Таблица шардов и реплик
Эта тема не относится к ClickHouse Cloud, где Параллельные реплики функционируют как несколько шардов в традиционных кластерах ClickHouse без общих ресурсов, а объектное хранилище заменяет реплики, обеспечивая высокую доступность и отказоустойчивость.
Что такое шардированные таблицы в ClickHouse?
В традиционных архитекторах без общих ресурсов ClickHouse шардирование используется, когда ① данные слишком велики для одного сервера или ② один сервер слишком медленный для обработки данных. На следующем рисунке иллюстрируется случай ①, когда таблица uk_price_paid_simple превышает емкость одной машины:
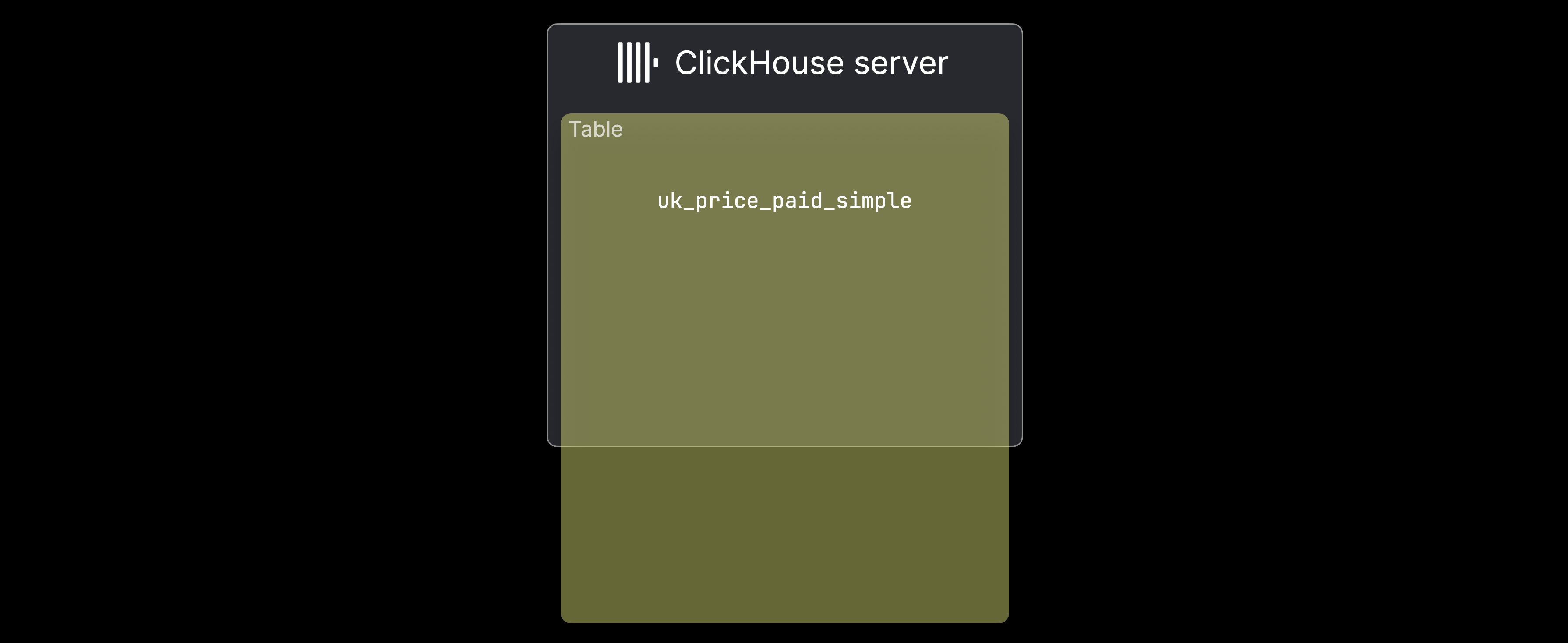
В таких случаях данные могут быть распределены между несколькими серверами ClickHouse в виде шардов таблицы:
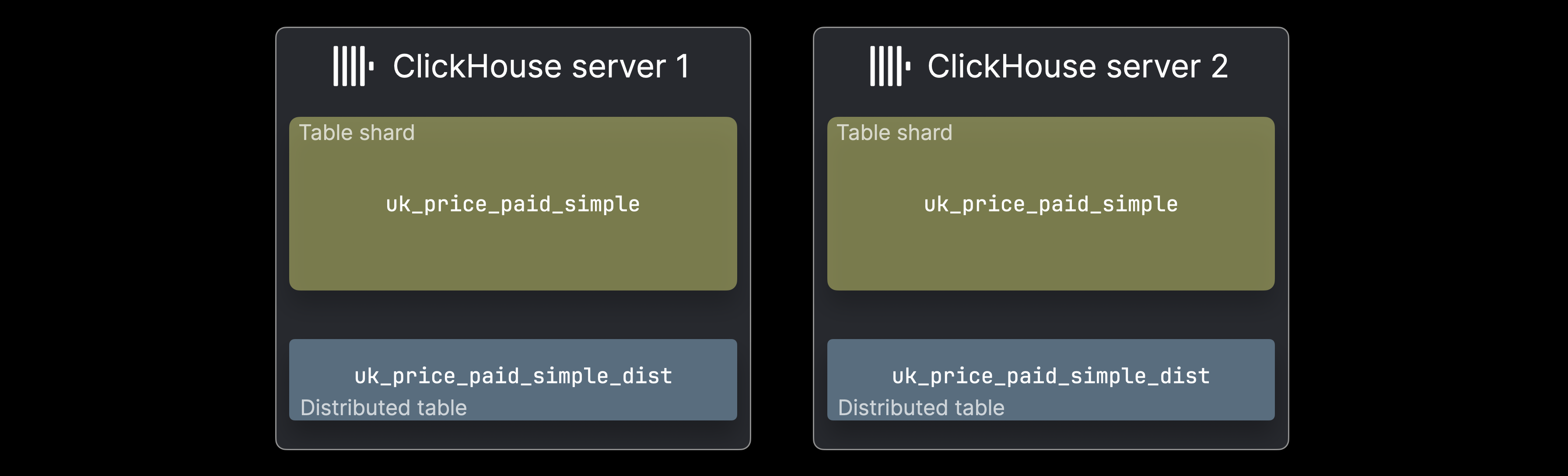
Каждый ^^шард^^ содержит подмножество данных и функционирует как обычная таблица ClickHouse, к которой можно выполнять запросы отдельно. Однако запросы будут обрабатывать только это подмножество, что может быть допустимым случаем в зависимости от распределения данных. Обычно, распределенная таблица (часто на сервер) предоставляет единый обзор полного набора данных. Она не хранит данные сама, но перенаправляет SELECT запросы ко всем шартам, собирает результаты и направляет INSERTS, чтобы равномерно распределить данные.
Создание распределенной таблицы
Чтобы проиллюстрировать перенаправление SELECT запросов и маршрутизацию INSERT, мы рассмотрим пример таблицы Что такое части таблиц, разделенной на два шарда на двух серверах ClickHouse. Сначала мы покажем DDL-инструкцию для создания соответствующей ^^распределенной таблицы^^ для этой конфигурации:
Клавиша ON CLUSTER делает DDL-инструкцию распределенной DDL-инструкцией, давая указание ClickHouse создать таблицу на всех серверах, указанных в определении кластера test_cluster определение кластера. Распределенный DDL требует дополнительного компонента Keeper в архитектуре кластера.
Для параметров распределенного движка мы указываем имя ^^кластера^^ (test_cluster), имя базы данных (uk) для шардированной целевой таблицы, имя шардированной целевой таблицы (uk_price_paid_simple) и ключ шардирования для маршрутизации INSERT. В этом примере мы используем функцию rand, чтобы случайным образом назначать строки шартам. Однако любое выражение — даже сложные — могут быть использованы в качестве ключа шардирования, в зависимости от случая использования. Следующий раздел иллюстрирует, как работает маршрутизация INSERT.
