Изучение данных с помощью Jupyter notebooks и chDB
В этом руководстве вы узнаете, как исследовать набор данных в ClickHouse Cloud в Jupyter notebook с помощью chDB - быстрого SQL OLAP движка, работающего в процессе и основанного на ClickHouse.
Предварительные условия:
- виртуальная среда
- работающий сервис ClickHouse Cloud и ваши данные для подключения
Что вы узнаете:
- Подключение к ClickHouse Cloud из Jupyter notebooks с использованием chDB
- Запрос удаленных наборов данных и преобразование результатов в Pandas DataFrames
- Сочетание облачных данных с локальными CSV файлами для анализа
- Визуализация данных с помощью matplotlib
Мы будем использовать набор данных о ценах на недвижимость в Великобритании, который доступен в ClickHouse Cloud как один из стартовых наборов данных. Он содержит данные о ценах, по которым были проданы дома в Великобритании с 1995 по 2024 год.
Настройка
Чтобы добавить этот набор данных к существующему сервису ClickHouse Cloud, войдите в console.clickhouse.cloud с вашими учетными данными.
В левом меню нажмите на Источники данных. Затем нажмите Предопределенные образцы данных:
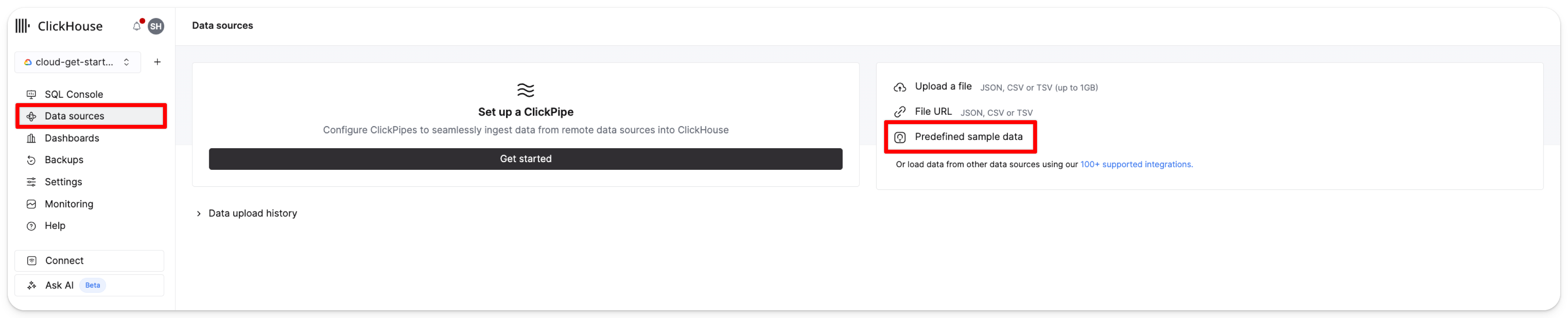
Выберите Начать в карточке данных о ценах на недвижимость в Великобритании (4GB):
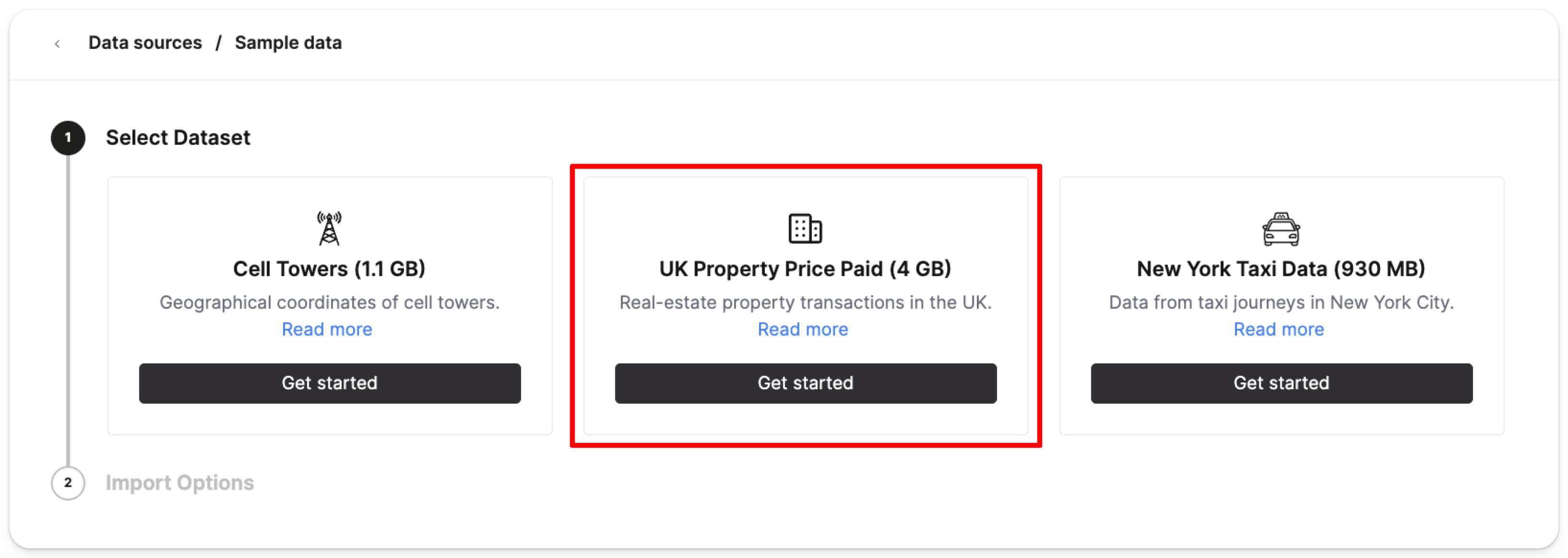
Затем нажмите Импортировать набор данных:
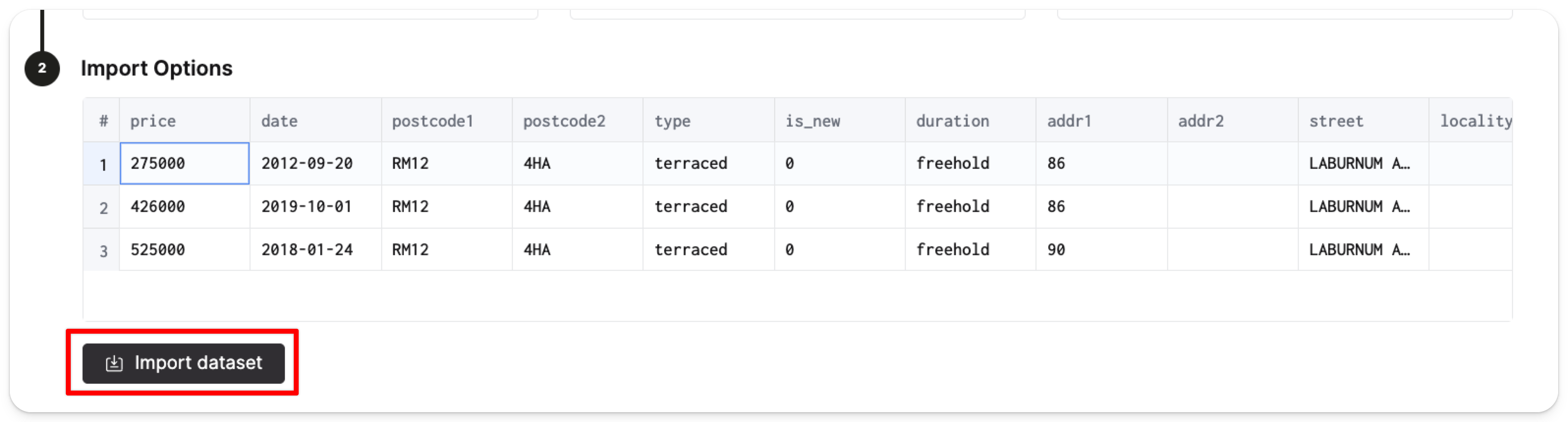
ClickHouse автоматически создаст таблицу pp_complete в базе данных default и заполнит таблицу 28.92 миллионами строк данных о ценах.
Чтобы уменьшить вероятность раскрытия ваших учетных данных, мы рекомендуем добавить ваше имя пользователя и пароль в облаке как переменные окружения на вашем локальном компьютере. В терминале выполните следующую команду, чтобы добавить свое имя пользователя и пароль как переменные окружения:
Переменные окружения выше сохраняются только на время вашей сессии терминала. Чтобы установить их постоянно, добавьте их в файл конфигурации вашего шелла.
