ClickStack OpenTelemetry Collector
Эта страница содержит детали настройки официального коллектора OpenTelemetry (OTel) для ClickStack.
Роли коллектора
Коллекторы OpenTelemetry могут быть развернуты в двух основных ролях:
-
Агент - Экземпляры агентов собирают данные на границе, например, на серверах или на узлах Kubernetes, или принимают события непосредственно от приложений, инструментированных с помощью OpenTelemetry SDK. В последнем случае экземпляр агента работает вместе с приложением или на том же хосте, что и приложение (например, как сайдкар или DaemonSet). Агенты могут отправлять свои данные напрямую в ClickHouse или на экземпляр шлюза. В первом случае это называется шаблоном развертывания агента.
-
Шлюз - Экземпляры шлюзов предоставляют отдельный сервис (например, развертывание в Kubernetes), как правило, на кластер, центр обработки данных или регион. Эти экземпляры принимают события от приложений (или других коллекторов в роли агентов) через единую точку доступа OTLP. Обычно развертывается набор экземпляров шлюзов, с использованием готового балансировщика нагрузки для распределения нагрузки между ними. Если все агенты и приложения отправляют свои сигналы на эту единую точку, это часто называется шаблоном развертывания шлюза.
Важно: Коллектор, включая стандартные сборки ClickStack, предполагает роль шлюза, описанную ниже, получая данные от агентов или SDK.
Пользователи, развертывающие OTel коллекторы в роли агента, обычно используют стандартное распределение коллектора contrib и не версию ClickStack, но могут свободно использовать другие совместимые с OTLP технологии, такие как Fluentd и Vector.
Развертывание коллектора
Если вы управляете своим собственным коллекторами OpenTelemetry в отдельном развертывании - например, при использовании только дистрибутива HyperDX - мы рекомендуем все же использовать официальное распределение ClickStack коллектора для роли шлюза, где это возможно, но если вы решите привнести свой, убедитесь, что он включает экспортер ClickHouse.
Отдельный
Чтобы развернуть распределение ClickStack OTel.connector в настольном режиме, выполните следующую команду docker:
Обратите внимание, что мы можем переопределить целевой экземпляр ClickHouse с помощью переменных окружения для CLICKHOUSE_ENDPOINT, CLICKHOUSE_USERNAME и CLICKHOUSE_PASSWORD. Значение CLICKHOUSE_ENDPOINT должно быть полным HTTP-адресом ClickHouse, включая протокол и порт—например, http://localhost:8123.
Эти переменные окружения могут быть использованы с любым из дистрибутивов docker, которые включают коннектор.
Значение OPAMP_SERVER_URL должно указывать на вашу развертку HyperDX - например, http://localhost:4320. HyperDX открывает сервер OpAMP (Open Agent Management Protocol) по адресу /v1/opamp на порту 4320 по умолчанию. Убедитесь, что этот порт открыт из контейнера, в котором работает HyperDX (например, с использованием -p 4320:4320).
Чтобы коллектор мог подключаться к порту OpAMP, он должен быть открыт контейнером HyperDX, например, -p 4320:4320. Для локального тестирования пользователи OSX могут установить OPAMP_SERVER_URL=http://host.docker.internal:4320. Пользователи Linux могут запустить контейнер коллектора с параметром --network=host.
Пользователи должны использовать пользователя с соответствующими учетными данными в продакшене.
Изменение конфигурации
Использование docker
Все образы docker, которые включают OpenTelemetry.collector, могут быть настроены для использования экземпляра ClickHouse с помощью переменных окружения OPAMP_SERVER_URL,CLICKHOUSE_ENDPOINT, CLICKHOUSE_USERNAME и CLICKHOUSE_PASSWORD:
Например, образ all-in-one:
Docker Compose
С Docker Compose измените конфигурацию коллектора с использованием тех же переменных окружения, как указано выше:
Расширенная конфигурация
В настоящее время ClickStack распределение OTel.collector не поддерживает изменение файла конфигурации. Если вам нужна более сложная конфигурация, например, настройка TLS или изменение размера пакета, мы рекомендуем скопировать и изменить стандартную конфигурацию и развернуть собственную версию OTel.collector, используя экспортер ClickHouse, задокументированный здесь и здесь.
Стандартная конфигурация ClickStack для коллектора OpenTelemetry (OTel) доступна здесь.