Маршрутизация INSERT
На диаграмме ниже показано, как обрабатываются INSERT в ^^распределенной таблице^^ в ClickHouse:
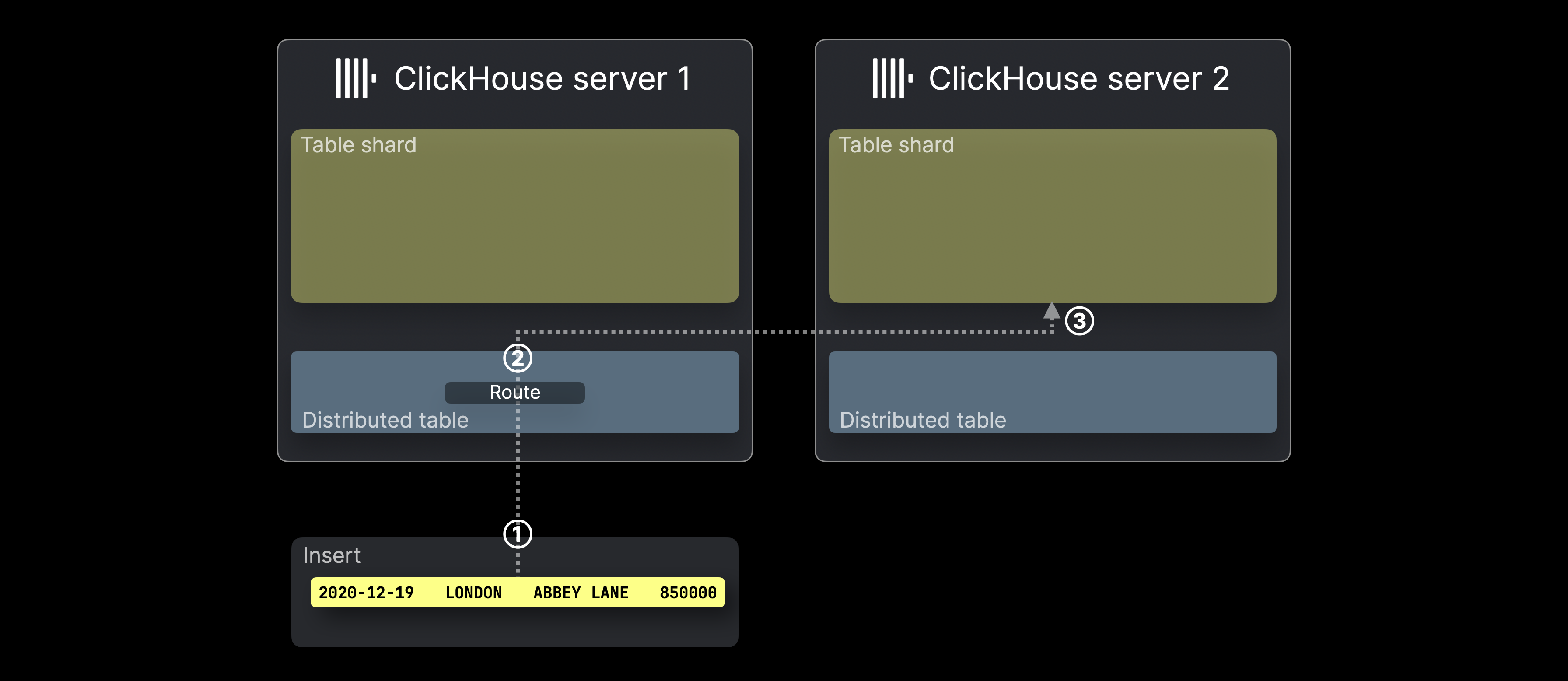
① INSERT (с одной строкой), нацеленный на ^^распределенную таблицу^^, отправляется на сервер ClickHouse, который хранит таблицу, либо напрямую, либо через балансировщик нагрузки.