Теперь активируйте вашу виртуальную среду. Из нее установите Jupyter Notebook с помощью следующей команды:
запустите Jupyter Notebook с помощью следующей команды:
В новом окне браузера должен открыться интерфейс Jupyter на localhost:8888.
Нажмите Файл > Новый > Notebook, чтобы создать новый Notebook.
Вам будет предложено выбрать ядро.
Выберите любое доступное ядро Python, в этом примере мы выберем ipykernel:
В пустой ячейке вы можете ввести следующую команду для установки chDB, используя который мы подключимся к нашему удаленному экземпляру ClickHouse Cloud:
Теперь вы можете импортировать chDB и выполнить простой запрос, чтобы убедиться, что все настроено правильно:
Изучение данных
С набором данных о ценах в Великобритании, настроенным и chDB, который работает в Jupyter notebook, мы можем начать изучение наших данных.
Представим, что мы заинтересованы в том, как цены изменялись со временем для конкретной области в Великобритании, такой как столица, Лондон.
Функция ClickHouse remoteSecure позволяет легко извлекать данные из ClickHouse Cloud.
Вы можете указать chDB вернуть эти данные в процессе в виде Pandas DataFrame - это удобный и привычный способ работы с данными.
Напишите следующий запрос, чтобы получить данные о ценах в Великобритании из вашего сервиса ClickHouse Cloud и преобразовать их в pandas.DataFrame:
В приведенном выше фрагменте chdb.query(query, "DataFrame") выполняет указанный запрос и выводит результат в терминал в виде Pandas DataFrame.
В запросе мы используем функцию remoteSecure для подключения к ClickHouse Cloud.
Функция remoteSecure принимает в качестве параметров:
- строку подключения
- имя базы данных и таблицы для использования
- ваше имя пользователя
- ваш пароль
В качестве лучшей практики безопасности, вам следует предпочитать использование переменных окружения для параметров имени пользователя и пароля, а не указывать их напрямую в функции, хотя это возможно, если вы хотите.
Функция remoteSecure подключается к удаленному сервису ClickHouse Cloud, выполняет запрос и возвращает результат.
В зависимости от размера ваших данных, это может занять несколько секунд.
В данном случае мы возвращаем среднюю цену за год и фильтруем по town='LONDON'.
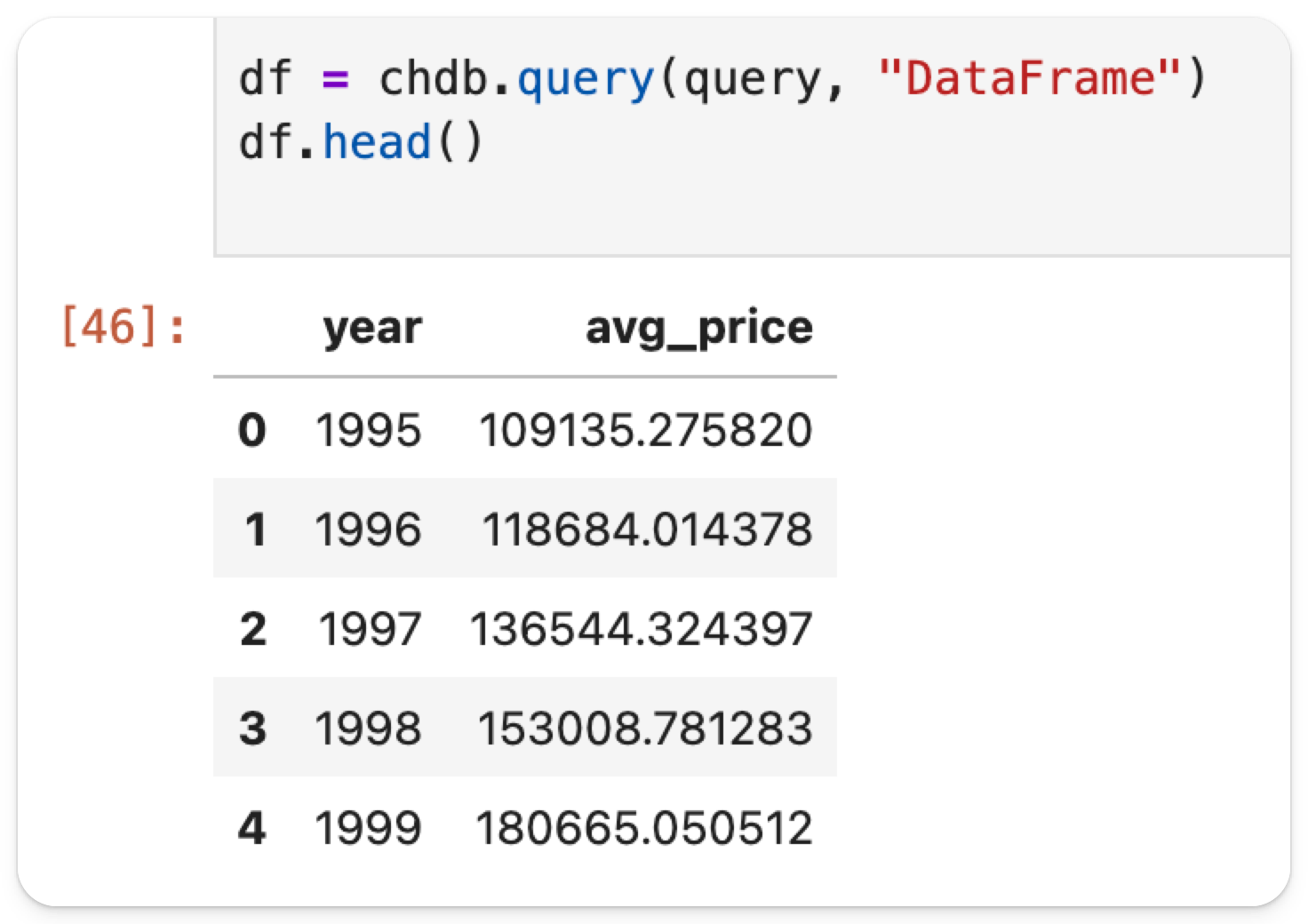
Результат затем хранится как DataFrame в переменной с именем df.
df.head отображает только первые несколько строк возвращенных данных:
Выполните следующую команду в новой ячейке, чтобы проверить типы столбцов:
Обратите внимание, что хотя date имеет тип Date в ClickHouse, в результате DataFrame он имеет тип uint16.
chDB автоматически определяет наиболее подходящий тип при возвращении DataFrame.
Учитывая, что данные теперь доступны в привычной форме, давайте исследуем, как изменялись цены на недвижимость в Лондоне со временем.
В новой ячейке выполните следующую команду, чтобы построить простой график времени против цены для Лондона с использованием matplotlib:
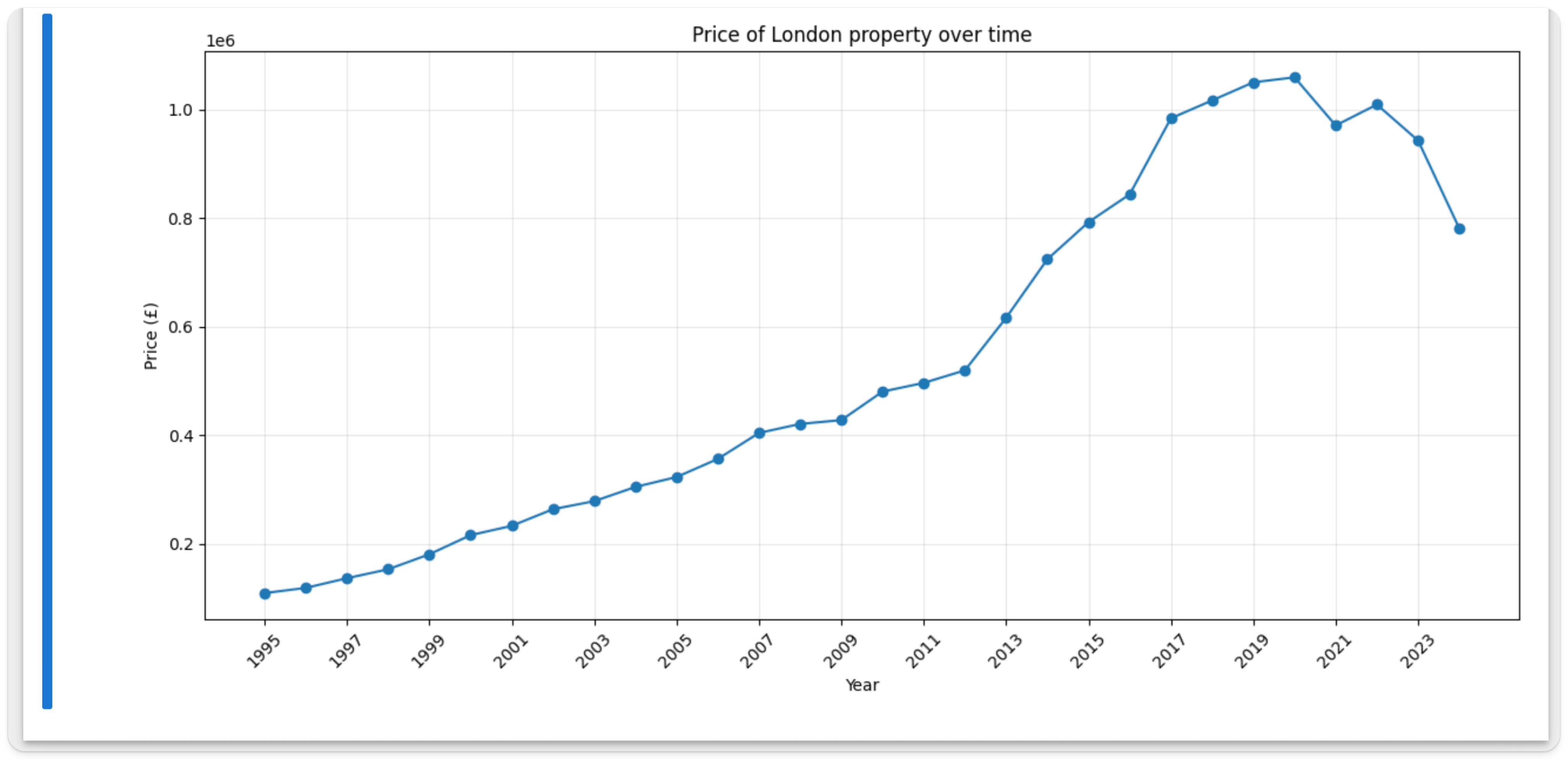
Возможно, это не удивительно, но цены на недвижимость в Лондоне существенно возросли со временем.
Другой ученый данных отправил нам файл .csv с дополнительными переменными, связанными с жильем, и интересуется, как число проданных домов в Лондоне изменялось со временем. Давайте построим некоторые из этих данных вместе с ценами на жилье и посмотрим, можем ли мы обнаружить какую-либо корреляцию.
Вы можете использовать движок таблицы file, чтобы читать файлы непосредственно на вашем локальном компьютере.
В новой ячейке выполните следующую команду, чтобы создать новый DataFrame из локального файла .csv.