Структура конфигурации
Для деталей о конфигурации OTel.collectors, включая receivers, operators, и processors, мы рекомендуем официальную документацию коллектора OpenTelemetry.
Безопасность коллектора
Распределение ClickStack коллектора OpenTelemetry включает встроенную поддержку OpAMP (Open Agent Management Protocol), который используется для безопасной настройки и управления точкой доступа OTLP. При запуске пользователи должны предоставить переменную окружения OPAMP_SERVER_URL — она должна указывать на приложение HyperDX, которое хостит API OpAMP по адресу /v1/opamp.
Эта интеграция обеспечивает безопасность точки доступа OTLP, используя авто-сгенерированный ключ API для приема данных, созданный при развертывании приложения HyperDX. Все данные телеметрии, отправляемые в коллектор, должны включать этот ключ API для аутентификации. Вы можете найти ключ в приложении HyperDX в разделе Team Settings → API Keys.
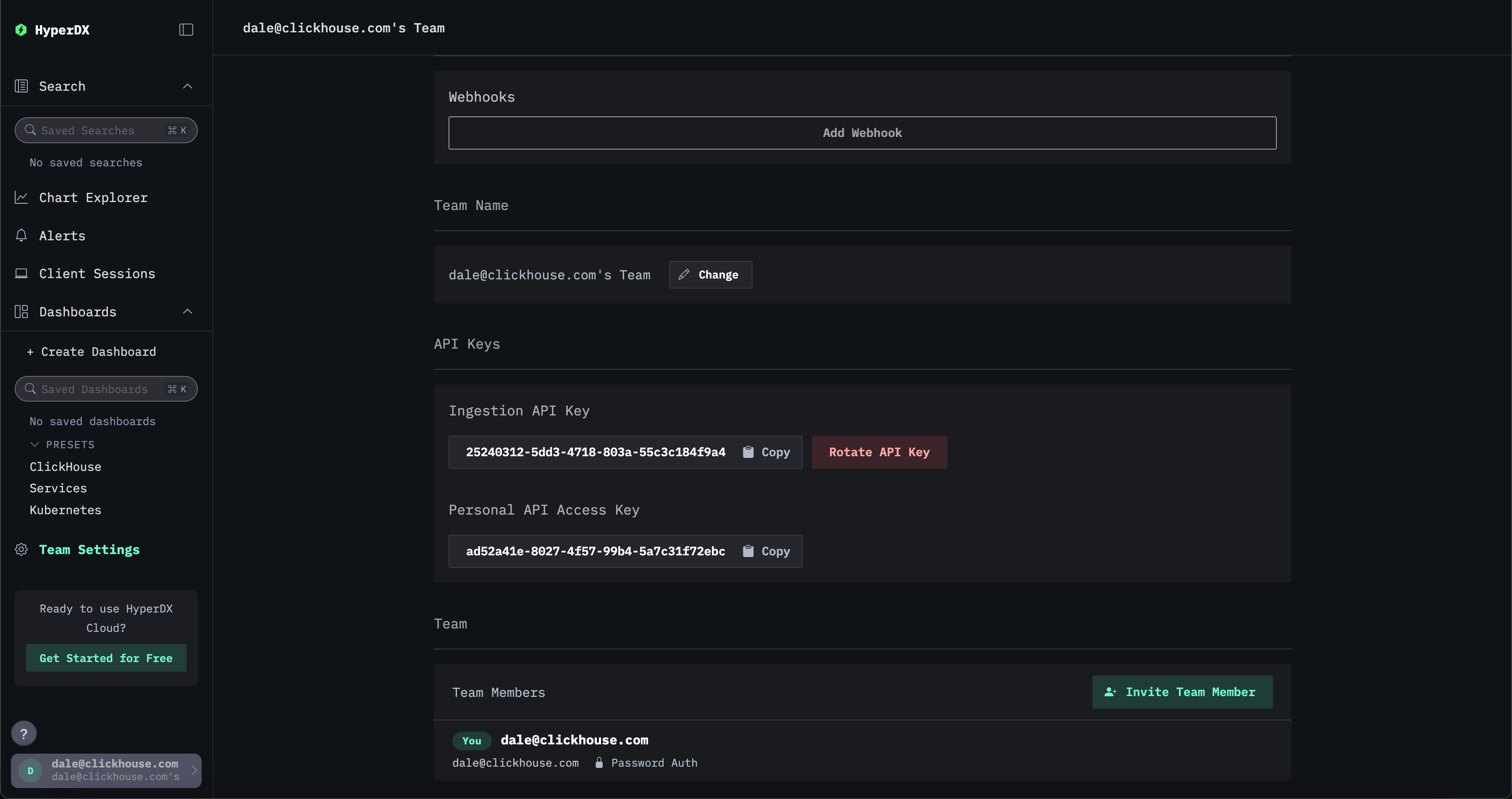
Чтобы дополнительно обезопасить ваше развертывание, мы рекомендуем:
- Настроить коллектор для связи с ClickHouse через HTTPS.
