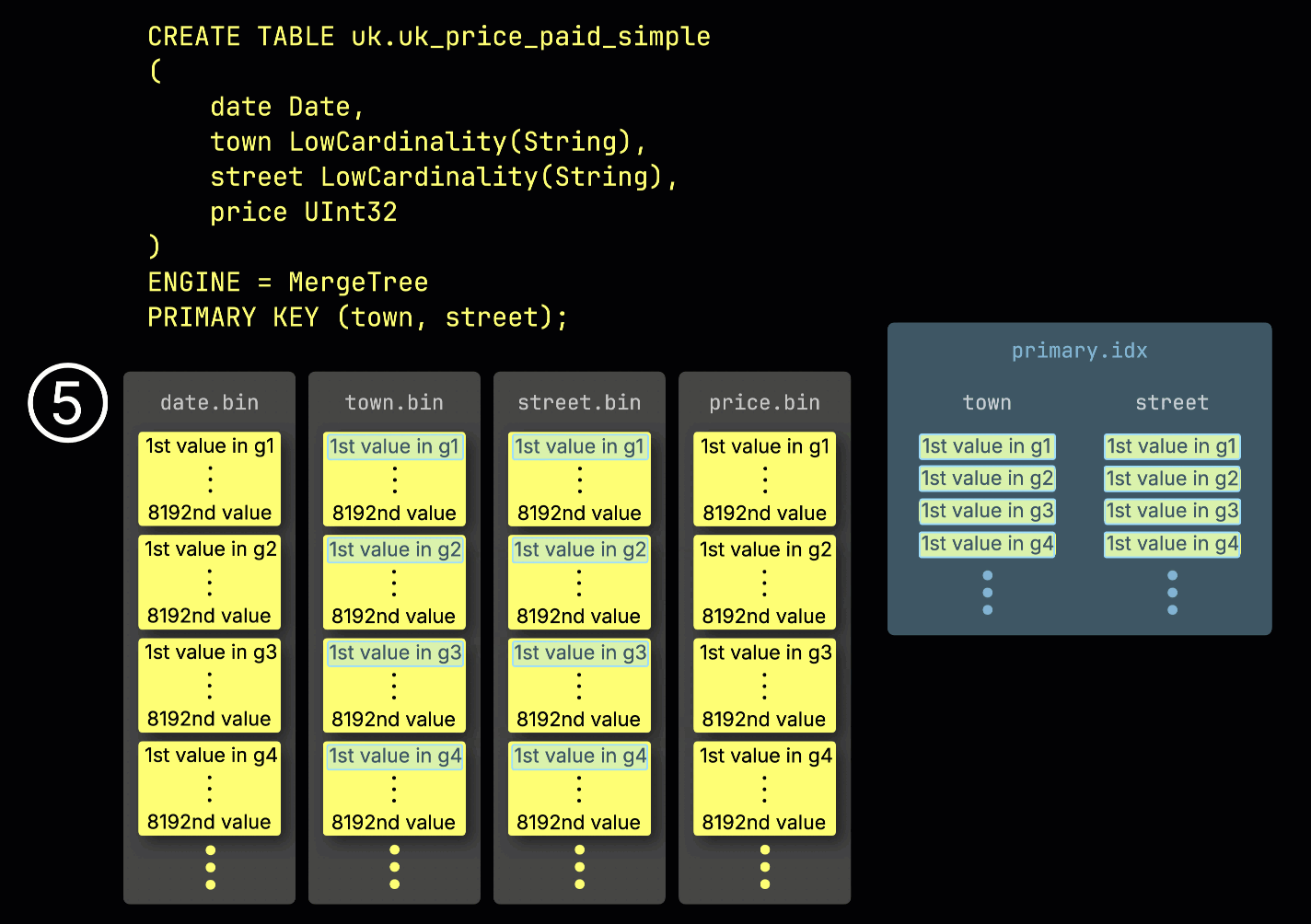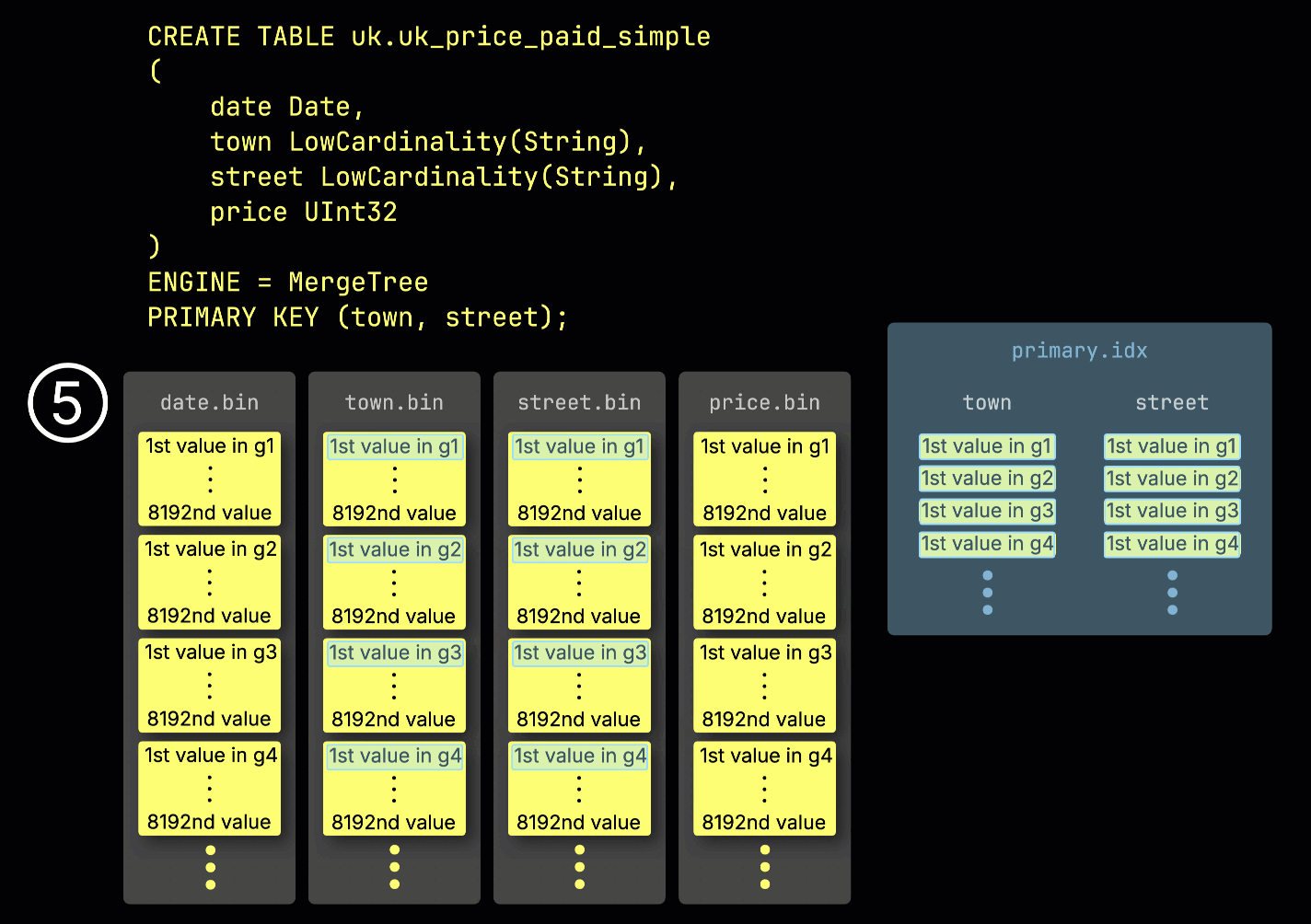
Благодаря своей разреженности первичный индекс достаточно мал, чтобы уместиться целиком в памяти, что позволяет быстро фильтровать запросы с предикатами по колонкам ^^первичного ключа^^. В следующем разделе мы покажем, как он помогает ускорять такие запросы.
Использование первичного индекса
Мы схематично показываем, как разреженный первичный индекс используется для ускорения запросов с помощью другой анимации:
① Пример запроса включает предикат по обеим колонкам ^^первичного ключа^^: town = 'LONDON' AND street = 'OXFORD STREET'.
② Для ускорения запроса ClickHouse загружает первичный индекс таблицы в память.
③ Затем он просматривает записи индекса, чтобы определить, какие гранулы могут содержать строки, соответствующие предикату — другими словами, какие гранулы нельзя пропустить.
④ Эти потенциально релевантные гранулы затем загружаются и обрабатываются в памяти, вместе с соответствующими гранулами из любых других колонок, необходимых для запроса.
Мониторинг первичных индексов
Каждая часть данных в таблице имеет свой собственный первичный индекс. Мы можем просмотреть содержимое этих индексов, используя табличную функцию mergeTreeIndex.
Следующий запрос перечисляет количество записей в первичном индексе для каждой части данных нашей примерной таблицы:
Этот запрос показывает первые 10 записей из первичного индекса одной из текущих частей данных ^^parts^^. Обратите внимание, что эти ^^части^^ непрерывно сливаются в фоновом режиме в более крупные ^^части^^:
Наконец, мы используем оператор EXPLAIN, чтобы увидеть, как первичные индексы всех частей данных ^^parts^^ используются для пропуска гранул, которые не могут содержать строки, соответствующие предикатам примерного запроса. Эти гранулы исключаются из загрузки и обработки:
Обратите внимание, что строка 13 вывода EXPLAIN выше показывает, что лишь 3 из 3,609 гранул среди всех частей данных были выбраны для обработки по результатам анализа первичного индекса. Оставшиеся гранулы были полностью пропущены.
Мы также можем наблюдать, что большая часть данных была пропущена, просто выполнив запрос:
Как показано выше, было обработано лишь около 25,000 строк из примерно 30 миллионов строк в примерной таблице:
Ключевые выводы
-
Разреженные первичные индексы помогают ClickHouse пропускать ненужные данные, идентифицируя, какие гранулы могут содержать строки, соответствующие условиям запроса по колонкам ^^первичного ключа^^.
-
Каждый индекс хранит только значения ^^первичного ключа^^ из первой строки каждой ^^гранулы^^ (по умолчанию ^^гранула^^ состоит из 8,192 строк), что делает его компактным и помещающимся в памяти.
-
Каждая часть данных в таблице ^^MergeTree^^ имеет свой собственный первичный индекс, который используется независимо во время выполнения запросов.
-
Во время запросов индекс позволяет ClickHouse пропускать гранулы, уменьшая ввод-вывод и использование памяти, одновременно ускоряя производительность.
-
Вы можете просматривать содержимое индекса с помощью табличной функции
mergeTreeIndexи отслеживать использование индекса с помощью оператораEXPLAIN.
Где найти дополнительную информацию
Для более глубокого понимания того, как работают разреженные первичные индексы в ClickHouse, включая их отличие от традиционных индексов баз данных и лучшие практики их использования, ознакомьтесь с нашим подробным материалом по индексации глубокое погружение.
Если вам интересно, как ClickHouse обрабатывает данные, выбранные сканированием первичного индекса, в высокопараллельном режиме, смотрите руководство по параллелизму запросов здесь.