② Для каждой строки из INSERT (в нашем примере только одна) ClickHouse оценивает ключ шардирования (в данном случае rand()), берет результат по модулю числа ^^шард^^ серверов и использует это в качестве идентификатора целевого сервера (идентификаторы начинаются с 0 и увеличиваются на 1). Строка затем перенаправляется и ③ вставляется в таблицу ^^шард^^ соответствующего сервера.
Следующий раздел объясняет, как работает перенаправление SELECT.
Перенаправление SELECT
Эта диаграмма показывает, как обрабатываются SELECT запросы с ^^распределенной таблицей^^ в ClickHouse:
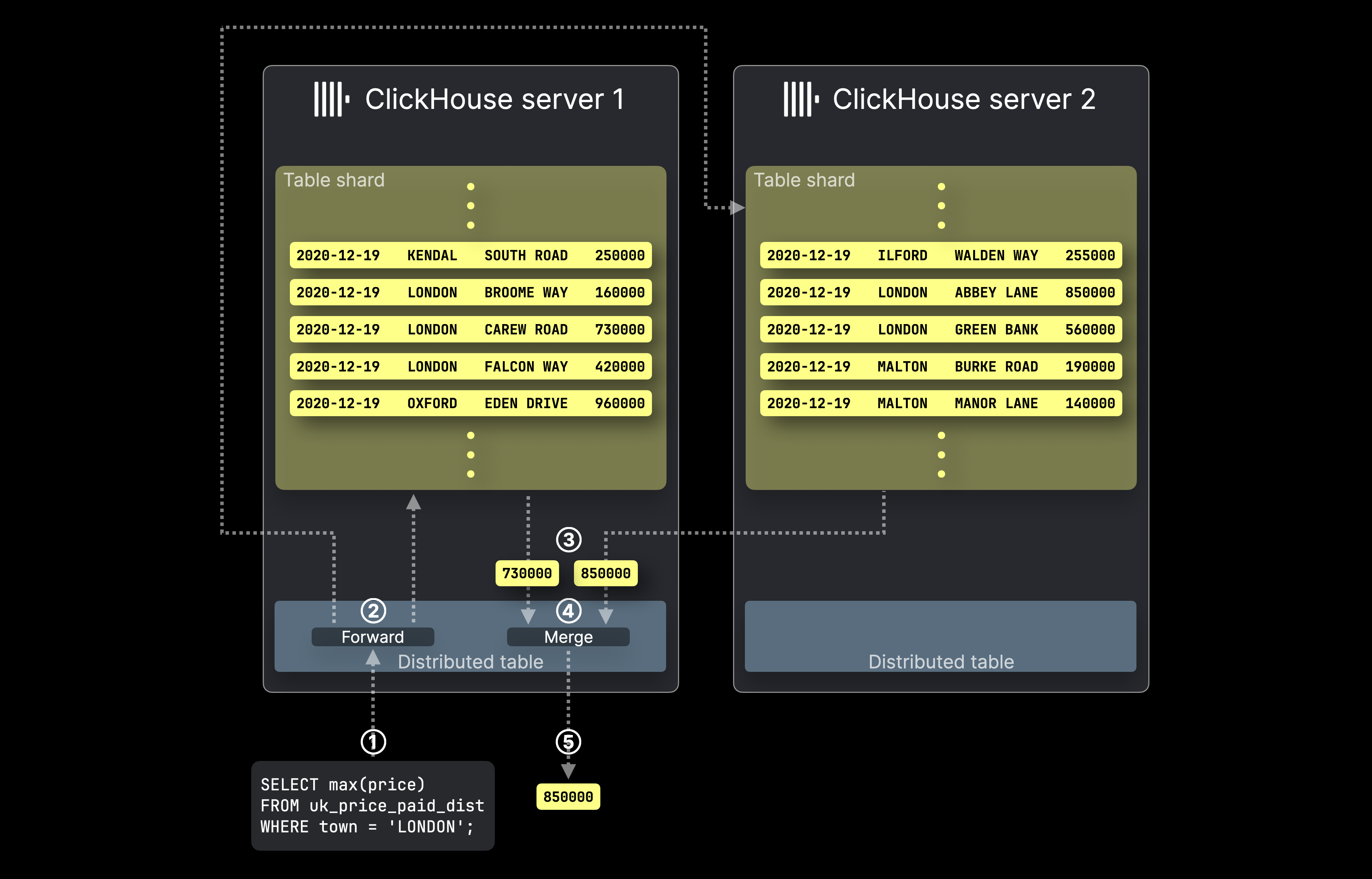
① Запрос агрегации SELECT, нацеленный на ^^распределенную таблицу^^, отправляется на соответствующий сервер ClickHouse, либо напрямую, либо через балансировщик нагрузки.