- Создать отдельного пользователя для приема данных с ограниченными правами - подробности ниже.
- Включить TLS для точки доступа OTLP, чтобы обеспечить шифрованную коммуникацию между SDK/агентами и коллектором. В настоящее время это требует от пользователей развертывания стандартного распределения коллектора и самостоятельного управления конфигурацией.
Создание пользователя для приема данных
Мы рекомендуем создать отдельную базу данных и пользователя для OTel.collector для приема данных в ClickHouse. У этого пользователя должны быть права на создание и вставку в таблицы, созданные и используемые ClickStack.
Это предполагает, что коллектор был настроен на использование базы данных otel. Это можно контролировать с помощью переменной окружения HYPERDX_OTEL_EXPORTER_CLICKHOUSE_DATABASE. Передайте это изображению, в котором размещен коллектор аналогично другим переменным окружения.
Обработка - фильтрация, преобразование и обогащение
Пользователи безусловно захотят фильтровать, преобразовывать и обогащать сообщения событий во время приема данных. Поскольку конфигурация для коннектора ClickStack не может быть изменена, мы рекомендуем пользователям, которым требуется дальнейшая фильтрация событий и обработка:
- Развернуть собственную версию OTel.collector, выполняющую фильтрацию и обработку, отправляя события в ClickStack коллектор через OTLP для приема в ClickHouse.
- Развернуть собственную версию OTel.collector и отправлять события напрямую в ClickHouse, используя экспортер ClickHouse.
Если обработка осуществляется с помощью OTel.collector, мы рекомендуем выполнять преобразования на экземплярах шлюзов и минимизировать любую работу, выполняемую на экземплярах агентов. Это гарантирует минимальные требования к ресурсам для агентов на границе, работающих на серверах. Обычно мы видим, что пользователи выполняют только фильтрацию (чтобы минимизировать ненужное сетевое использование), установку временных меток (через операторы) и обогащение, которое требует контекста в агентах. Например, если экземпляры шлюзов находятся в другом кластере Kubernetes, обогащение k8s необходимо проводить в агенте.
OpenTelemetry поддерживает следующие функции обработки и фильтрации, которые пользователи могут использовать:
-
Процессоры - Процессоры обрабатывают данные, собранные приемниками и модифицируют или преобразовывают их перед отправкой экспортерам. Процессоры применяются в порядке, указанном в разделе
processorsконфигурации коллектора. Эти элементы являются необязательными, но минимальный набор обычно рекомендуется. При использовании OTel.collector с ClickHouse мы рекомендуем ограничить количество процессоров до: -
memory_limiter используется для предотвращения ситуации с нехваткой памяти на коллекторе. См. Оценка ресурсов для рекомендаций.
-
Любой процессор, который выполняет обогащение на основе контекста. Например, Kubernetes Attributes Processor позволяет автоматически устанавливать атрибуты ресурсов для диапазонов, метрик и логов с метаданными k8s, например, обогащение событий их идентификатором Pod источника.
-
Требования к выборке с хвоста или начала, если они необходимы для трассировок.
-
Базовая фильтрация - Удаление событий, которые не требуются, если это нельзя сделать с помощью оператора (см. ниже).
-
Пакетирование - необходимо при работе с ClickHouse, чтобы убедиться, что данные отправляются пакетами. См. "Оптимизация вставок".
-
Операторы - Операторы предоставляют основную единицу обработки, доступную на приемнике. Поддерживается базовый анализ, позволяющий устанавливать поля такие, как степень и временная метка. Поддерживаются разбор JSON и регулярные выражения, а также фильтрация событий и базовые преобразования. Мы рекомендуем выполнять фильтрацию событий здесь.