Details
Чтение из нескольких источников за один шаг
Также возможно читать из нескольких источников за один шаг. Вы можете использовать приведенный ниже запрос сJOIN для этого: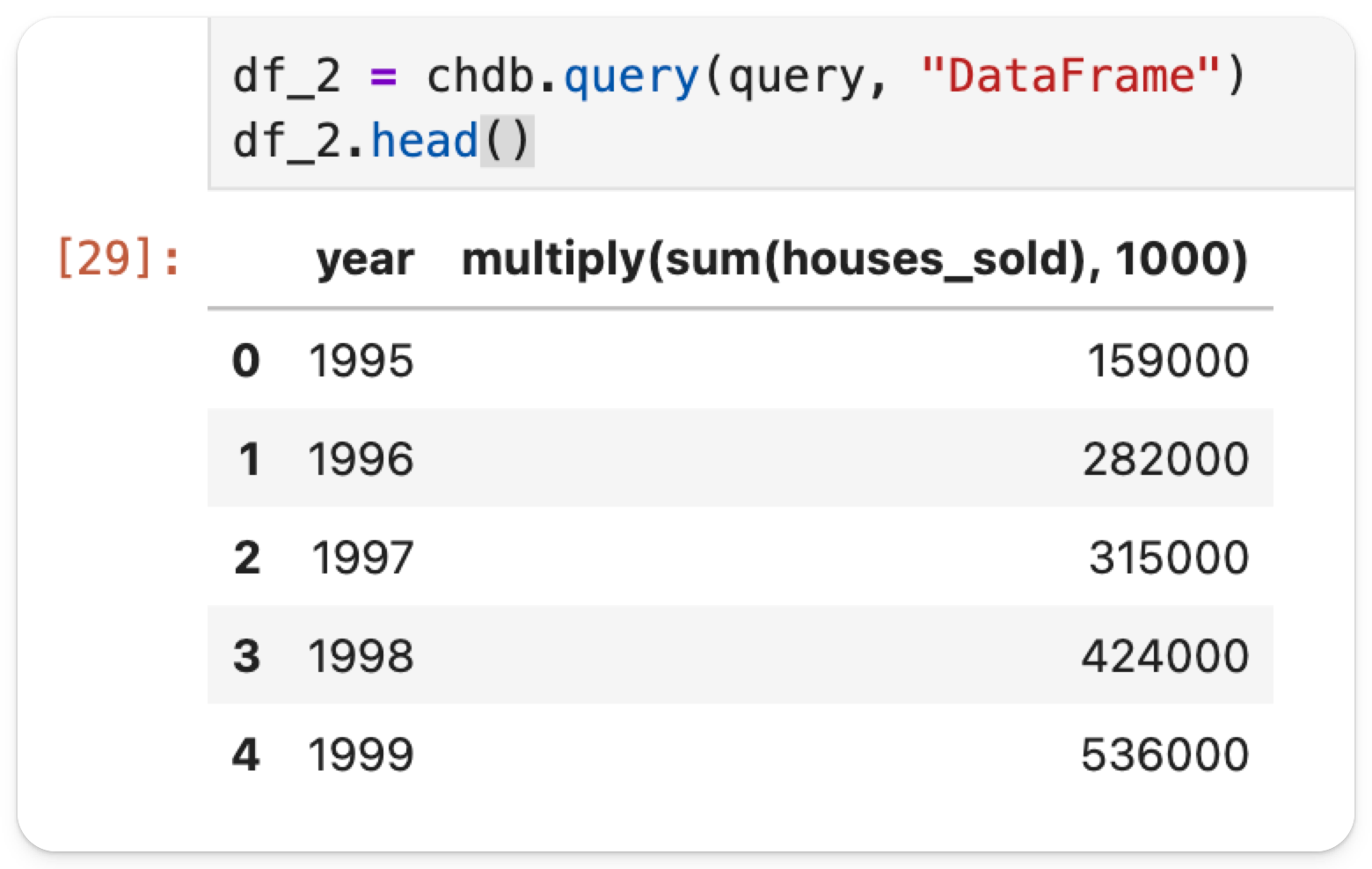
Хотя у нас нет данных с 2020 года и позже, мы можем сопоставить два набора данных друг с другом за годы с 1995 по 2019. В новой ячейке выполните следующую команду:
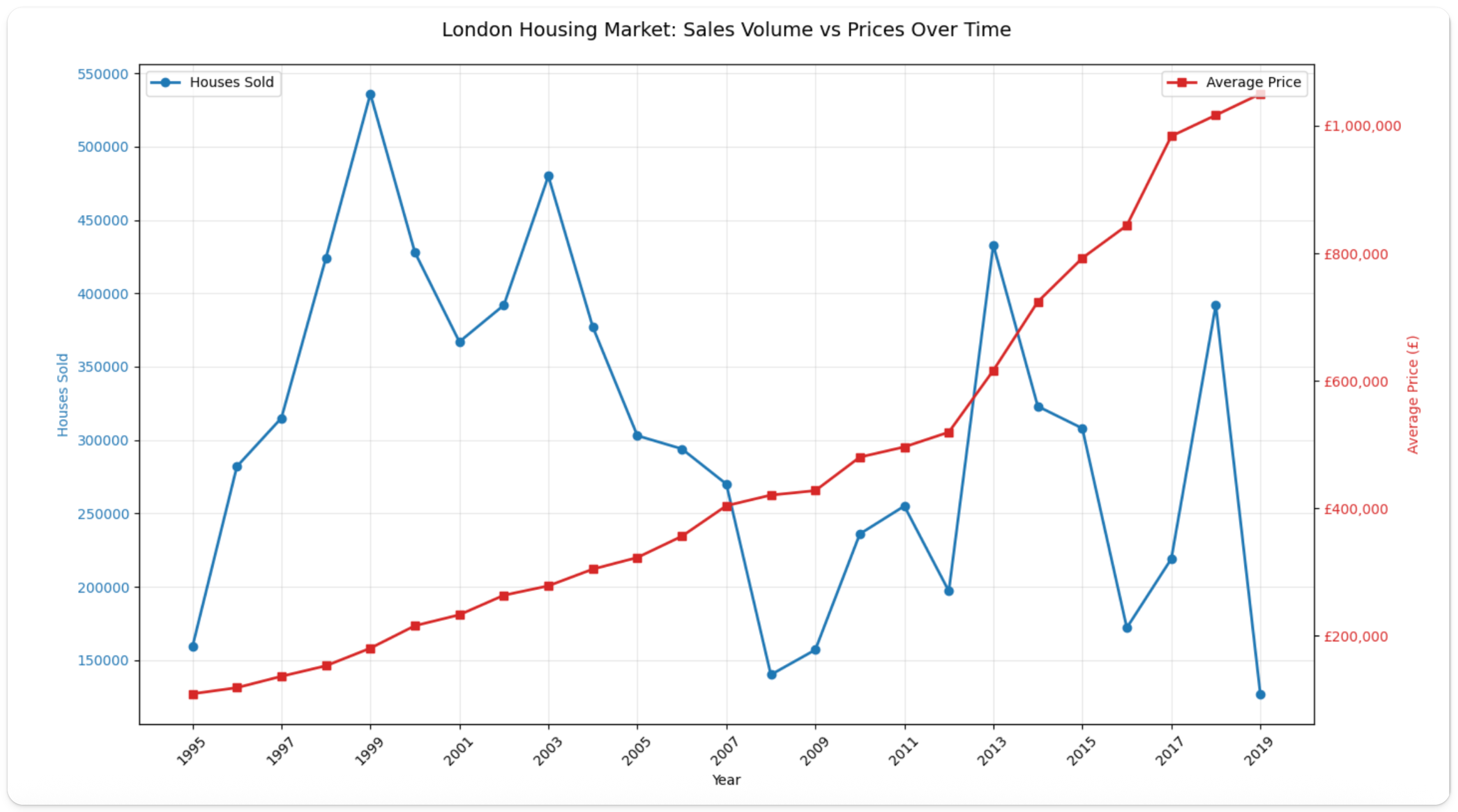
Из построенных данных мы видим, что продажи начались около 160,000 в 1995 году и быстро возросли, достигнув пика около 540,000 в 1999 году. После этого объемы резко сократились в середине 2000-х, сильно упав во время финансового кризиса 2007-2008 годов и упав до около 140,000. Цены, с другой стороны, показали стабильный, последовательный рост с примерно £150,000 в 1995 году до около £300,000 к 2005 году. Рост резко ускорился после 2012 года, резко поднявшись с примерно £400,000 до свыше £1,000,000 к 2019 году. В отличие от объема продаж, цены продемонстрировали минимальное влияние со стороны кризиса 2008 года и сохранили восходящую траекторию. Упс!
Резюме
Это руководство продемонстрировало, как chDB позволяет бесшовно исследовать данные в Jupyter notebooks, связывая ClickHouse Cloud с локальными источниками данных.
Используя набор данных о ценах на недвижимость в Великобритании, мы показали, как запрашивать удаленные данные ClickHouse Cloud с помощью функции remoteSecure(), читать локальные CSV файлы с помощью движка таблицы file(), и преобразовывать результаты напрямую в Pandas DataFrames для анализа и визуализации.
С помощью chDB, ученые данных могут использовать мощные SQL возможности ClickHouse наряду с привычными инструментами Python, такими как Pandas и matplotlib, что упрощает объединение нескольких источников данных для комплексного анализа.
Хотя многие ученые данных, базирующиеся в Лондоне, могут не иметь возможности вскоре позволить себе собственный дом или квартиру, по крайней мере, они могут анализировать рынок, который вынудил их покинуть!