② ^^Распределенная таблица^^ перенаправляет запрос ко всем серверам, на которых находятся шарды целевой таблицы, где каждый сервер ClickHouse вычисляет свой локальный результат агрегации параллельно.
Затем сервер ClickHouse, который хранит изначально нацеленную ^^распределенную таблицу^^, ③ собирает все локальные результаты, ④ объединяет их в окончательный глобальный результат и ⑤ возвращает его отправителю запроса.
Что такое реплики таблиц в ClickHouse?
Репликация в ClickHouse обеспечивает целостность данных и переключение при сбоях, поддерживая копии данных ^^шард^^ на нескольких серверах. Поскольку аппаратные сбои неизбежны, репликация предотвращает потерю данных, обеспечивая, чтобы каждая ^^шард^^ имела несколько реплик. Записи могут направляться на любую ^^реплику^^, либо напрямую, либо через распределенную таблицу, которая выбирает ^^реплику^^ для операции. Изменения автоматически распространяются на другие реплики. В случае сбоя или обслуживания данные остаются доступными на других репликах, и как только сбойный сервер восстанавливается, он автоматически синхронизируется, чтобы оставаться актуальным.
Обратите внимание, что репликация требует компонента Keeper в архитектуре кластера.
Следующая диаграмма иллюстрирует кластер ClickHouse ^^с шестью серверами^^, где две ранее упомянутые таблицы-шарды Shard-1 и Shard-2 имеют по три реплики каждая. Запрос отправляется в этот ^^кластер^^:
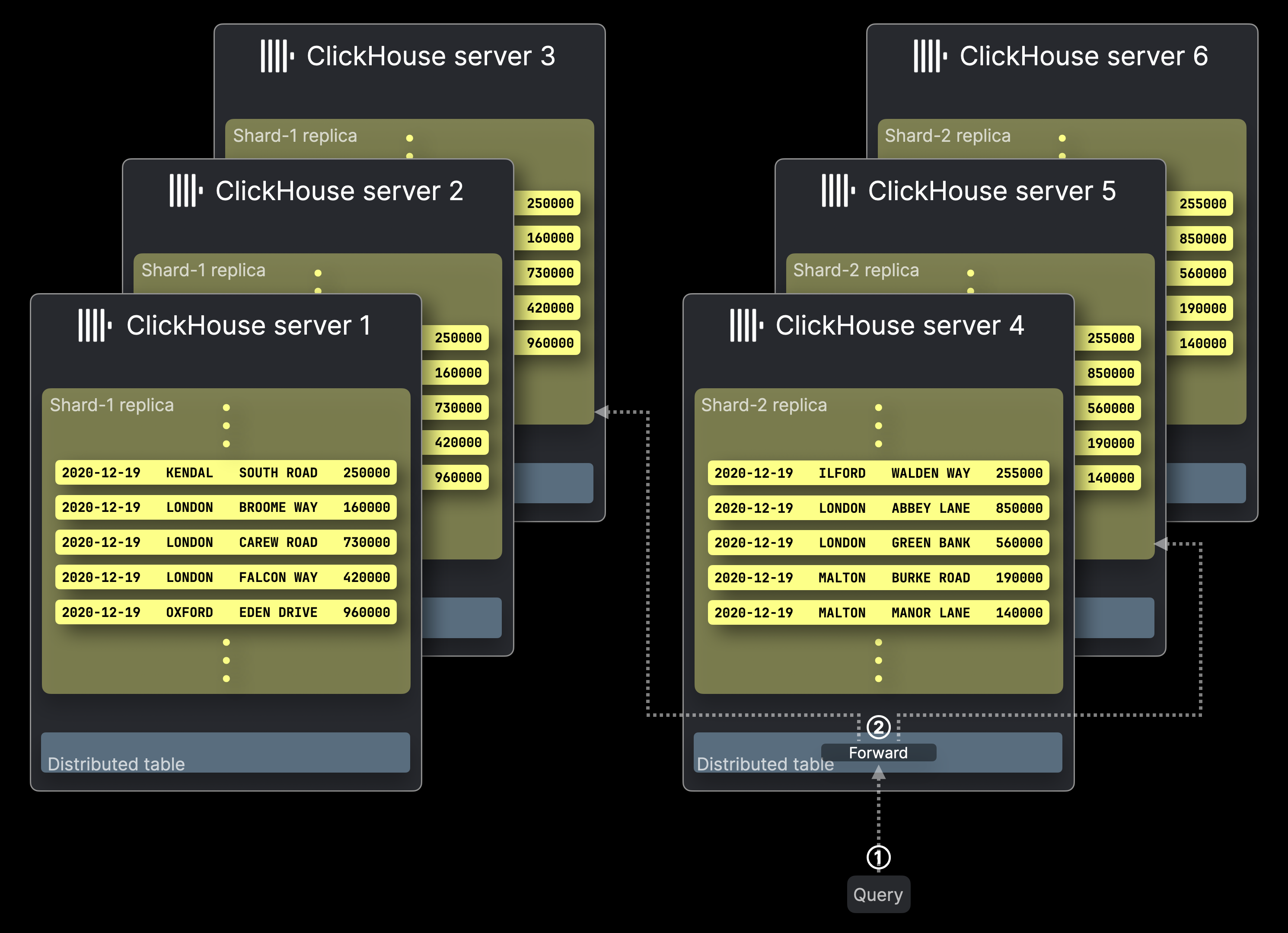
Обработка запросов работает аналогично конфигурациям без реплик, при этом всего лишь одна ^^реплика^^ из каждой ^^шард^^ выполняет запрос.