Мы рекомендуем пользователям избегать чрезмерной обработки событий с помощью операторов или преобразовательных процессоров. Эти операции могут потреблять значительные ресурсы памяти и CPU, особенно при разборе JSON. Во многих случаях выполнять всю обработку можно в ClickHouse во время вставки с помощью материализованных представлений и колонок с некоторыми исключениями - в частности, контекстно-осознанным обогащением, например, добавлением метаданных k8s. Для получения более детальной информации смотрите Извлечение структуры с помощью SQL.
Пример
Следующая конфигурация показывает сборку неструктурированного лог-файла. Эта конфигурация может быть использована коллектором в роли агента, отправляющим данные в шлюз ClickStack.
Обратите внимание на использование операторов для извлечения структуры из лог строк (regex_parser) и фильтрации событий, а также на процессор для пакетирования событий и ограничения использования памяти.
Обратите внимание на необходимость включения заголовка авторизации, содержащего ваш ключ API приема данных в любой связи OTLP.
Для более сложной конфигурации мы предлагаем документацию по коллекторам OpenTelemetry.
Оптимизация вставок
Чтобы добиться высокой производительности вставки при получении сильных гарантий согласованности, пользователи должны следовать простым правилам при вставке данных наблюдаемости в ClickHouse через коллектор ClickStack. При правильной настройке OTel.collector следующие правила должны быть простыми для исполнения. Это также помогает избежать распространенных проблем, с которыми сталкиваются пользователи при первом использовании ClickHouse.
Пакетирование
По умолчанию каждая вставка, отправленная в ClickHouse, вызывает немедленное создание части хранилища, содержащей данные из вставки вместе с другой метаинформацией, которую необходимо сохранить. Таким образом, отправка меньшего количества вставок, каждая из которых содержит больше данных, по сравнению с отправкой большего количества вставок, каждая из которых содержит меньше данных, уменьшит количество необходимых записей. Мы рекомендуем вставлять данные довольно крупными пакетами, как минимум, по 1000 строк за раз. Дополнительные сведения здесь.
По умолчанию вставки в ClickHouse являются синхронными и идемпотентными, если они идентичны. Для таблиц, принадлежащих семейству движков merge tree, ClickHouse будет по умолчанию автоматически удалять дубликаты вставок. Это означает, что вставки являются толерантными в случаях, таких как следующие:
- (1) Если узел, получающий данные, имеет проблемы, запрос на вставку завершится по времени (или выдаст более конкретную ошибку) и не получит подтверждения.
- (2) Если данные были записаны узлом, но подтверждение не может быть возвращено отправителю запроса из-за сетевых перебоев, отправитель либо получит тайм-аут, либо сетевую ошибку.
С точки зрения коллектора (1) и (2) может быть трудно различить. Однако в обоих случаях неподтвержденная вставка может быть немедленно повторена. При условии, что повторный запрос вставки содержит те же данные в том же порядке, ClickHouse автоматически проигнорирует повторный запрос вставки, если оригинальная (неподтвержденная) вставка успешно выполнена.
По этой причине ClickStack распределение OTel.collector использует batch processor. Это гарантирует, что вставки отправляются как согласованные пакеты строк, удовлетворяющие указанным выше требованиям. Если ожидается, что коллектор будет иметь высокую пропускную способность (событий в секунду), и как минимум 5000 событий могут быть отправлены в каждой вставке, это обычно единственное пакетирование, требуемое в конвейере. В этом случае коллектор сбросит пакеты до достижения timeout процессора пакетирования, гарантируя, что задержка в конце конвейера остается низкой, а размеры пакетов - согласованными.
Использование асинхронных вставок
Как правило, пользователи вынуждены отправлять меньшие пакеты, когда пропускная способность коллектора низка, но они все равно ожидают, что данные достигнут ClickHouse с минимальной задержкой. В этом случае при истечении timeout процессора пакетирования отправляются небольшие пакеты. Это может вызвать проблемы и, когда требуется асинхронная вставка. Эта проблема возникает редко, если пользователи отправляют данные в коллектор ClickStack, который действует как шлюз - действуя как агрегаторы, они смягчают эту проблему - см. Роли коллектора.
Если обеспечить большие пакеты невозможно, пользователи могут делегировать пакетирование ClickHouse, используя асинхронные вставки. С асинхронными вставками данные сначала вставляются в буфер, а затем записываются в хранилище базы данных позже или асинхронно.
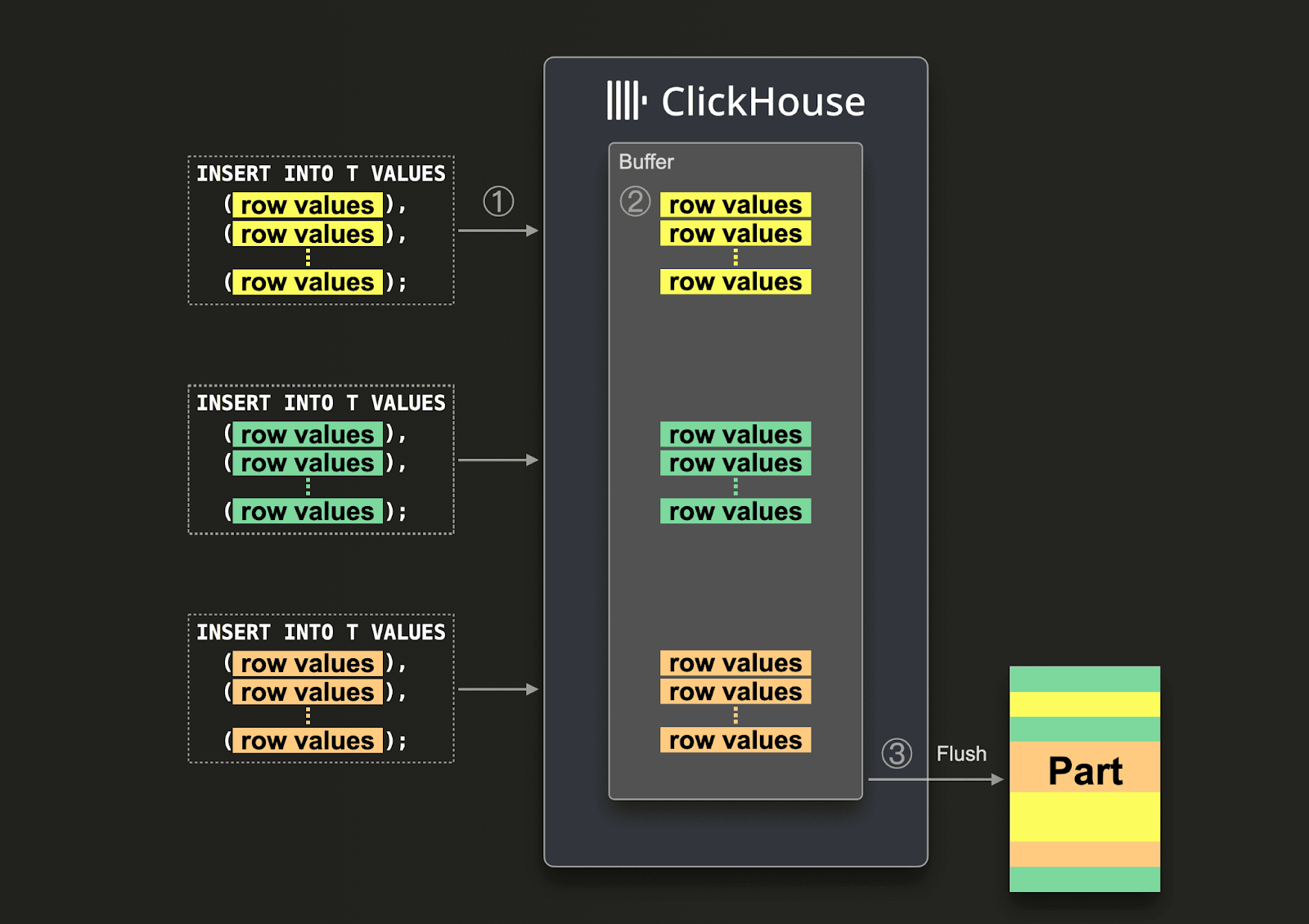
При включенных асинхронных вставках когда ClickHouse ① получает запрос на вставку, данные запроса ② немедленно записываются в буфер в оперативной памяти. Когда ③ происходит следующий сброс буфера, данные буфера сортируются [/guides/best-practices/sparse-primary-indexes#data-is-stored-on-disk-ordered-by-primary-key-columns] и записываются как часть в хранилище базы данных. Обратите внимание, что данные не могут быть ифицированы запросами, прежде чем они будут сброшены в БД; сброс буфера настраивается.
Чтобы включить асинхронные вставки для коллектора, добавьте async_insert=1 в строку подключения. Мы рекомендуем пользователям использовать wait_for_async_insert=1 (по умолчанию) для получения гарантий доставки - смотрите здесь для получения дополнительных подробностей.
Данные из асинхронной вставки вставляются после сброса буфера ClickHouse. Это происходит либо после превышения async_insert_max_data_size, либо после async_insert_busy_timeout_ms миллисекунд с момента первого запроса INSERT. Если async_insert_stale_timeout_ms установлен на ненулевое значение, данные вставляются после async_insert_stale_timeout_ms миллисекунд с момента последнего запроса. Пользователи могут настраивать эти параметры, чтобы контролировать задержку в конце своего конвейера. Дополнительные настройки, которые могут быть использованы для регулировки сброса буфера, задокументированы здесь. Как правило, значения по умолчанию являются адекватными.
В случаях, когда используется небольшое количество агентов с низкой пропускной способностью, но строгими требованиями к задержке, адаптивные асинхронные вставки могут быть полезными. Как правило, они не применяются в сценариях наблюдаемости с высоким уровнем пропускной способности, как видно на примере ClickHouse.
Наконец, предыдущее поведение дедупликации, связанное с синхронными вставками в ClickHouse, не включено по умолчанию при использовании асинхронных вставок. При необходимости смотрите настройку async_insert_deduplicate.
Полные детали конфигурации этой функции могут быть найдены на этой странице документации, или в глубоком блоге посте.
Масштабирование
Коллектор ClickStack OTel работает как экземпляр шлюза - см. Роли коллектора. Они предоставляют отдельный сервис, обычно на центр обработки данных или регион. Эти экземпляры принимают события от приложений (или других коллекторов в роли агентов) через единую точку доступа OTLP. Обычно развертывается набор экземпляров коллектора, с использованием готового балансировщика нагрузки для распределения нагрузки между ними.

Цель этой архитектуры - разгрузить ресурсоемкую обработку от агентов, минимизируя их потребление ресурсов. Эти шлюзы ClickStack могут выполнять преобразования, которые в противном случае потребовалось бы выполнять агентам. Более того, агрегируя события от многочисленных агентов, шлюзы могут гарантировать, что большие пакеты отправляются в ClickHouse - что позволяет эффективно вставлять данные. Эти коллекторы-шлюзы могут легко масштабироваться, поскольку в них добавляются новые агенты и источники SDK, и увеличивается пропускная способность событий.
Добавление Kafka
Читатели могут заметить, что вышеуказанные архитектуры не используют Kafka в качестве очереди сообщений.
Использование очереди Kafka в качестве буфера сообщений - это популярный шаблон проектирования, используемый в архитектурах логирования, который был популяризирован стеком ELK. Он предоставляет несколько преимуществ: в первую очередь, он помогает обеспечить более сильные гарантии доставки сообщений и помогает справляться с обратным давлением. Сообщения отправляются от агентов сбора в Kafka и записываются на диск. В теории кластеризованный экземпляр Kafka должен обеспечивать высокую пропускную способность буфера сообщений, поскольку он несет меньшие вычислительные затраты на запись данных линейно на диск, чем на разбор и обработку сообщения. Например, в Elastic токенизация и индексирование создают значительные накладные расходы. Перемещая данные от агентов, вы также уменьшаете риск потери сообщений в результате ротации логов на источнике. Наконец, он предлагает некоторые возможности репликации сообщений и межрегиональной репликации, которые могут быть привлекательны для некоторых сценариев использования.
Тем не менее, ClickHouse может обрабатывать вставку данных очень быстро - миллионы строк в секунду на среднем оборудовании. Обратное давление со стороны ClickHouse редко наблюдается. Часто использование очереди Kafka означает увеличение архитектурной сложности и затрат. Если вы можете принять принцип, что логи не требуют тех же гарантий доставки, что транзакции в банке и другие критические данные, мы рекомендуем избегать сложности Kafka.
Однако, если вам требуются высокие гарантии доставки или возможность воспроизведения данных (возможно, для нескольких источников), Kafka может быть полезным архитектурным дополнением.
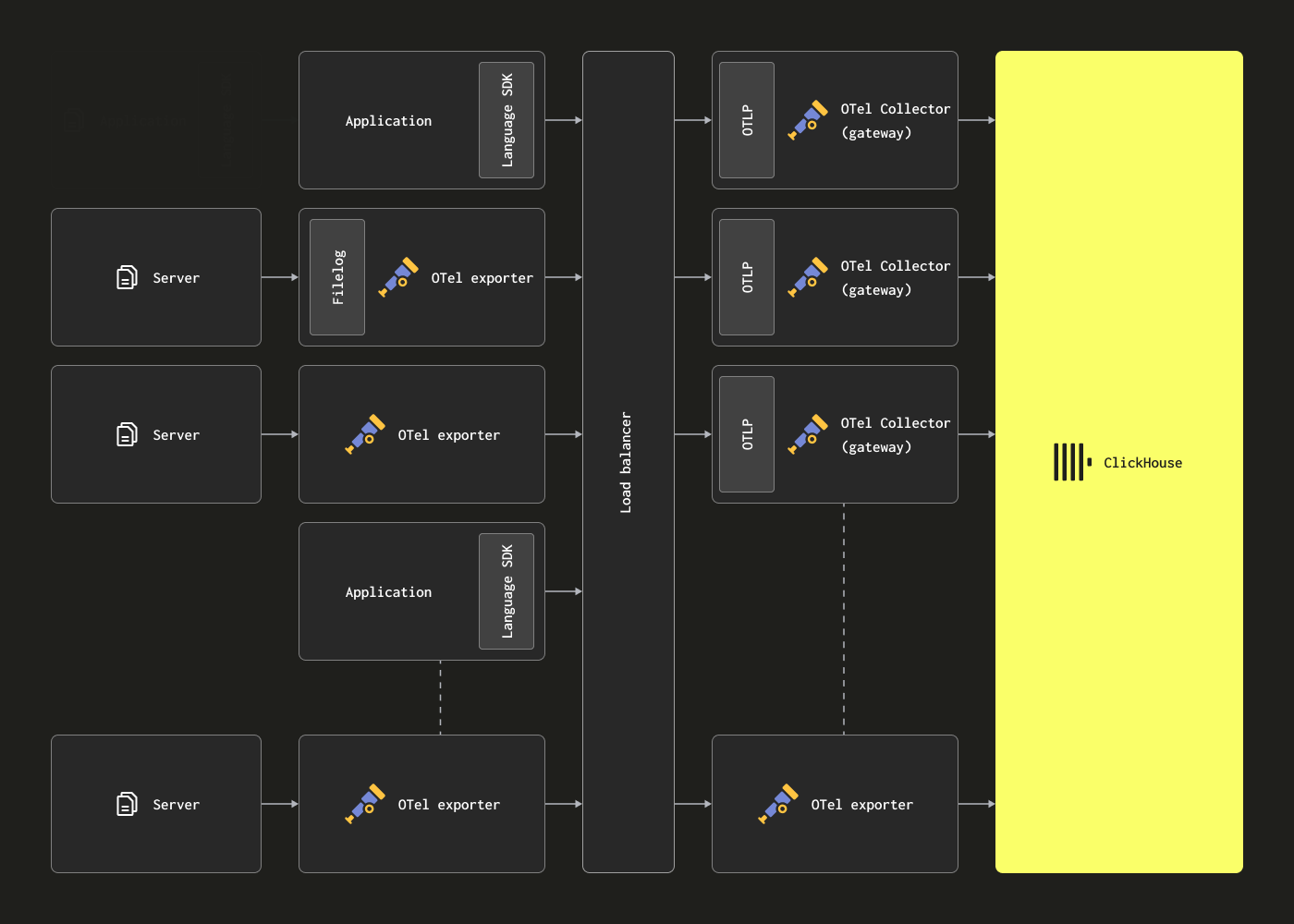
В этом случае агенты OTel могут быть настроены для отправки данных в Kafka через экспортер Kafka. Экземпляры шлюза, в свою очередь, принимают сообщения, используя приемник Kafka. Мы рекомендуем документацию Confluent и OTel для получения дополнительной информации.
Распределение ClickStack OpenTelemetry коллектора не может быть использовано с Kafka, поскольку это требует изменения конфигурации. Пользователи будут вынуждены развернуть стандартный OTel.collector с использованием экспортёра ClickHouse.
Оценка ресурсов
Требования к ресурсам для OTel.collector будут зависеть от пропускной способности событий, размера сообщений и объема выполняемой обработки. Проект OpenTelemetry поддерживает бенчмарки, которые пользователи могут использовать для оценки ресурсоемкости.
По нашему опыту, экземпляр шлюза ClickStack с 3 ядрами и 12 ГБ ОЗУ может обработать около 60 000 событий в секунду. Это предполагает минимальную обработку на трубопроводе, ответственной за переименование полей и отсутствие регулярных выражений.
Для экземпляров агентов, отвечающих за отправку событий в шлюз, и лишь устанавливающих временную метку на событие, мы рекомендуем пользователям ориентироваться по предполагаемым логам в секунду. Следующие значения представляют собой приблизительные цифры, которые пользователи могут использовать в качестве отправной точки:
| Скорость логирования | Ресурсы для коллектора агента |
|---|---|
| 1k/секунду | 0.2CPU, 0.2GiB |
| 5k/секунду | 0.5 CPU, 0.5GiB |
| 10k/секунду | 1 CPU, 1GiB |
Поддержка JSON
ClickStack имеет бета-версию поддержки типа JSON с версии 2.0.4.
Преимущества типа JSON
Тип JSON предлагает следующие преимущества пользователям ClickStack:
- Сохранение типа - Числа остаются числами, логические значения остаются логическими — больше не требуется преобразовывать всё в строки. Это означает меньше преобразований, более простые запросы и более точную агрегацию.
- Столбцы на уровне пути - Каждый JSON путь становится своим собственным подстолбцом, уменьшая ввод/вывод. Запросы читают только необходимые поля, обеспечивая значительное увеличение производительности по сравнению со старым типом Map, который требовал прочитать целый столбец, чтобы запросить конкретное поле.
- Глубокая вложенность работает без проблем - Естественно обрабатывать сложные, глубоко вложенные структуры без ручного упрощения (как это требует тип Map) и последующих ненужных функций JSONExtract.
- Динамические, развивающиеся схемы - Идеально подходит для данных наблюдаемости, где команды добавляют новые теги и атрибуты с течением времени. JSON автоматически обрабатывает эти изменения, без необходимости миграции схем.
- Быстрее запросы, меньше памяти - Типичные агрегации по атрибутам, таким как
LogAttributes, показывают на 5–10 раз меньше считываемых данных и резкое увеличение скорости, сокращая как время выполнения запроса, так и пиковое использование памяти. - Простое управление - Нет необходимости предварительно материализовать столбцы для достижения производительности. Каждое поле становится своим собственным подстолбцом, обеспечивая ту же скорость, что и родные столбцы ClickHouse.
Включение поддержки JSON
Чтобы включить эту поддержку для коллектора, установите переменную окружения OTEL_AGENT_FEATURE_GATE_ARG='--feature-gates=clickhouse.json' на любом развертывании, которое включает коллектор. Это гарантирует, что схемы создаются в ClickHouse с использованием типа JSON.
Чтобы запросить тип JSON, поддержка также должна быть включена в слое приложения HyperDX через переменную окружения BETA_CH_OTEL_JSON_SCHEMA_ENABLED=true.
Например:
Миграция от схем на основе карты к типу JSON
Тип JSON не является обратно совместимым с существующими схемами, основанными на картах. Новые таблицы будут создаваться с использованием типа JSON.
Для миграции от схем, основанных на картах, выполните следующие шаги:
Остановите OTel.collector
Переименуйте существующие таблицы и обновите источники
Переименуйте существующие таблицы и обновите источники данных в HyperDX.
Например:
Разверните коллектор
Разверните коллектор с установленной переменной OTEL_AGENT_FEATURE_GATE_ARG.
Перезапустите контейнер HyperDX с поддержкой схемы JSON
Создайте новые источники данных
Создайте новые источники данных в HyperDX, указывающие на таблицы JSON.
Миграция существующих данных (необязательно)
Чтобы переместить старые данные в новые таблицы JSON:
Рекомендуется только для наборов данных меньше ~10 миллиардов строк. Данные, ранее сохраненные с типом Map, не сохраняли точность типов (все значения были строками). В результате эти старые данные будут отображаться как строки в новой схеме, пока они не будут устаревшими, требуя некоторого приведения типов на фронтенде. Тип для новых данных будет сохранен с типом JSON.