Реплики не только обеспечивают целостность данных и переключение при сбоях, но и улучшают пропускную способность обработки запросов, позволяя выполнять несколько запросов параллельно на разных репликах.
① Запрос, нацеленный на ^^распределенную таблицу^^, отправляется на соответствующий сервер ClickHouse, либо напрямую, либо через балансировщик нагрузки.
② ^^Распределенная таблица^^ перенаправляет запрос на одну ^^реплику^^ из каждой ^^шард^^, где каждый сервер ClickHouse, хранящий выбранную ^^реплику^^, вычисляет свой локальный результат запроса параллельно.
Дальше происходит то же самое, как в конфигурациях без реплик, и это не показано на диаграмме выше. Сервер ClickHouse, который хранит изначально нацеленную ^^распределенную таблицу^^, собирает все локальные результаты, объединяет их в окончательный глобальный результат и возвращает его отправителю запроса.
Обратите внимание, что ClickHouse позволяет настраивать стратегию перенаправления запросов для ②. По умолчанию—в отличие от диаграммы выше—^^распределенная таблица^^ предпочитает локальную ^^реплику^^, если таковая доступна, но могут быть использованы и другие стратегии балансировки нагрузки.
Где найти дополнительную информацию
Для более подробной информации помимо этого общего введения в шардынные таблицы и реплики, ознакомьтесь с нашим руководством по развертыванию и масштабированию.
Мы также настоятельно рекомендуем это обучающее видео для более глубокого изучения шардов и реплик ClickHouse:
